Tier-уровни хранения данных: автоматическое перемещение по уровням важности
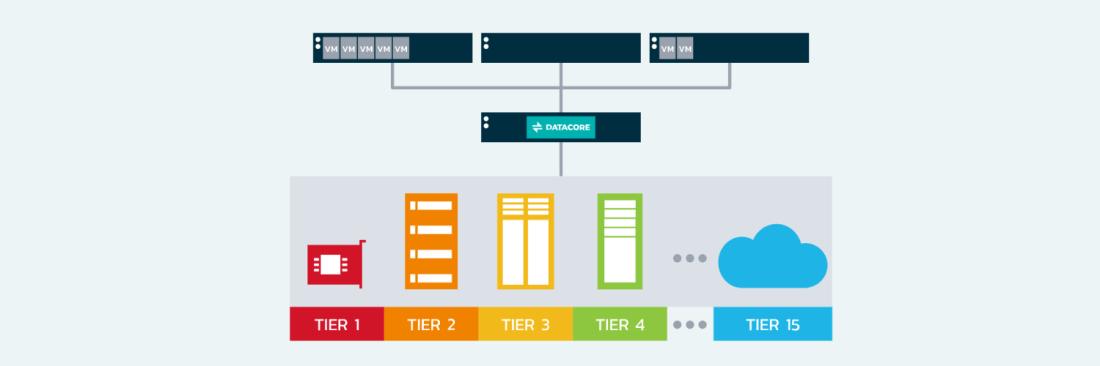
- Холодное, тёплое, горячее: температурная карта ваших данных
- Экономика здравого смысла: почему tiering экономит миллионы
- Автопилот для данных: как работает автоматический tiering
- Политики и правила: кто решает, что куда переезжает
- Виртуализация и облака: где tiering раскрывает потенциал
- AI на службе хранения: когда машины решают лучше людей
- Подводные камни: когда tiering может навредить
- Резервное копирование: особый случай для tiering
- Взгляд в будущее: куда движется технология
- Практические рекомендации: с чего начать
Знаете, какая самая дорогая ошибка в управлении данными? Хранить архивы пятилетней давности на NVMe-дисках за космические деньги, пока критически важные базы данных тормозят на старых HDD. Звучит абсурдно? А между тем, такая ситуация встречается чаще, чем вы думаете. Компании либо покупают дорогое железо для всех данных подряд и разоряются, либо экономят на всём и теряют в производительности. И вот здесь на помощь приходит tiering хранения данных — технология, которая решает извечную дилемму между скоростью и стоимостью.
Холодное, тёплое, горячее: температурная карта ваших данных
Давайте начнём с простого факта: не все данные одинаково полезны. Финансовый отчёт, который генерируется раз в квартал и потом лежит мёртвым грузом — это одно. База данных интернет-магазина, к которой обращаются тысячи раз в секунду — совсем другое. Tiered storage, или многоуровневое хранение, строится именно на этом принципе: разные данные заслуживают разного отношения.
Представьте систему хранения как многоэтажный паркинг. На первом этаже, у самого выхода — места для тех, кто постоянно приезжает и уезжает. Это ваши NVMe SSD — безумно быстрые, безумно дорогие. Второй этаж — обычные SSD, для тех, кто паркуется на день-два. Третий — надёжные SAS-диски для долгосрочной, но периодически нужной парковки. И где-то в подвале — огромная площадка с SATA-дисками для тех, кто оставляет машину на месяцы.
Вся магия в том, что современные СХД умеют автоматически определять, какие данные к какому уровню относятся. Система постоянно анализирует паттерны доступа: как часто к файлу обращаются, насколько быстрый отклик нужен, критичны ли данные для бизнеса. На основе этого анализа данные автоматически мигрируют между уровнями. Вчерашние "горячие" новости становятся "тёплыми", а потом и вовсе "остывают" до архивного состояния.
Что интересно, миграция происходит не на уровне файлов целиком, а на уровне блоков. То есть если в огромной базе данных активно используется только 10% записей, именно эти 10% будут жить на быстрых дисках, а остальное спокойно переедет на более медленные и дешёвые носители.
