Как убедить директора купить сервер: руководство для тех, кто устал ждать

- Почему директор не слышит ваши аргументы
- Переводим технику на язык денег: что такое TCO и зачем он вам
- Простой просчитывается дорого (и вы можете это доказать)
- Технические факты, которые директор поймет
- Как правильно упаковать аргументы
- Собираем доказательную базу
- Что делать, если бюджета правда нет
- Пошаговый чек-лист: от идеи до покупки
Ваш сервер работает уже пятый год. Загрузка процессора регулярно подскакивает до 85%, диски заполнены на 90%, а время отклика системы выросло вдвое. Вы понимаете: ресурсы на исходе, и рано или поздно это выльется в серьезный сбой. Вы уже три раза писали служебку с обоснованием, готовили презентацию с графиками нагрузки, даже пытались на пальцах объяснить риски. А в ответ? «Подождите до следующего квартала», «А он точно не протянет?», «Дорого как-то».
Знакомо? Вы не одиноки. Тысячи системных администраторов по всей стране каждый день сталкиваются с этой ситуацией: техническая необходимость очевидна, а бюджет застрял где-то между «подумаем» и «не сейчас». Дело не в том, что директор вредный. Просто вы говорите на разных языках.
Давайте разберемся, как перевести ваши технические аргументы на язык, который руководство действительно услышит. Без магии, без манипуляций. Просто честная упаковка фактов.
Почему директор не слышит ваши аргументы
Вы приходите к руководству с железной логикой: старый сервер медленный, новый быстрее. Нужна надежность, нужна производительность, нужна отказоустойчивость. Звучит убедительно? Для вас да. Для директора это звучит как «вроде нужно, но может и подождать».
Руководитель думает категориями другого порядка. Деньги, риски, окупаемость, репутация перед клиентами. Пока вы оперируете мегагерцами и гигабайтами, директор считает, сколько стоит каждый час простоя и что скажут партнеры, если у них зависнет доступ к системе. Это не плохо и не хорошо, просто факт. Ваша задача: научиться говорить на этом языке.
Вот типичные возражения, которые вы слышите, и что за ними стоит на самом деле:
| Что говорит директор | Что он думает на самом деле |
|---|---|
| «Дорого» | «Не вижу возврата инвестиций» |
| «Пока работает» | «Не понимаю масштаб риска» |
| «Подождем квартал» | «Есть более срочные траты» |
| «А точно нужно?» | «Не верю, что проблема серьезная» |
Директор не отказывает вам из вредности. Он просто не видит связи между новым сервером и результатами бизнеса. Ваша задача: показать эту связь. Причем показать не в технических терминах, а в рублях, часах простоя и потерянных клиентах.
Переводим технику на язык денег: что такое TCO и зачем он вам
Забудьте на минуту про частоты процессоров. Есть только один аргумент, который работает безотказно: деньги. Точнее, сколько компания тратит сейчас и сколько будет тратить после обновления. Здесь вам поможет концепция TCO (Total Cost of Ownership, или полная стоимость владения).
TCO это не просто цена покупки. Это все расходы за весь срок жизни оборудования: электричество, обслуживание, ремонты, время простоев. Старый сервер может казаться «бесплатным», потому что за него уже заплатили. Но каждый день он жрет киловатты, как старый холодильник, и ежемесячно требует костылей от админа.
Давайте посчитаем на условном примере. Возьмем для расчета типичный пятилетний сервер против нового:
| Параметр | Старый сервер (5 лет) | Новый сервер | Возможная разница за год |
|---|---|---|---|
| Энергоэффективность* | Ниже (больше ватт на задачу) | Выше (меньше ватт на задачу) | До 15 000 ₽ экономии |
| Время на обслуживание админа | 6-10 часов/месяц | 1-3 часа/месяц | От 80 000 ₽ (зарплата) |
| Риск внеплановых простоев | Выше | Ниже | От 100 000 ₽ |
| Ориентировочные скрытые затраты | 300-500 тыс. ₽ | 50-100 тыс. ₽ | 200-400 тыс. ₽ |
| Период окупаемости (ROI) |
|
|
18-24 месяца |
*Новые серверы не обязательно потребляют меньше электричества в абсолютных цифрах (современные CPU могут иметь TDP 300-400 Вт), но выполняют значительно больше операций на каждый потребленный ватт. Экономия возникает от более эффективного использования энергии: меньше серверов для той же нагрузки или больше работы за те же деньги.
