Диагностика проблем с диском на работающем сервере

- Первые признаки неисправности
- Базовая диагностика состояния
- SMART: внутренний доктор дисков
- Интерпретация результатов самотестирования
- Анализ производительности дисковой подсистемы
- Мониторинг в реальном времени
- Специфика диагностики HDD и SSD
- Особенности жестких дисков
- Диагностика SSD накопителей
- Продвинутые методы диагностики
- Стресс-тестирование дисков
- Профилактика и непрерывный мониторинг
Сервер работает, пользователи не жалуются, но что-то подсказывает, что с дисками не все в порядке. Может быть, это едва заметное увеличение времени отклика, странные звуки из серверной стойки или периодические подвисания приложений. Проблема в том, что диагностика диска на сервере в продакшне — это хождение по минному полю. Одно неосторожное действие может положить всю систему.
Современные диски, особенно в серверном окружении, умеют долго скрывать проблемы. SSD маскируют плохие блоки за счет over-provisioning, а жесткие диски пытаются переназначить проблемные сектора. К моменту, когда проблемы становятся очевидными, часто уже поздно спасать данные без серьезных последствий.
Хорошая новость: современные инструменты позволяют провести глубокую диагностику дисковой подсистемы без остановки сервера. Плохая — результаты нужно уметь правильно интерпретировать. Неопытный администратор может принять нормальную нагрузку за симптом отказа или, наоборот, пропустить реальную проблему.
Особенно важна грамотная диагностика для серверов в дата-центрах, где замена дисков требует координации и планирования. Качественный сервер для стойки обычно имеет RAID-массивы и системы горячей замены, но это не отменяет необходимости раннего выявления проблем.
Первые признаки неисправности
Диски редко умирают внезапно — обычно этому предшествуют характерные симптомы. Умение распознать эти сигналы может спасти от потери данных и внеплановых простоев.
Увеличение времени отклика — самый коварный симптом. Пользователи жалуются, что все стало работать медленнее, но конкретизировать не могут. Приложения время от времени "подвисают" на несколько секунд, а потом продолжают работать как ни в чем не бывало. Такое поведение типично для дисков с нарастающими проблемами.
Появление ошибок в системных логах — более очевидный симптом, но и его легко пропустить в потоке обычных сообщений. Ядро Linux записывает информацию о проблемах с дисками в /var/log/messages или /var/log/syslog, но среди сотен строк обычных сообщений важная информация может затеряться.
Странные звуки от жестких дисков заслуживают особого внимания. Здоровый HDD работает с едва слышным гулом. Щелчки, скрежет, периодические "клацания" — признаки механических проблем. SSD, естественно, работают бесшумно, поэтому любые звуки от них сигнализируют о проблемах с вентиляторами или другими компонентами.
Базовая диагностика состояния
Первым делом стоит проверить общее состояние дисковой подсистемы стандартными средствами. Команда df -h покажет заполненность файловых систем, но важнее обратить внимание на потенциальные проблемы с монтированием или доступностью разделов.
dmesg | grep -i error выведет системные сообщения об ошибках, включая проблемы с дисками. Особое внимание стоит обратить на сообщения типа "sector read error", "medium error" или "device timeout". Эти ошибки могут указывать на физические проблемы с носителем.
Команда lsblk покажет структуру блочных устройств и поможет убедиться, что все диски видны системой. Отсутствующие или неопределенные устройства могут сигнализировать о проблемах с подключением или контроллером.
Утилита iostat из пакета sysstat предоставляет детальную статистику ввода-вывода. Параметр -x 1 покажет расширенную статистику с обновлением каждую секунду. Высокие значения %util (утилизации диска) или аномально большие времена отклика (await) могут указывать на проблемы.
