Как спланировать ресурсы для виртуальных машин: CPU, RAM, хранилище
Знакомая ситуация: купили мощный сервер, развернули виртуальные машины, а через месяц половина ресурсов простаивает, зато пользователи жалуются на медленную работу. Или наоборот — экономили на железе, а теперь каждое новое приложение превращается в лотерею: запустится или система рухнет от нехватки ресурсов.
Проблема не в том, что современные гипервизоры плохо управляют ресурсами. Наоборот — они научились творить чудеса, выжимая максимум из доступного железа. Проблема в том, что планирование ресурсов вм превратилось в сложную инженерную задачу, где нужно учитывать десятки факторов: от паттернов нагрузки приложений до особенностей конкретного гипервизора.
Неправильное планирование ресурсов виртуальных машин приводит не только к финансовым потерям. Пользователи теряют продуктивность из-за медленной работы систем, администраторы тратят время на постоянное тушение пожаров, а бизнес упускает возможности из-за неспособности IT-инфраструктуры справляться с нагрузкой.
Современные решения требуют комплексного подхода к планированию ресурсов с самого начала проектирования виртуальной инфраструктуры. Правильно подобранный сервер виртуальных машин — это только основа, на которой строится эффективная система распределения ресурсов.
Философия ресурсного планирования
Виртуализация создает иллюзию неограниченных ресурсов, но физические ограничения никуда не исчезают. Более того, гипервизор сам потребляет часть ресурсов сервера, а механизмы виртуализации добавляют небольшие накладные расходы к каждой операции.
Принцип разумного overcommit
Ключевая идея виртуализации — возможность выделить виртуальным машинам больше ресурсов, чем физически доступно на сервере. Это работает потому, что большинство приложений используют ресурсы неравномерно — пики нагрузки у разных систем редко совпадают по времени.
Однако overcommit требует глубокого понимания workload'ов. База данных с постоянной нагрузкой и веб-сервер с пиками активности в рабочее время имеют кардинально разные профили потребления ресурсов. Размещение их на одном хосте может быть как оптимальным решением, так и рецептом катастрофы.
Статистический анализ нагрузки помогает найти оптимальный коэффициент overcommit. Наблюдение за реальным потреблением ресурсов в течение месяца дает более точную картину, чем теоретические расчеты на основе пиковых значений.
Планирование на перспективу
Инфраструктура виртуализации должна учитывать не только текущие потребности, но и планы развития бизнеса. Сервер, загруженный на 90% в день внедрения, не оставляет места для роста и может стать узким местом уже через полгода.
Правило 70% — неплохая отправная точка для планирования. Если при пиковой нагрузке ресурсы сервера используются более чем на 70%, пора задуматься о расширении или перераспределении нагрузки.
Модульность расширения должна закладываться в архитектуру с самого начала. Лучше начать с двух менее мощных серверов, чем с одного топового — это даст больше гибкости в будущем.
Процессорные ресурсы: искусство распределения
CPU — наиболее сложный для планирования ресурс, поскольку его эффективное использование зависит от множества факторов: от типа приложений до архитектуры процессора.
vCPU vs физические ядра
Современные гипервизоры позволяют выделить виртуальной машине больше виртуальных процессоров (vCPU), чем физических ядер на сервере. Это работает благодаря тому, что большинство приложений не загружают все выделенные им процессоры постоянно.
Коэффициент 4:1 (четыре vCPU на одно физическое ядро) считается безопасным для большинства офисных приложений. Для серверов баз данных или вычислительных задач лучше придерживаться соотношения 1:1 или 2:1.
Hyperthreading увеличивает количество логических процессоров, но не удваивает вычислительную мощность. При планировании стоит считать каждый поток HT как 0,5-0,7 физического ядра, в зависимости от типа нагрузки.
NUMA-топология
На многопроцессорных серверах размещение виртуальных машин должно учитывать NUMA-архитектуру. Доступ к "удаленной" памяти других процессоров медленнее, чем к локальной, что может значительно влиять на производительность.
Размер виртуальной машины не должен превышать ресурсы одного NUMA-узла, если это возможно. Лучше создать две ВМ по 8 ядер, чем одну на 16 ядер, если в сервере два процессора по 8 ядер каждый.
Современные гипервизоры умеют автоматически размещать ВМ с учетом NUMA-топологии, но ручная настройка часто дает лучшие результаты для критически важных приложений.