Обратите внимание: это примерный расчет для иллюстрации методики. Конкретные цифры зависят от вашей инфраструктуры, тарифов на электроэнергию и зарплат специалистов.
Простой просчитывается дорого (и вы можете это доказать)
Вот где начинается самое интересное. Руководство часто не осознает, во что обходится час простоя. Для них это абстракция: «ну, подождут пользователи». На самом деле каждая минута, когда сервер лежит, компания теряет конкретные деньги.
Посчитаем на примере вашей компании. Допустим, у вас работают 50 человек со средней зарплатой 80 000 рублей в месяц. Час простоя сервера это час, когда никто не работает. Формула расчета:
Стоимость часа простоя = (Зарплатный фонд / Рабочие часы в месяце) + Упущенная выручка в час + Ожидаемые SLA-штрафы
Разберем по частям:
- Зарплатная составляющая: (80 000 × 50) / 160 ≈ 25 000 рублей в час
- Упущенная выручка: если у вас интернет-магазин, производство или сервисная компания, посчитайте среднюю выручку в час. Например, если месячная выручка 3 млн рублей, то час простоя это примерно 10 000 рублей упущенной прибыли
- SLA-штрафы: если у вас есть договоры с клиентами с гарантией доступности, добавьте потенциальные штрафы
Итоговая стоимость для этого примера: 25 000 + 10 000 = 35 000 рублей в час.
Если сервер упал в пятницу вечером, а до утра понедельника его никто не поднимет (знакомая ситуация?), компания потеряет минимум два рабочих дня. Это уже сотни тысяч рублей. А если учесть потерянные сделки, недовольных клиентов, репутационные риски, сумма растет кратно.
А теперь конкретика из реальной практики. Если у вас в компании работает 1С, простой из-за перегрева старого процессора или отказа дисков обходится в среднем в 100-150 тысяч рублей в час. Это не преувеличение. Учитывайте не только зарплаты бухгалтеров и менеджеров, но и замороженные платежи, сорванные отгрузки, остановку продаж. В производственных компаниях, где простой останавливает линию, цифры еще выше.
Подставьте сюда реальные цифры вашей компании. Посчитайте все три компонента: зарплатный фонд, упущенную выручку и возможные штрафы. Соберите данные о частоте инцидентов за последний год. Если старому серверу пять лет и больше, обратите внимание на динамику: как часто возникали проблемы год назад и как часто они случаются сейчас.
И главное: эти расчеты нужно показать руководству не как страшилку, а как бизнес-кейс. Вы не пугаете апокалипсисом. Вы предлагаете снизить операционные риски. Это нормальная практика управления. Страховые компании существуют по тому же принципу.
Технические факты, которые директор поймет
Иногда одна конкретная цифра работает лучше, чем десять общих фраз про «надежность» и «производительность». Вот несколько технических фактов, которые можно перевести на язык денег:
Про производительность дисков. Если ваш сервер работает на старых дисках SATA образца 2014-2016 годов, среднее время отклика приложений увеличивается на 25-40% по сравнению с современными SSD или NVMe. Звучит абстрактно? Переведем: если обработка заказа в CRM занимала 10 секунд, теперь это 13-14 секунд. Если менеджер обрабатывает 50 заказов в день, он теряет 2,5-3,5 минуты на каждый. За месяц это 2-3 часа рабочего времени одного человека. Умножьте на количество менеджеров и получите потерянные часы и недополученную выручку.
Про надежность RAID-массивов. У вас на сервере стоит RAID для защиты данных? Отлично. Но вот что нужно знать директору: на практике отказоустойчивость RAID ухудшается с возрастом оборудования. Вместо универсального процента ориентируйтесь на SMART-логи дисков и локальную статистику инцидентов (частоту отказов, время восстановления). Проверьте SMART-атрибуты: Reallocated_Sector_Count, Current_Pending_Sector, Offline_Uncorrectable. Если эти значения растут, диски деградируют. Также важно понимать: все диски в массиве обычно одного возраста и из одной производственной партии. Когда один диск умирает, остальные часто следуют за ним в течение недель или месяцев. Если вашему серверу пять лет, соберите статистику отказов и покажите ее руководству.