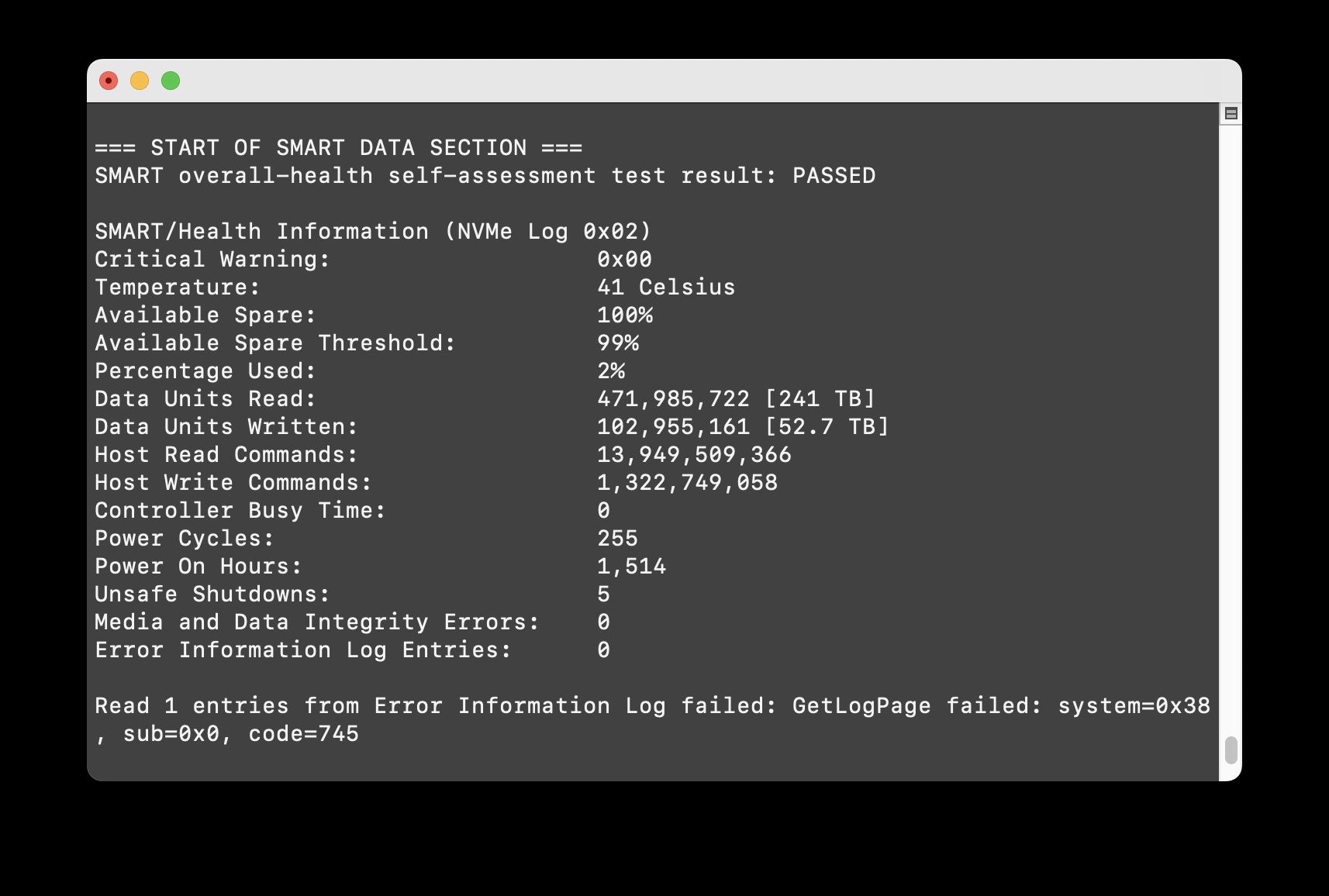
SMART: внутренний доктор дисков
Self-Monitoring, Analysis and Reporting Technology — встроенная система самодиагностики современных дисков. SMART непрерывно отслеживает ключевые параметры и может предсказать отказ задолго до его фактического наступления.
Утилита smartctl из пакета smartmontools — основной инструмент для работы с SMART данными. Команда smartctl -a /dev/sda выведет полную информацию о диске, включая результаты самотестирования и критические атрибуты.