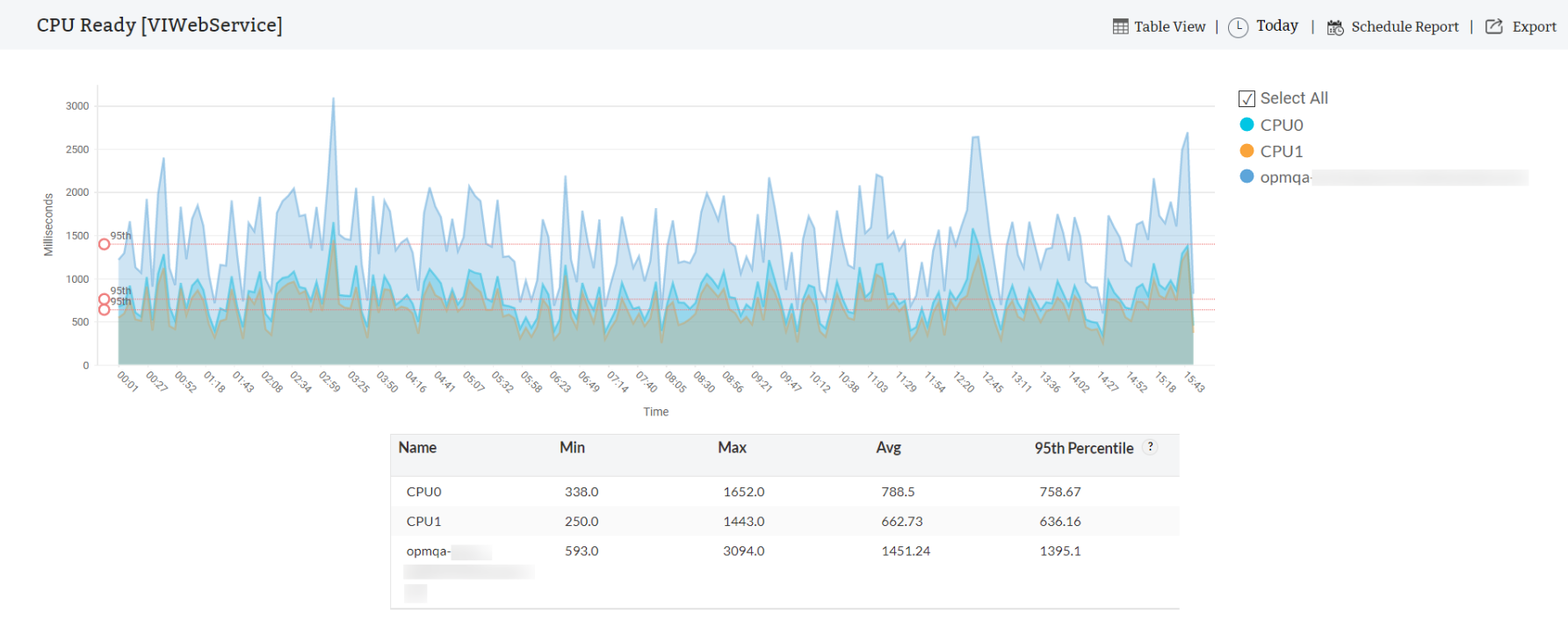
CPU ready time
Метрика CPU ready time показывает, сколько времени виртуальная машина ждала доступа к физическим ядрам процессора. Высокие значения указывают на перегрузку CPU подсистемы и необходимость перераспределения нагрузки.
Значения CPU ready time выше 5% для критически важных приложений требуют внимания. Для некритичных систем допустимы значения до 10-15%.
Планирование памяти: критический ресурс
ОЗУ — наименее терпимый к overcommit ресурс. Нехватка памяти приводит к использованию swap-файлов, что кардинально снижает производительность всех виртуальных машин на хосте.
Стратегии распределения памяти
Статическое выделение памяти гарантирует, что виртуальная машина всегда будет иметь доступ к назначенному объему ОЗУ. Это обеспечивает предсказуемую производительность, но снижает эффективность использования ресурсов.
Динамическое выделение позволяет гипервизору перераспределять неиспользуемую память между виртуальными машинами. Технологии ballooning, memory compression и deduplication помогают разместить больше ВМ на одном хосте.
Memory overcommit коэффициент 1.5:1 считается безопасным для большинства сред. То есть на сервере с 64 ГБ ОЗУ можно разместить виртуальные машины с суммарным объемом выделенной памяти 96 ГБ.
Особенности различных типов приложений
Базы данных обычно используют всю выделенную им память для кэширования, поэтому overcommit для них нежелателен. Лучше выделить меньше памяти, но гарантированно.
Веб-серверы и серверы приложений часто потребляют память неравномерно — больше в пиковые часы, меньше ночью. Для них умеренный overcommit может быть оправдан.
Файловые серверы активно используют память операционной системы для кэширования файлов. Выделение им "лишней" памяти часто положительно влияет на общую производительность системы.
Резерв для гипервизора
Сам гипервизор потребляет память для своих нужд: управления виртуальными машинами, кэширования метаданных, сетевой подсистемы. Обычно требуется зарезервировать 2-4 ГБ для нужд хоста плюс небольшой процент от общего объема памяти.