Про критичность систем. В вашей компании крутятся критичные приложения? Посчитайте их простой честно. База клиентов недоступна: менеджеры простаивают. Почта не работает: коммуникация парализована. ERP-система упала: производство встало. Складской учет недоступен: отгрузки замерли. Каждая из этих ситуаций стоит десятки тысяч рублей в час, даже в небольших компаниях.
Про энергопотребление. Вот еще факт для бухгалтерии: старые серверы с процессорами пятилетней давности потребляют в 1,5-2 раза больше энергии при той же (или меньшей) производительности. Если сервер работает 24/7, за год набегает ощутимая сумма. Плюс к этому повышенное тепловыделение, что увеличивает нагрузку на кондиционеры в серверной. Это не экология, это прямые расходы в платежках за электричество.
Интересный момент: современные процессоры AMD EPYC 9004 или Intel Xeon Scalable Gen5 имеют высокий TDP (тепловыделение может достигать 400 Вт), но при этом дают кратно большую производительность. Экономия считается не только в абсолютных ваттах, но и в показателе ватт-на-операцию. Проще говоря: новый процессор может потреблять те же 400 Вт, что и старый, но при этом выполнять в 2-3 раза больше задач. Получается, на каждую обработанную операцию вы тратите в разы меньше электричества. Это особенно критично для виртуализации и высоконагруженных систем.
Соберите такие факты по вашей инфраструктуре. Не абстрактные «устарело» и «медленно», а конкретные цифры с привязкой к деньгам. Директор оценит честность и детальность подхода.
Как правильно упаковать аргументы
Теперь у вас есть методика расчетов и конкретные технические факты. Осталось научиться их подавать. Потому что даже самые убедительные цифры можно запороть, если прийти к директору с видом «ну вот, я же говорил».
Правило первое: говорите на языке бизнес-целей. Не «нам нужен сервер с 128 гигабайтами оперативки». А «новый сервер позволит обрабатывать заказы клиентов на 35% быстрее, что снизит количество жалоб и увеличит пропускную способность отдела продаж». Слышите разницу? Первое про технику. Второе про результат для компании.
Правило второе: покажите альтернативы. Подготовьте не один вариант, а три:
| Вариант | Примерная стоимость | Плюсы | Минусы | Риски | Окупаемость (ROI) |
|---|---|---|---|---|---|
| Минимальный (бюджетный сервер) | 250-350 тыс. ₽ | Дешево, быстро внедрить | Хватит на 2-3 года, ограниченный запас | Придется обновляться снова | ~24 месяца |
| Сбалансированный (средний сервер) | 450-600 тыс. ₽ | Баланс цена/возможности, запас на 4-5 лет | Дороже базового варианта | Минимальные | ~18-20 месяцев |
| Максимальный (топ-конфигурация) | 800-1200 тыс. ₽ | Запас на 6-8 лет, высокая производительность | Дорого, возможно избыточно | Переплата за неиспользуемые ресурсы | ~30 месяцев |
*Примечание: все приведённые суммы — иллюстративные.
Такая таблица показывает, что вы не просите самое дорогое. Вы предлагаете рациональный выбор. И директор чувствует, что контролирует решение. Обратите внимание на столбец «Окупаемость»: большинство вариантов возвращают инвестиции за 1,5-2 года, что для IT-оборудования очень хороший показатель.
Правило третье: подготовьте визуализацию. График роста нагрузки на сервер за последние два года. График увеличения времени отклика системы. Диаграмма, показывающая, как растут расходы на поддержку старого оборудования. Люди лучше воспринимают картинки, чем таблицы с числами.