Анализ SMART атрибутов требует понимания специфики различных производителей дисков. У каждого вендора своя система подсчета и интерпретации значений. Однако несколько атрибутов критичны независимо от производителя.
Reallocated Sectors Count показывает количество переназначенных секторов. Ненулевое значение — первый тревожный звонок. Диск пытается компенсировать проблемные области, но его ресурсы ограничены.
Current Pending Sector Count отражает количество секторов, которые ожидают переназначения после следующей операции записи. Рост этого параметра указывает на прогрессирующую деградацию поверхности диска.
Uncorrectable Sector Count показывает количество секторов, которые не удалось прочитать даже с применением кодов коррекции ошибок. Любое ненулевое значение — серьезный повод для беспокойства.
Интерпретация результатов самотестирования
SMART поддерживает несколько типов самотестирования: короткий тест, расширенный тест и выборочный тест. Короткий тест обычно занимает несколько минут и проверяет основные компоненты диска. Расширенный тест может длиться несколько часов, но обеспечивает более тщательную проверку.
Запуск тестирования на продакшн сервере требует осторожности. Хотя современные диски позволяют выполнять самотестирование в фоновом режиме, дополнительная нагрузка может повлиять на производительность системы. Лучше планировать такие проверки на периоды минимальной активности.
Результат "PASSED" не гарантирует отсутствие проблем в будущем, но "FAILED" однозначно указывает на необходимость замены диска. Особое внимание стоит обратить на тесты, которые прерываются или завершаются с ошибками чтения.
Анализ производительности дисковой подсистемы
Производительность дисков может деградировать постепенно, и без систематического мониторинга эти изменения легко пропустить. Современные серверы обрабатывают тысячи операций ввода-вывода в секунду, и даже небольшое снижение производительности может значительно повлиять на отзывчивость системы.
Утилита iotop показывает процессы, активно использующие дисковую подсистему. Это помогает выявить приложения, создающие необычную нагрузку, и отличить проблемы производительности от аппаратных неисправностей.
hdparm -t /dev/sda измеряет скорость последовательного чтения с диска. Этот тест создает определенную нагрузку, поэтому использовать его на продакшн системах нужно осторожно. Результаты можно сравнить со спецификациями диска или предыдущими измерениями.
Более продвинутый инструмент fio позволяет настроить детальные тесты производительности с различными паттернами доступа: последовательное чтение/запись, случайный доступ, смешанные нагрузки. Однако его использование на рабочих системах требует особой осторожности из-за интенсивного воздействия на диски.
Мониторинг в реальном времени
Команда watch -n 1 'cat /proc/diskstats' покажет статистику дисковой активности с обновлением каждую секунду. Хотя вывод довольно сырой, опытный администратор может выявить аномалии в паттернах доступа к дискам.
Более удобный способ — использование sar -d 1, который предоставляет удобочитаемую статистику по всем блочным устройствам. Высокие значения await (среднее время ожидания) или svctm (время обслуживания) могут указывать на проблемы с производительностью диска.
Утилита atop обеспечивает комплексный мониторинг системы, включая детальную информацию о дисковой активности. Она показывает не только общую статистику, но и информацию о конкретных процессах, использующих диски.
Специфика диагностики HDD и SSD
проблемы hdd ssd сервер требуют разного подхода к диагностике. Механические жесткие диски и твердотельные накопители имеют кардинально разную архитектуру, что влияет на характер возможных неисправностей.

Особенности жестких дисков
HDD содержат движущиеся части, что делает их уязвимыми к механическому износу. Головки чтения/записи могут деградировать, шпиндель — разбалансироваться, а магнитная поверхность — терять свои свойства.
Акустический мониторинг — специфический метод диагностики HDD. Здоровый диск издает равномерный гул двигателя и едва слышные звуки движения головок. Щелчки, скрежет или нерегулярные звуки часто предшествуют серьезным отказам.
Вибрация — еще один фактор, влияющий на работу механических дисков. В серверных стойках вибрация от соседних устройств может ускорить износ и привести к ошибкам чтения. Особенно это актуально для высокооборотных дисков.