Экономика здравого смысла: почему tiering экономит миллионы
Теперь к цифрам, которые любит финансовый директор. Типичное распределение данных в корпоративной среде выглядит примерно так: 5-10% — критически важные "горячие" данные, 20-30% — периодически используемые "тёплые", и 60-70% — "холодные" архивы. Без tiering вам пришлось бы либо держать все 100% на дорогих быстрых дисках (финансовое самоубийство), либо всё на медленных (производственное самоубийство).
С уровнями хранения в СХД картина меняется кардинально. Вы покупаете небольшой объём сверхбыстрых NVMe для самых критичных данных, средний объём обычных SSD для рабочих нагрузок, и большие ёмкие HDD для всего остального. Экономия может достигать 60-70% от стоимости "плоской" инфраструктуры с одинаковыми дисками.
Но деньги — это только часть истории. Производительность приложений при правильно настроенном tiering может вырасти до 150%. Почему? Потому что критичные данные всегда находятся на самых быстрых носителях. Нет ситуации, когда важный запрос застревает в очереди за обращением к архивным данным. Каждый уровень работает в своём режиме, оптимальном для своего типа данных.
Энергопотребление — ещё один бонус. NVMe потребляют много энергии, но их у вас немного. Основной объём — это эффективные с точки зрения ватт на терабайт HDD. В масштабах дата-центра это означает существенное снижение расходов на электричество и охлаждение.
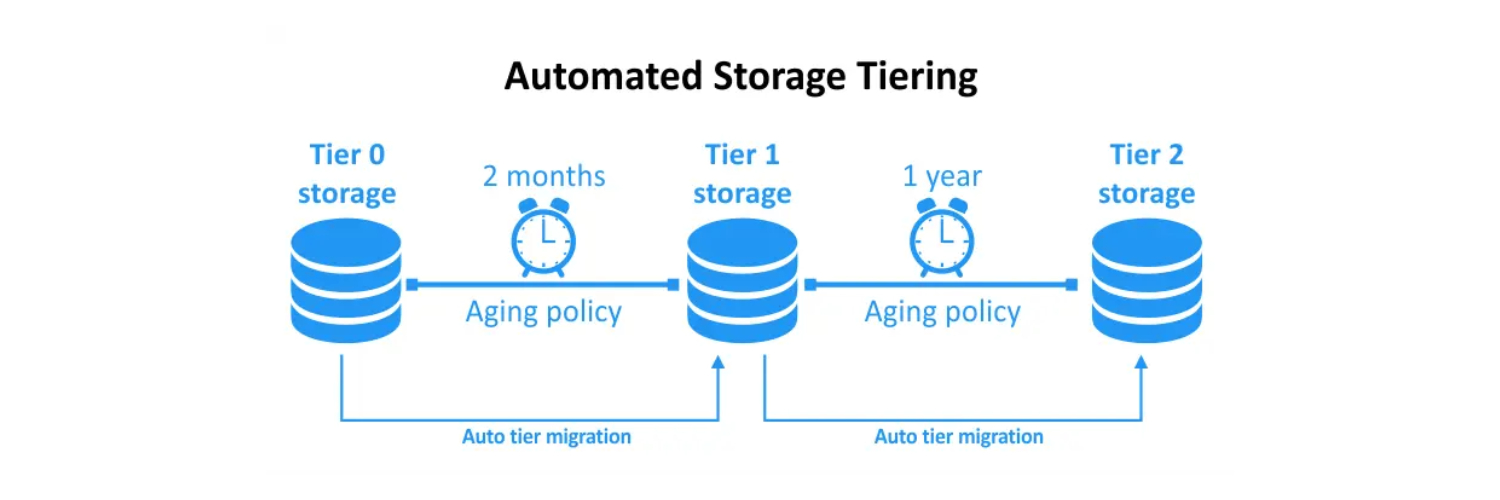
Автопилот для данных: как работает автоматический tiering
Автоматическое перемещение данных между уровнями — это не просто скрипт, который раз в сутки что-то куда-то копирует. Современные системы используют сложные алгоритмы анализа, которые учитывают множество факторов.
