Кластер серверов: настройка отказоустойчивой системы для вашего бизнеса

- Что такое кластер и почему он не упадет, когда упадет все остальное
- Анатомия отказоустойчивости: из чего состоит надежная система
- Физика против виртуализации: выбираем платформу
- Балансировка как искусство: распределяем нагрузку правильно
- Электричество, сеть и другие слабые места
- Мониторинг и автоматизация: пусть кластер сам о себе позаботится
- Практика применения: где кластеры спасают бизнес
- Масштабирование без головной боли
- Безопасность в распределенной среде
Понедельник, 9 утра. Главный сервер компании внезапно перестает отвечать. Через 3 секунды резервный узел подхватывает всю нагрузку, и никто из сотрудников даже не замечает сбоя. Магия? Нет — грамотно настроенный кластер серверов.
В мире, где час простоя может стоить компании от нескольких тысяч до миллионов рублей, отказоустойчивость перестала быть роскошью. Это базовая необходимость, особенно если ваш бизнес работает с критически важными данными или обслуживает клиентов круглосуточно.
Что такое кластер и почему он не упадет, когда упадет все остальное
Кластер серверов — это группа независимых машин, работающих как единое целое. Представьте команду дублеров в театре: если главный актер заболел, спектакль все равно состоится. Только в IT все происходит автоматически и за считанные секунды.
Отказоустойчивый кластер, или High Availability cluster (HA), постоянно мониторит состояние всех узлов. Когда один сервер выходит из строя — неважно, из-за сбоя оборудования, проблем с питанием или планового обслуживания — остальные узлы мгновенно перераспределяют его задачи между собой.
Но кластеры бывают разными, и каждый тип решает свои задачи:
| Тип кластера | Основная задача | Когда использовать | Пример применения |
|---|---|---|---|
| High Availability (HA) | Обеспечить непрерывность работы | Критически важные системы | База данных 1С, корпоративная почта |
| Load Balancing | Распределить нагрузку | Высоконагруженные сервисы | Интернет-магазин, веб-портал |
| High Performance Computing | Увеличить вычислительную мощность | Сложные расчеты | Рендеринг, научные вычисления |
| Гибридный | Совместить надежность и производительность | Универсальные задачи | Облачные сервисы компании |
Анатомия отказоустойчивости: из чего состоит надежная система
Создание отказоустойчивого кластера похоже на строительство дома. Недостаточно просто соединить несколько серверов кабелем — нужна продуманная архитектура, где каждый элемент выполняет свою роль.
Сердце системы — это механизм heartbeat, постоянный обмен сигналами между узлами. Каждую секунду серверы обмениваются специальными пакетами, подтверждая: "Я жив и работаю". Пропал сигнал? Система немедленно инициирует процедуру переключения.
Данные в кластере хранятся особым образом. Используется либо общее хранилище (SAN/NAS), доступное всем узлам, либо репликация — когда каждое изменение мгновенно копируется на все серверы. Второй вариант дороже, но надежнее: даже если откажет система хранения, данные останутся целыми.
Настройка сервера в кластере требует внимания к деталям. Каждый узел должен иметь идентичную конфигурацию программного обеспечения, синхронизированное время и правильно настроенную сеть. Малейшее расхождение может привести к split-brain — ситуации, когда узлы перестают видеть друг друга и начинают работать независимо, что чревато потерей данных.
Физика против виртуализации: выбираем платформу
Современные кластеры могут строиться как на физических серверах, так и на виртуальных машинах. У каждого подхода свои преимущества.
Физические серверы дают максимальную производительность и предсказуемость. Вы точно знаете, какие ресурсы доступны, и не делите их с соседями по виртуализации. Для высоконагруженных баз данных или систем реального времени это часто единственный вариант.
Виртуальные кластеры выигрывают в гибкости. Добавить новый узел? Пара кликов в консоли управления. Нужно временно увеличить мощность? Просто выделяем больше ресурсов. Такие кластеры идеальны для динамично развивающихся проектов, где нагрузка может резко меняться.
Интересно, что многие компании выбирают гибридный подход: критически важные компоненты размещают на физических серверах, а менее требовательные — виртуализируют. Это дает оптимальный баланс между надежностью и экономией.