Температурный режим критически важен для HDD. Перегрев ускоряет деградацию магнитных свойств поверхности и может привести к деформации компонентов. SMART атрибут температуры стоит мониторить постоянно.
Диагностика SSD накопителей
Твердотельные накопители имеют свою специфику диагностики, связанную с особенностями флеш-памяти и алгоритмов управления.
Wear Leveling Count показывает, насколько равномерно используются ячейки памяти. SSD контроллеры стараются распределить операции записи по всему объему накопителя, но со временем некоторые области могут изнашиваться быстрее.
Program/Erase Cycle Count отражает количество циклов перезаписи блоков памяти. У каждого типа флеш-памяти есть ограничение на количество циклов, после которого ячейки становятся ненадежными.
Uncorrectable Error Count в SSD обычно связан с исчерпанием ресурса ячеек памяти или проблемами с контроллером. В отличие от HDD, где такие ошибки могут быть связаны с механическими проблемами, в SSD они часто указывают на близкий конец жизни устройства.
Available Reserved Space показывает остаток резервных блоков, которые SSD использует для замены изношенных ячеек. Когда этот ресурс исчерпывается, накопитель может перейти в режим только для чтения.
Продвинутые методы диагностики
Когда стандартные инструменты не дают четкой картины, приходится применять более сложные методы диагностики.
badblocks — утилита для поиска поврежденных блоков на диске. Запуск в режиме только чтения (badblocks -v /dev/sda) относительно безопасен, но может занять много времени на больших дисках. Режим записи крайне опасен для продакшн систем.
Анализ логов системного журнала может выявить паттерны, невидимые при поверхностном осмотре. Регулярные ошибки чтения определенных секторов, таймауты операций ввода-вывода или сообщения о переназначении блоков — все это может указывать на прогрессирующие проблемы.
Мониторинг производительности на уровне файловой системы помогает выявить проблемы, которые не отражаются в статистике блочных устройств. Утилиты типа filefrag показывают фрагментацию файлов, что может влиять на производительность HDD.
Стресс-тестирование дисков
Контролируемое стресс-тестирование может выявить проблемы, которые проявляются только под нагрузкой. Однако на продакшн системах такие тесты нужно проводить крайне осторожно.
stress-ng предоставляет различные виды нагрузки, включая интенсивные операции ввода-вывода. Можно настроить тесты для имитации реальных рабочих нагрузок и отследить поведение дисков под стрессом.
Мониторинг во время стресс-тестов особенно важен. Здоровые диски должны показывать стабильную производительность даже под высокой нагрузкой. Резкие колебания времени отклика, рост количества ошибок или деградация производительности могут указывать на проблемы.
Профилактика и непрерывный мониторинг
Лучшая диагностика — это предотвращение проблем. Система непрерывного мониторинга состояния дисков может выявить проблемы на ранней стадии, когда еще есть время для планового обслуживания.
Автоматизированная проверка SMART атрибутов должна стать частью регулярного мониторинга. Скрипты могут отслеживать критические параметры и отправлять уведомления при превышении пороговых значений.
Тренд-анализ помогает выявить постепенную деградацию дисков. Медленный рост количества переназначенных секторов или постепенное увеличение времени отклика может указывать на приближающиеся проблемы.
Ведение базы данных состояния дисков позволяет отслеживать изменения во времени и планировать замены. Информация о возрасте дисков, количестве отработанных часов и динамике ключевых параметров помогает принимать обоснованные решения.
Регулярное тестирование процедур восстановления гарантирует, что в случае отказа диска система быстро вернется к работе. RAID массивы, резервные копии и планы disaster recovery должны регулярно проверяться на работоспособность.
Диагностика дисков на работающем сервере — это баланс между необходимостью получить информацию и риском повредить систему. Грамотное использование доступных инструментов, понимание специфики различных типов накопителей и систематический подход к мониторингу помогают поддерживать здоровье дисковой подсистемы и избегать внезапных отказов.