Частота доступа — очевидный, но не единственный критерий. Система анализирует также время последнего обращения, размер блоков, тип операций (чтение или запись), даже время суток. Например, база данных может быть "горячей" в рабочее время и "остывать" ночью. Умная система это учтёт и будет мигрировать данные в соответствии с расписанием.
Некоторые системы идут дальше и используют предиктивную аналитику. Они не просто реагируют на текущие паттерны использования, но и предсказывают будущие потребности. Квартальный отчёт всегда генерируется первого числа? Система заранее "подогреет" нужные данные, переместив их на быстрый уровень.
Важный момент — гранулярность перемещения. Старые системы перемещали файлы целиком, что было неэффективно для больших файлов с неравномерным доступом. Современный tiering работает на уровне блоков размером от 256 КБ до нескольких мегабайт. Это позволяет держать на быстром уровне только реально используемые части данных.
Политики и правила: кто решает, что куда переезжает
Автоматика — это хорошо, но иногда нужен ручной контроль. Современные СХД позволяют настраивать детальные политики tiering под специфику вашего бизнеса.
Можно задать минимальное время "выдержки" на уровне. Например, все новые данные сначала попадают на быстрый уровень и остаются там минимум 24 часа, независимо от активности. Это гарантирует быстрый доступ к свежей информации.
Или наоборот — можно установить агрессивную политику экономии, когда данные переезжают на более дешёвый уровень уже через несколько часов неактивности. Подходит для сред разработки и тестирования, где данные быстро теряют актуальность.
Интересная опция — "пиннинг" или закрепление. Вы можете явно указать, что определённые данные должны всегда оставаться на конкретном уровне. Критичная база данных? Закрепляем на NVMe. Архив за 2015 год? Прибиваем гвоздями к SATA и забываем.
Расписание миграции — ещё один важный параметр. Перемещение данных создаёт нагрузку на систему, поэтому разумно выполнять его в часы минимальной активности. Многие настраивают агрессивный tiering на выходные и ночное время, когда нагрузка на СХД минимальна.
Виртуализация и облака: где tiering раскрывает потенциал
Виртуализированные среды и tiering созданы друг для друга. В типичной VMware или Hyper-V инфраструктуре у вас сотни виртуальных машин с совершенно разными профилями нагрузки. Контроллер домена крутится вхолостую 99% времени. База 1С работает как проклятая с 9 до 18. Веб-сервер испытывает пиковые нагрузки непредсказуемо.
Без tiering вам пришлось бы либо обеспечить всем ВМ одинаково высокую производительность (дорого), либо вручную распределять их по разным хранилищам (сложно и негибко). Автоматический tiering решает эту проблему элегантно: каждая ВМ получает тот уровень производительности, который ей нужен прямо сейчас.
VMware vSAN, Nutanix, Microsoft Storage Spaces Direct — все современные гиперконвергентные платформы имеют встроенный tiering. Причём работает он не только внутри одного узла, но и между узлами кластера. Горячие данные могут мигрировать на узел с самыми быстрыми дисками, а холодные — на узел с большими ёмкостями.
Облачные провайдеры тоже активно используют tiering, хотя и не всегда афишируют это. AWS S3 имеет несколько классов хранения: Standard для горячих данных, Infrequent Access для тёплых, Glacier для холодных архивов. Переход между классами может быть как ручным, так и автоматическим по заданным правилам.
AI на службе хранения: когда машины решают лучше людей
Искусственный интеллект и машинное обучение выводят tiering на новый уровень. Вместо простых правил "если не использовалось 30 дней — переместить вниз", ML-алгоритмы выявляют сложные паттерны, невидимые человеческому глазу.
Например, система может обнаружить, что определённые файлы всегда запрашиваются вместе, хотя формально между ними нет связи. Или что доступ к некоторым данным имеет сезонный характер — активность в конце квартала, затишье в середине. Традиционные rule-based системы такие тонкости упустят.
Dell EMC PowerMax, HPE Primera, NetApp AFF — флагманские СХД уже используют AI для оптимизации tiering. Системы постоянно обучаются на реальных данных вашей инфраструктуры, становясь умнее с каждым днём. Результат — снижение задержек на 20-30% при той же конфигурации железа.