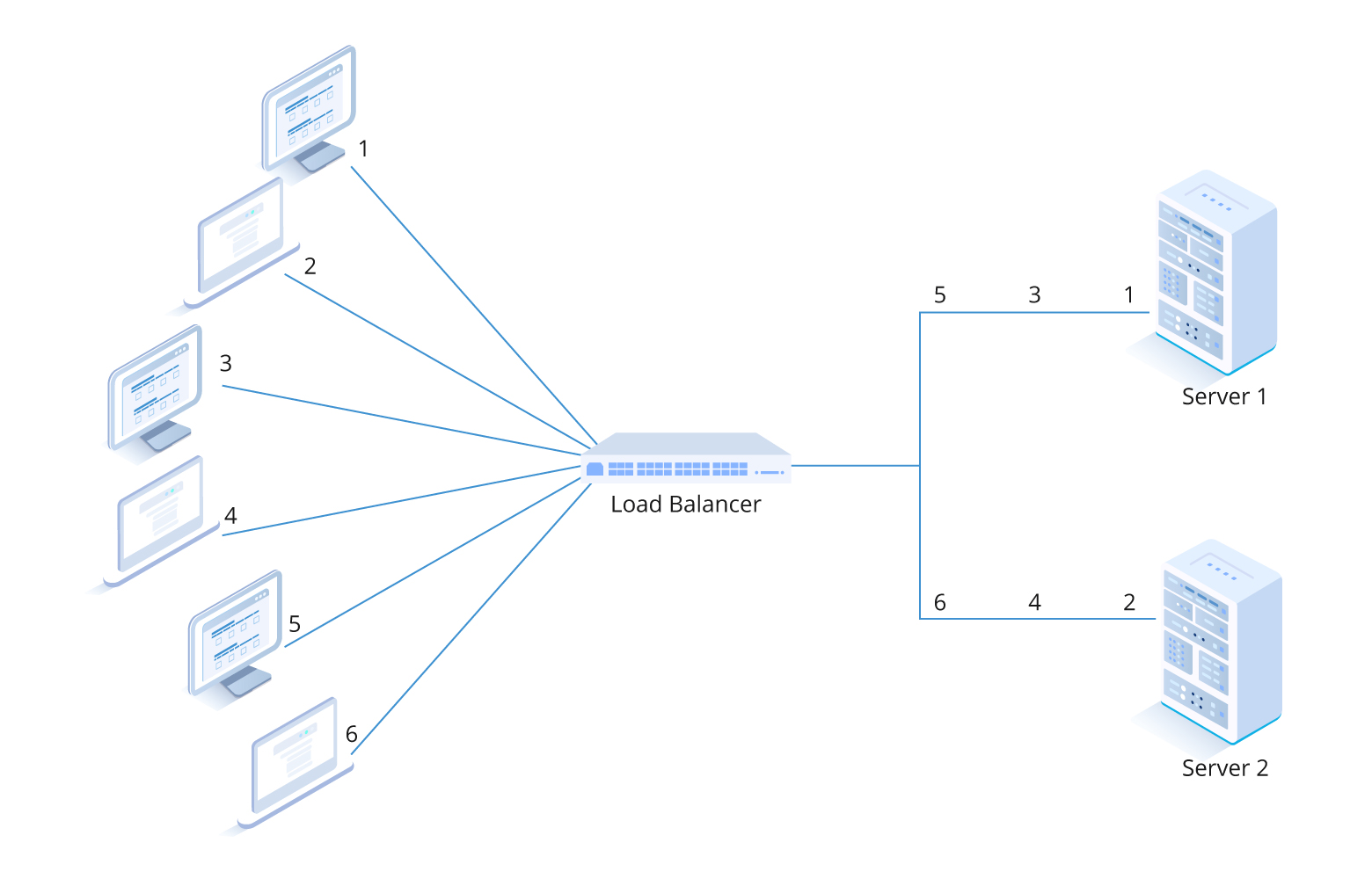
Балансировка как искусство: распределяем нагрузку правильно
Кластер с балансировкой нагрузки работает иначе, чем отказоустойчивый. Здесь все узлы активны одновременно, а специальный балансировщик распределяет запросы между ними.
Алгоритмы распределения бывают разными. Round-robin просто отправляет запросы по кругу — первый на первый сервер, второй на второй, и так далее. Least connections направляет новый запрос на наименее загруженный узел. Weighted distribution учитывает мощность серверов и дает более производительным машинам больше задач.
Правильная настройка балансировки критически важна для производительности. Неверно выбранный алгоритм может привести к ситуации, когда один сервер перегружен, а остальные простаивают. Мониторинг здесь — ваш лучший друг.
Электричество, сеть и другие слабые места
Самый надежный кластер серверов бесполезен, если у вас одна точка отказа в инфраструктуре. Представьте: вы настроили идеальную отказоустойчивость, но все серверы подключены к одному источнику питания. Один сбой — и вся система встает.
