Кластер серверов: что это такое и зачем нужна кластеризация

- Что вообще происходит внутри кластера
- Зачем вообще нужна кластеризация
- Типы кластеров: выбираем под задачу
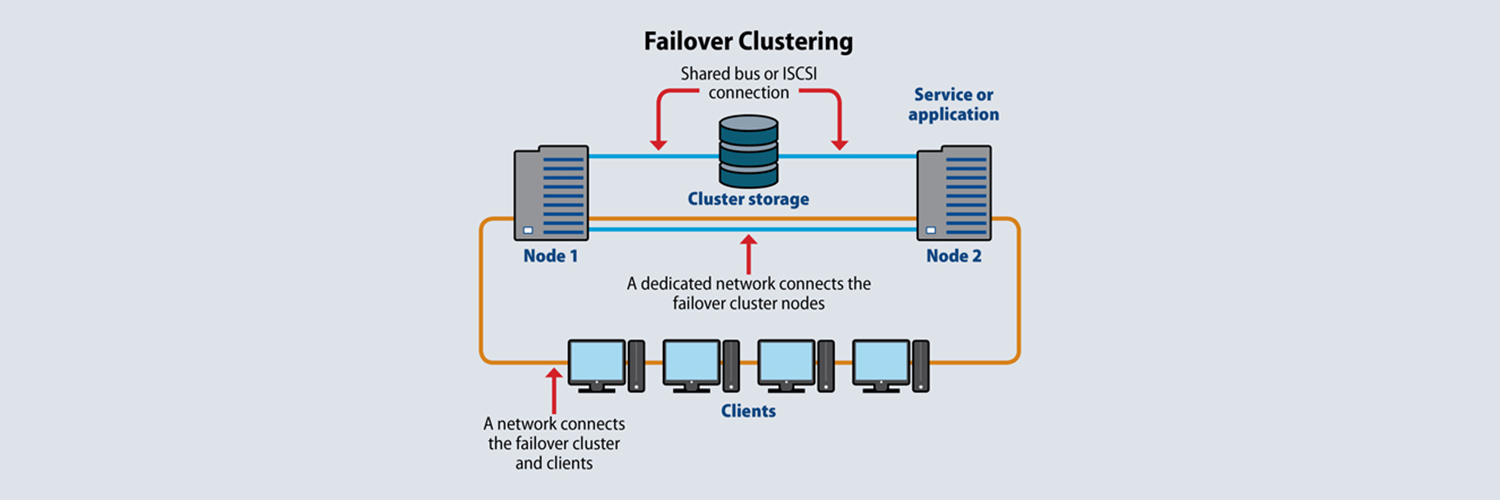
- Кластеры высокой доступности (Failover)
- Кластеры балансировки нагрузки
- Высокопроизводительные кластеры (HPC)
- Как это работает: технологии и архитектуры
- Где применяют кластеры
- Программное обеспечение и железо для кластеризации
- Риски и подводные камни
- Советы по планированию и внедрению
- Когда кластер — перебор
Каждую минуту простоя ваш интернет-магазин теряет деньги. Каждый отказ системы — это клиенты, которые уходят к конкурентам и больше не возвращаются. В эпоху, когда пользователи ожидают мгновенной реакции, а бизнес работает 24/7, вопрос не в том, упадет ли ваш сервер. Вопрос — когда это произойдет и сколько вы потеряете.
Крупные компании давно решили эту проблему. Их секрет не в том, что они покупают невероятно надежное железо за космические деньги. Секрет в другом подходе: вместо одного сервера — несколько, работающих как единая система. Один отказал? Остальные подхватывают нагрузку. Пользователи даже не замечают проблему, а бизнес продолжает зарабатывать.
Разберемся, как работают серверные кластеры и почему кластеризация серверов становится не роскошью, а необходимостью для любого серьезного проекта.
Что вообще происходит внутри кластера
Кластер серверов — это группа физических или виртуальных машин, которые работают как единый организм. Снаружи всё выглядит как один сервер с одним IP-адресом, но внутри — целая команда, где каждый участник имеет собственные ресурсы: процессор, оперативную память, диски. Если один узел «устает» или ломается, нагрузка автоматически перекидывается на остальных. Пользователи продолжают работать, даже не подозревая о проблеме.