Предиктивная аналитика позволяет системе готовиться к будущим нагрузкам. Если AI видит, что каждый понедельник в 9:00 начинается всплеск обращений к определённым данным, он заранее переместит их на быстрый уровень. Никаких тормозов в начале рабочей недели.
Подводные камни: когда tiering может навредить
Теперь о том, что обычно умалчивают вендоры. Tiering — не серебряная пуля, и в некоторых случаях может создать больше проблем, чем решить.
Первая проблема — непредсказуемые нагрузки. Если ваши паттерны доступа хаотичны и меняются каждый день, система будет постоянно гонять данные туда-сюда, создавая лишнюю нагрузку. В таких случаях проще держать всё на среднем по производительности уровне.
Вторая — маленькие объёмы данных. Если у вас всего 10-20 ТБ данных, накладные расходы на tiering могут не окупиться. Проще купить SSD на весь объём и не морочить голову.
Третья — требования к задержкам. Некоторые приложения требуют гарантированной низкой латентности. Если данные внезапно окажутся на медленном уровне, приложение может сломаться. Для таких случаев нужны жёсткие политики пиннинга или вообще отказ от tiering.
Миграция данных сама по себе создаёт нагрузку. Если система постоянно что-то перемещает, это съедает IOPS и пропускную способность. В худшем случае tiering может начать мешать основной работе.
Резервное копирование: особый случай для tiering
Системы резервного копирования и tiering — это отдельная история. С одной стороны, бэкапы идеально подходят для многоуровневого хранения: свежие копии нужны быстро, старые могут лежать на самых медленных носителях.
С другой стороны, есть нюансы. При восстановлении вам может срочно понадобиться бэкап годичной давности. Если он на ленте в удалённом хранилище, восстановление займёт часы или дни. Поэтому для бэкапов часто используют специальные политики: критичные системы держат на быстром уровне дольше, некритичные уезжают в архив быстрее.
Veeam, Commvault, Veritas NetBackup — все поддерживают tiering для хранения бэкапов. Можно настроить автоматическое перемещение: последние копии на SSD, недельные на HDD, месячные на ленты или в облако. Это даёт оптимальный баланс между скоростью восстановления и стоимостью хранения.
Взгляд в будущее: куда движется технология
Tiering хранения данных продолжает эволюционировать. Появляются новые типы носителей — Intel Optane, storage-class memory — которые создают дополнительные уровни между RAM и SSD. Системы становятся всё более гранулярными, вплоть до управления отдельными объектами внутри файлов.
Интеграция с облаками становится всё теснее. Гибридные системы могут использовать локальные диски для горячих данных и облачное хранилище для холодных. При этом для пользователя всё выглядит как единая файловая система.
Автоматизация достигает нового уровня. Системы не просто перемещают данные, но и автоматически провижинят ресурсы, масштабируют уровни, даже закупают дополнительное хранилище через API облачных провайдеров.
Практические рекомендации: с чего начать
Если вы решили внедрить tiering, начните с анализа текущих данных. Посмотрите статистику доступа за последние 3-6 месяцев. Сколько данных реально "горячие"? Это поможет правильно рассчитать ёмкости уровней.
Не гонитесь за максимальным количеством уровней. Для большинства компаний достаточно трёх: быстрый (NVMe/SSD), средний (SAS HDD), медленный (SATA HDD). Больше уровней — больше сложности в управлении.
Начните с консервативных политик. Лучше держать данные на быстром уровне чуть дольше необходимого, чем получить тормоза в критический момент. По мере накопления опыта политики можно ужесточать.
Обязательно мониторьте эффективность. Смотрите не только на экономию места, но и на количество "промахов" — ситуаций, когда нужные данные оказались на медленном уровне. Если промахов много, политики нужно корректировать.
Tiering хранения данных — это не просто модная технология, а реальный инструмент оптимизации IT-инфраструктуры. При правильном внедрении можно добиться существенной экономии без потери производительности. Главное — понимать свои данные и их жизненный цикл. Технология лишь инструмент, который помогает привести хранение в соответствие с реальными потребностями бизнеса. И да, это работает не только в энтерпрайзе — даже средний бизнес может выиграть от грамотного использования уровней хранения в СХД.