График 1. Время на обслуживание
Рост нагрузки на сервер за 2 года
Средняя загрузка процессора и время отклика системы
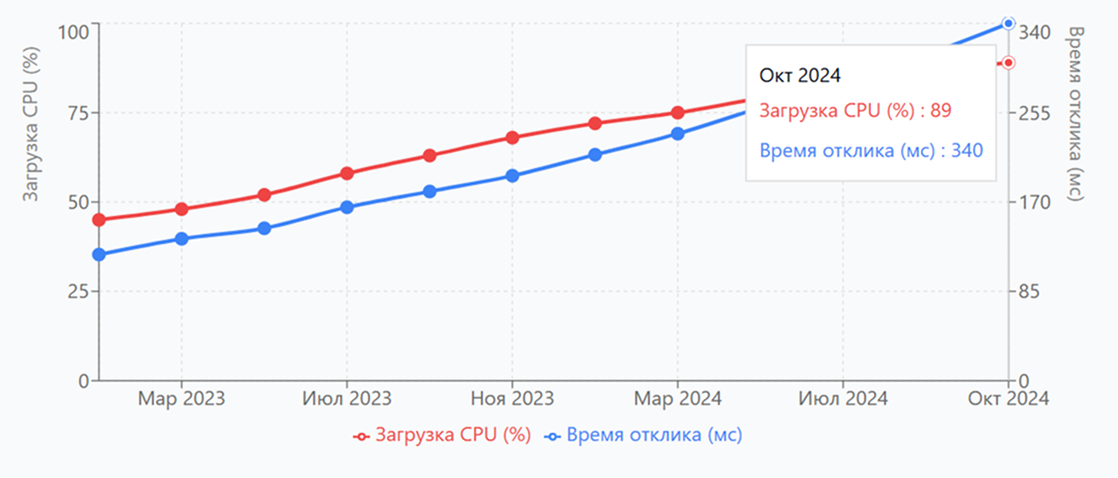
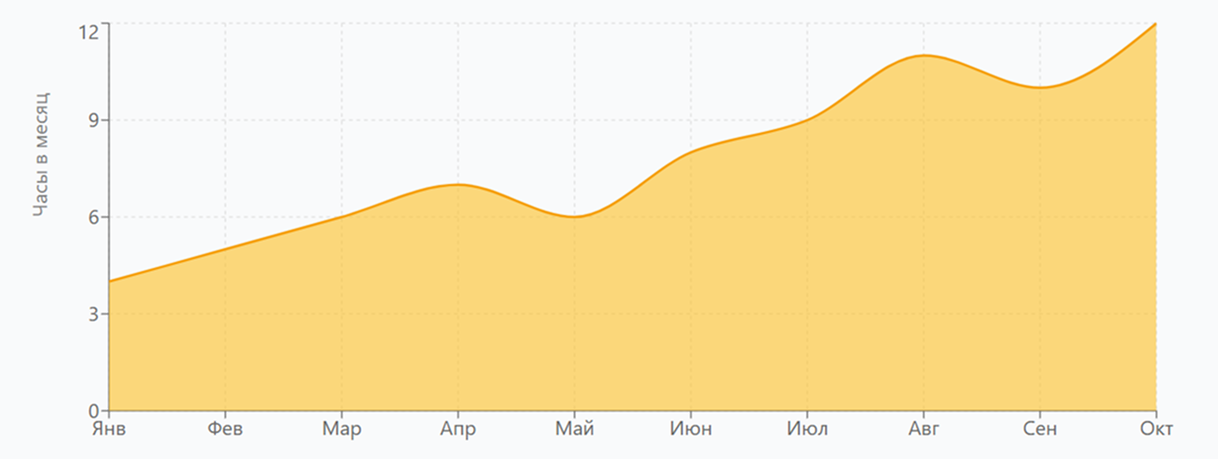
График 2: Время на обслуживание
Рост времени на обслуживание
Часы работы администратора на поддержку сервера в месяц
Правило четвертое: упредите возражения. Знаете, что директор скажет «дорого»? Сразу покажите расчет окупаемости. Знаете, что скажет «подождем»? Покажите график износа с пометкой о растущих рисках отказа. Не ждите вопросов, отвечайте заранее.
И последнее: не приходите с проблемой, приходите с решением. Не «у нас старый сервер, он скоро умрет». А «я подготовил три варианта обновления с расчетом окупаемости, могу презентовать за 15 минут». Почувствуйте разницу?
Собираем доказательную базу
Одна из проблем IT-отдела в том, что работа часто незаметна, пока все работает. Директор не видит, сколько времени вы тратите на поддержание старого сервера на плаву. Начните фиксировать факты.