Звучит просто, но за этой простотой стоит сложная инженерия. Узлы постоянно обмениваются данными, синхронизируются, следят друг за другом. Это как оркестр, где каждый музыкант играет свою партию, но все вместе создают гармонию.
Зачем вообще нужна кластеризация
Допустим, у вас интернет-магазин с оборотом 50 миллионов рублей в месяц. Сервер падает на два часа в пятницу вечером, когда идет пик продаж. Сколько денег вы потеряете? А репутация? Клиенты уйдут к конкурентам и вряд ли вернутся.
Кластеризация решает сразу несколько проблем:
Отказоустойчивость — главный козырь. Один сервер сломался? Остальные подхватывают его работу. Ваш сайт, база данных или приложение продолжают функционировать без перерывов.
Масштабируемость — трафик вырос в два раза? Добавьте еще пару узлов в кластер. Не нужно покупать мощный монстр-сервер за миллионы — можно наращивать мощность постепенно, по мере необходимости.
Балансировка нагрузки — запросы от пользователей распределяются между всеми узлами равномерно. Никто не перегружается, все работают в штатном режиме. Это как очереди в супермаркете: если одна касса перегружена, клиентов отправляют к другим.
Плановое обслуживание без простоев — нужно обновить ПО или заменить железо? Отключаете один узел, делаете что нужно, возвращаете обратно. Пользователи ничего не заметят.
Для критичных систем — больничных информационных систем, серверов онлайн-игр, банковских приложений — даже минута простоя неприемлема. Кластеры гарантируют доступность 99,99% времени или выше.

Типы кластеров: выбираем под задачу
Не все кластеры одинаковые. В зависимости от целей выбирают разные архитектуры.
Кластеры высокой доступности (Failover)
Их задача — обеспечить непрерывность работы. Если основной узел падает, резервный мгновенно берет управление на себя. Такие кластеры используют для баз данных, файловых серверов, систем управления предприятием. Время переключения — секунды, иногда миллисекунды.
Кластеры балансировки нагрузки
Здесь все узлы работают одновременно, распределяя между собой запросы пользователей. Веб-серверы, приложения, API — везде, где важна производительность под высокой нагрузкой. Nginx, HAProxy, Apache умеют раскидывать трафик по серверам, следя за их состоянием в реальном времени.
Высокопроизводительные кластеры (HPC)
Это для тяжелых вычислений — научных расчетов, рендеринга графики, обработки больших данных. Десятки или сотни процессоров работают над одной задачей параллельно. Университеты, исследовательские центры, студии анимации — их основные клиенты.
Как это работает: технологии и архитектуры
Теперь чуть глубже в технические детали, но без фанатизма.
Мастер-слейв (master-slave) — классическая схема. Один узел главный, остальные подчиненные. Мастер обрабатывает запросы на запись, слейвы — на чтение. Если мастер падает, один из слейвов становится новым главным. Просто и надежно для большинства задач.
Мастер-мастер (master-master) — все узлы равноправны, каждый может обрабатывать любые запросы. Сложнее настроить, зато нет единой точки отказа. Используется там, где критична скорость записи и высокая доступность.
Кольцевая архитектура — узлы образуют кольцо, данные передаются по цепочке. Если один выпадает, кольцо перестраивается. Встречается реже, но в некоторых сценариях дает преимущества.
Кворум — это не архитектура, а механизм. Общее хранилище данных, которое обеспечивает согласованность между узлами. Когда нужно принять решение (например, кто станет новым мастером), узлы голосуют. Решение принимается, если за него большинство. Без кворума кластер не сможет корректно работать при сбоях.
Эти технологии часто комбинируют. Например, кластер баз данных может использовать мастер-слейв + кворум для координации.
Где применяют кластеры
Кластеризация серверов — это не только для гигантов вроде Google или Amazon (хотя они тоже активно используют). Вот несколько реальных сценариев.
Веб-хостинг и сайты с высоким трафиком. Новостные порталы, интернет-магазины, стриминговые сервисы — везде, где одновременно работают тысячи пользователей. Кластер распределяет нагрузку, никто не видит «тормозов».
Базы данных. PostgreSQL, MySQL, MongoDB — все поддерживают кластеризацию. Для финансовых систем, CRM, ERP это жизненно необходимо. Потеря данных или простой базы — катастрофа.