Функции высокой доступности, такие как vSphere HA, требуют дополнительного резерва памяти для возможности перезапуска виртуальных машин с отказавших хостов.
Планирование хранилища: баланс производительности и объема
Дисковая подсистема часто становится узким местом виртуализованных сред из-за концентрации множества workload'ов на одном хранилище.
IOPS vs пропускная способность
Различные приложения предъявляют разные требования к дисковой подсистеме. Базы данных нуждаются в высоких IOPS для обработки множества мелких запросов. Файловые серверы требуют высокой пропускной способности для передачи больших файлов.
SSD диски кардинально изменили планирование дисковых ресурсов. Там, где раньше требовалось десять HDD в RAID для обеспечения нужных IOPS, теперь достаточно одного SSD.
Тонкое провизионирование (thin provisioning) позволяет выделить виртуальным машинам больше дискового пространства, чем физически доступно. Это работает, пока суммарное реальное потребление не превышает физический объем.
Иерархия хранения
Автоматическое размещение данных по уровням хранения (storage tiering) оптимизирует использование дорогих SSD и дешевых HDD. Часто используемые данные автоматически мигрируют на быстрые диски, редко используемые — на медленные.
Кэширование с помощью SSD ускоряет работу с данными, хранящимися на традиционных дисках. Небольшой SSD-кэш может значительно улучшить производительность больших HDD-массивов.
Планирование роста
Дисковое пространство должно планироваться с большим запасом. Заполнение хранилища выше 80% может привести к фрагментации и снижению производительности.
Snapshot'ы и резервные копии потребляют дополнительное место. При использовании технологий моментальных снимков нужно резервировать 20-30% дискового пространства для их хранения.
Сетевые ресурсы и планирование
Сетевая подсистема редко становится узким местом в небольших инсталляциях, но требует внимания в высоконагруженных средах.
Пропускная способность
Gigabit Ethernet достаточно для большинства офисных приложений, но может стать ограничением при интенсивной работе с данными или использовании сетевого хранилища.
10 Gigabit становится стандартом для серверов виртуализации, особенно при использовании технологий vMotion, Storage vMotion или live migration.
Агрегация каналов позволяет объединить несколько сетевых интерфейсов для увеличения пропускной способности и обеспечения отказоустойчивости.