Резервирование питания начинается с ИБП (источников бесперебойного питания). Но не просто поставить по ИБП на каждый сервер — нужна схема с резервированием самих ИБП и независимыми линиями электропитания. В идеале — питание от разных подстанций.
Сетевая инфраструктура требует не меньшего внимания. Дублирование сетевых карт, коммутаторов, маршрутизаторов — все это обязательные элементы. Используйте технологии вроде LACP для объединения каналов и VRRP для резервирования шлюзов.
Системы охлаждения часто забывают резервировать, а зря. Перегрев может вывести из строя весь кластер за считанные минуты. Предусмотрите резервные кондиционеры и мониторинг температуры в режиме реального времени.
Мониторинг и автоматизация: пусть кластер сам о себе позаботится
Настроить кластер — половина дела. Важнее обеспечить его стабильную работу месяцами и годами. Здесь на помощь приходят системы мониторинга и автоматизации.
Современные инструменты мониторинга отслеживают сотни параметров: загрузку процессоров, использование памяти, скорость дисковых операций, сетевой трафик, температуру компонентов. При превышении пороговых значений система сама может предпринять корректирующие действия: перераспределить нагрузку, перезапустить зависший процесс или переключиться на резервный узел.
Автоматизация рутинных задач экономит время и снижает риск человеческой ошибки. Резервное копирование, обновление ПО, проверка целостности данных — все это должно происходить по расписанию без участия администратора.
Практика применения: где кластеры спасают бизнес
Финансовый сектор использует кластеры для обработки транзакций. Банковский процессинг не может позволить себе простой даже на минуту — это миллионные убытки и недовольные клиенты. Кластеры обеспечивают обработку тысяч операций в секунду с гарантией доступности 99,999%.
Медицинские учреждения хранят в кластерах электронные карты пациентов и результаты исследований. Потеря доступа к этим данным может стоить человеческих жизней. Отказоустойчивые системы гарантируют, что врач всегда получит нужную информацию.
Системы на платформе 1С — отдельная история. Большинство российских компаний работают в 1С, и простой этой системы парализует весь бизнес. Кластер 1С не только обеспечивает отказоустойчивость, но и позволяет распределить пользователей между серверами, ускоряя работу системы.
Масштабирование без головной боли
Рост бизнеса неизбежно приводит к росту нагрузки на IT-инфраструктуру. Кластерная архитектура позволяет масштабироваться практически без ограничений.
Горизонтальное масштабирование — просто добавляете новые узлы в кластер. Процесс может быть полностью автоматизирован: система сама определяет, когда нужны дополнительные ресурсы, разворачивает новые виртуальные машины и включает их в работу.
Вертикальное масштабирование — увеличение мощности существующих узлов — тоже возможно. В виртуальной среде это делается на лету, для физических серверов потребуется короткое плановое обслуживание. Но благодаря кластерной архитектуре, обновление происходит по одному узлу за раз, без остановки всей системы.

Безопасность в распределенной среде
Кластеры создают дополнительные вызовы для безопасности. Больше узлов — больше потенциальных точек входа для злоумышленников. Синхронизация данных между узлами должна быть зашифрована, иначе конфиденциальная информация может утечь.
Используйте изолированные сети для внутрикластерного трафика. Настройте строгие правила firewall, разрешающие только необходимые соединения. Регулярно обновляйте все компоненты системы — от операционной системы до прикладного ПО.
Резервное копирование в кластерной среде имеет свои особенности. Недостаточно копировать данные с одного узла — нужно обеспечить консистентность backup'а по всему кластеру. Используйте специализированные решения, поддерживающие кластерные конфигурации.
Отказоустойчивые кластеры перестали быть уделом гигантов IT-индустрии. Современные технологии виртуализации и автоматизации сделали их доступными даже для среднего бизнеса. Вопрос не в том, нужен ли вам кластер, а в том, какой именно тип кластера оптимален для ваших задач.
Начните с анализа критичности систем. Что произойдет, если конкретный сервис будет недоступен час? День? Ответ подскажет, где отказоустойчивость необходима в первую очередь. Помните: кластер — это не панацея, а инструмент. Правильно примененный, он станет надежным фундаментом вашей IT-инфраструктуры. Неправильно — дорогой и сложной головной болью.
Технологии развиваются стремительно. То, что вчера требовало команды специалистов и недель настройки, сегодня разворачивается за часы с помощью оркестраторов вроде Kubernetes. Будущее за интеллектуальными самоуправляемыми кластерами, способными предсказывать сбои и предотвращать их до возникновения. Но уже сегодня грамотно построенный кластер серверов — это ваша страховка от незапланированных простоев и потери данных.