Облачные сервисы. AWS, Azure, Google Cloud строят всю инфраструктуру на кластерах. Вы арендуете виртуальную машину — она крутится на кластере физических серверов. Один сломался? Ваша VM автоматически мигрирует на другой.
Научные и инженерные расчеты. Моделирование погоды, генетические исследования, физика частиц — задачи, которые одному компьютеру не под силу. HPC-кластеры делят работу на тысячи потоков и решают за часы то, на что обычный ПК потратил бы годы.
Игровые серверы. Онлайн-игры вроде MMO требуют мгновенной реакции. Лаги или падения сервера — игроки уйдут к конкуренту. Кластер обеспечивает стабильность и масштабируемость.
Программное обеспечение и железо для кластеризации
Чтобы собрать кластер, нужны софт и железо, которые умеют работать в связке.
Программное обеспечение
Pacemaker, Corosync — популярные инструменты для Linux-кластеров высокой доступности. Настраивают мониторинг узлов, автоматическое переключение.
Kubernetes — для контейнеризованных приложений. Управляет сотнями контейнеров на десятках серверов, автоматически распределяя нагрузку.
Galera Cluster, Patroni — специфичные решения для кластеризации баз данных MySQL и PostgreSQL.
HAProxy, Nginx — для балансировки HTTP/HTTPS трафика.
Железо
Серверы могут быть любыми — главное, чтобы они были совместимы и достаточно мощны. Часто используют идентичные конфигурации для упрощения администрирования. Сетевое оборудование должно обеспечивать высокую пропускную способность и минимальную задержку — кластер постоянно обменивается данными между узлами.
Общее хранилище (SAN, NAS) или распределенные файловые системы (Ceph, GlusterFS) — еще один важный компонент. Данные должны быть доступны всем узлам одновременно.
Риски и подводные камни
Кластеры не панацея. У них есть свои сложности.
Администрирование требует квалификации. Настроить отказоустойчивый кластер — задача не для новичка. Ошибка в конфигурации может привести к потере данных или split-brain (когда узлы теряют связь друг с другом и каждый считает себя главным).
Стоимость. Вместо одного сервера вы покупаете несколько, плюс коммутаторы, общее хранилище, лицензии на ПО. Первоначальные вложения выше, но они окупаются надежностью.
Сложность отладки. Когда что-то идет не так, найти причину сложнее — проблема может быть в любом узле или в сетевом взаимодействии.
Зависимость от сети. Если связь между узлами нестабильна, кластер будет работать плохо или вообще развалится. Поэтому сетевая инфраструктура должна быть надежной.
Советы по планированию и внедрению
Если решили строить кластер, учтите несколько моментов.
Определите требования. Что важнее — отказоустойчивость или производительность? Нужна ли масштабируемость на будущее? От этого зависит архитектура.
Начните с малого. Не обязательно сразу разворачивать десять узлов. Два-три сервера дадут достаточную надежность для начала. Потом добавите еще, если понадобится.
Протестируйте отказы. Обязательно проверьте, как кластер ведет себя при сбоях. Отключите один узел — переключился ли трафик на другие? Сколько времени заняло восстановление? Лучше выяснить слабые места в тестовой среде, чем в продакшене.
Автоматизируйте мониторинг. Кластер должен сам сообщать о проблемах — упал узел, высокая нагрузка, переполнение диска. Prometheus, Zabbix, Nagios помогут держать руку на пульсе.
Документируйте всё. Конфигурации, схемы сети, инструкции по восстановлению. Когда в три часа ночи что-то сломается, вы скажете себе спасибо.
Когда кластер — перебор
Не каждому проекту нужен кластер. Если у вас блог на 1000 посетителей в день, вложения в кластеризацию не окупятся. Обычный VPS с резервным копированием справится отлично. Но если вы онлайн-магазин с миллионами оборота, банк, стриминговый сервис или любой бизнес, где простой стоит дорого — кластер оправдан.
Главный критерий — критичность доступности. Сможете ли вы позволить себе час простоя? А два? Если ответ «нет» — пора задуматься о кластеризации серверов.
Кластеры — это не просто набор серверов, соединенных проводами. Это философия надежности, когда система выдерживает удары и продолжает работать. Технологии развиваются, появляются новые решения, но принцип остается прежним: вместе — сильнее. Ваши пользователи получают бесперебойный сервис, вы — спокойный сон. Звучит как неплохая сделка, правда?