Разделение трафика
Выделение отдельных сетей для различных типов трафика повышает производительность и безопасность. Управляющий трафик, данные пользователей, backup и migraton должны использовать разные сетевые сегменты.
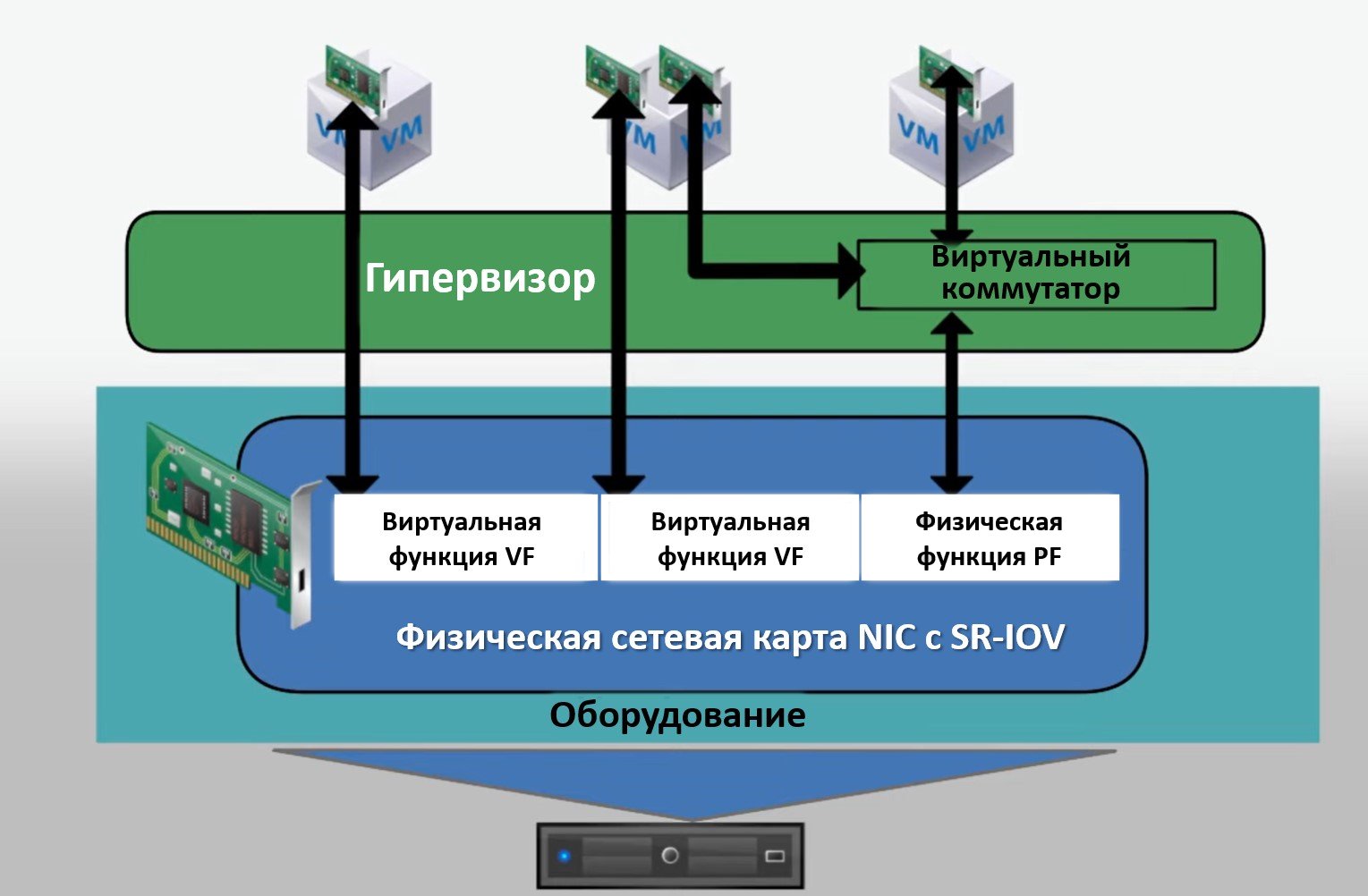
SR-IOV позволяет виртуальным машинам получить прямой доступ к сетевым адаптерам, минуя программный коммутатор гипервизора. Это критично для высокопроизводительных приложений.
Мониторинг и оптимизация
Планирование ресурсов — не разовая задача, а непрерывный процесс, который требует постоянного мониторинга и корректировок.
Ключевые метрики
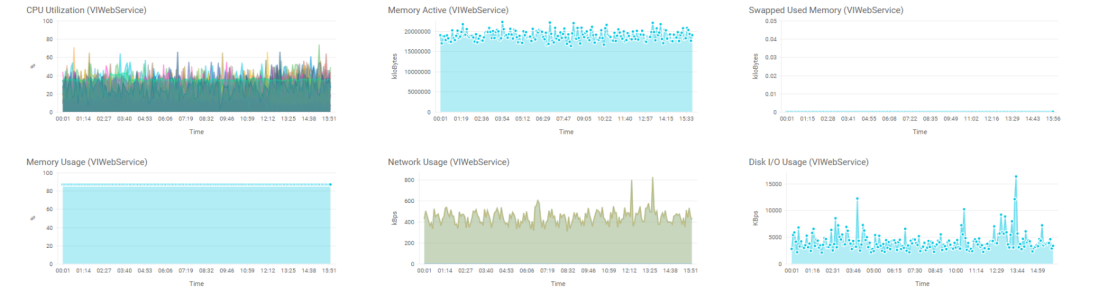
CPU utilization, CPU ready time, memory utilization, memory ballooning, disk latency, network utilization — базовый набор метрик для мониторинга эффективности использования ресурсов.
Trending analysis помогает выявить постепенные изменения в потреблении ресурсов и спланировать необходимые изменения заранее.
Инструменты анализа
Современные гипервизоры предоставляют подробную статистику использования ресурсов. vCenter Performance Charts, System Center VMM, XenCenter — каждая платформа имеет свои инструменты анализа.
Сторонние решения мониторинга часто предоставляют более глубокую аналитику и рекомендации по оптимизации. Они могут анализировать паттерны использования ресурсов и предлагать оптимальное размещение виртуальных машин.
Continuous optimization
Right-sizing виртуальных машин — удаление неиспользуемых ресурсов и добавление недостающих — должно выполняться регулярно на основе данных мониторинга.
Load balancing между хостами помогает равномерно распределить нагрузку и избежать "горячих точек" в инфраструктуре.
Automated resource management в современных платформах может выполнять базовую оптимизацию автоматически, но важные решения все еще требуют человеческого участия.
Планирование ресурсов для виртуальных машин — это баланс между производительностью, стоимостью и гибкостью. Правильный подход позволяет максимально эффективно использовать железо, обеспечивая при этом комфортную работу пользователей и возможности для роста.
Если выбор железа для виртуализации кажется сложной задачей, процесс лучше делегировать опытным техническим специалистам — штатным или нашим. Опишите задачу специалистам АЙТИТЕЛО и получите КП через час. Мы сэкономим ваше время и бесплатно подберем железо для виртуализации.