Ведите журнал инцидентов. Каждый раз, когда сервер тормозит, перезагружается, требует вмешательства, записывайте. Дата, время, суть проблемы, сколько ушло на решение. Через месяц-два у вас будет убедительная статистика. «За последние два месяца было 14 инцидентов, на которые ушло 37 часов рабочего времени».
Собирайте жалобы пользователей. Сотрудники жалуются на медленную работу? Фиксируйте. Клиенты не могут зайти в систему? Записывайте. Это косвенные доказательства того, что инфраструктура не справляется.
Мониторьте метрики производительности правильно. Недостаточно просто смотреть на среднюю загрузку. Если 95-й перцентиль загрузки CPU превышает 80% в рабочие часы в течение 2-4 недель, это серьезный сигнал. Проверьте дополнительные метрики: I/O wait (задержки при обращении к дискам), latency (время отклика), использование swap (признак нехватки оперативной памяти). Рост этих показателей подтверждает, что узкое место постоянное, а не единичный пик от запуска тяжелого отчета. Память забита на 95% и система активно использует swap? Это критичный сигнал. Диски работают на пределе IOPS? Это предвестник отказа. Сохраняйте скриншоты, стройте графики.
Запрашивайте коммерческие предложения. Даже если бюджета пока нет, соберите КП от нескольких поставщиков. Это покажет реальные рыночные цены и даст понимание вариантов. Плюс когда решение будет приниматься, вы сэкономите время.
Эта работа занимает 10-15 минут в неделю. Но через пару месяцев у вас будет железобетонная аргументация, от которой невозможно отмахнуться фразой «пока работает».
Что делать, если бюджета правда нет
Бывает и так: вы все правильно посчитали, убедительно презентовали, но денег в компании действительно нет. Или есть, но они критически нужны на зарплаты, аренду, срочные контракты. Что тогда?
Вариант первый: лизинг или рассрочка. Многие поставщики предлагают растянуть платеж на 12-24 месяца. Вместо 500 000 сразу 25-30 тысяч в месяц. Это психологически легче для бюджета, особенно если компания в кассовом разрыве. Да, переплатите процент, но зато получите оборудование сейчас, а не через год.
Вариант второй: частичное обновление. Не можете купить новый сервер целиком? Купите критичные компоненты: добавьте памяти, замените жесткие диски на SSD, усильте систему охлаждения. Это продлит жизнь на год-полтора и даст время накопить на полноценное обновление. Не идеально, но лучше, чем ничего.
Вариант третий: облачная миграция. Если капитальных затрат нет, но операционные расходы потянуть можно, рассмотрите аренду мощностей. Да, в долгосрочной перспективе облако обычно дороже собственного железа. Но если альтернатива работать на умирающем сервере, облако может быть временным решением.
Вариант четвертый: этапность. Разбейте проект на этапы. Сначала купите один сервер для критичных систем, через квартал второй для менее важных задач. Растяните инвестицию во времени, но начните двигаться уже сейчас.
Пошаговый чек-лист: от идеи до покупки
Информации много, и держать все детали в голове сложно. Особенно когда параллельно нужно тушить текущие пожары, отвечать на звонки пользователей и следить, чтобы старый сервер дожил до конца квартала.
Поэтому мы создали интерактивный чек-лист с визуальным отслеживанием прогресса. Он сохраняет ваше состояние, показывает процент выполнения по каждому этапу и помогает не упустить важные детали.
Как использовать чек-лист:
- Отмечайте выполненные пункты — прогресс сохраняется автоматически
- Следите за процентами — видите, сколько осталось до готовности
- Экспортируйте данные — можно сохранить прогресс в файл
- Фильтруйте задачи — показывайте только то, что еще не сделано
В конце концов, ваша задача как IT-специалиста не только поддерживать инфраструктуру, но и объяснять её ценность на языке, понятном бизнесу. Сервер это инструмент, который либо зарабатывает деньги, либо теряет их. Директор не обязан понимать разницу между RAID 5 и RAID 10. Но он должен понимать разницу между рисками и возможностями. Ваша задача эту разницу показать.







