Мониторинг производительности приложений на сервере (APM)

Пользователи жалуются на медленную работу корпоративного портала. Разработчики утверждают, что код оптимизирован. Администраторы показывают нормальную загрузку серверов. Знакомая ситуация? Проблема в том, что традиционный мониторинг инфраструктуры не показывает, что происходит внутри приложений. Именно здесь на сцену выходит мониторинг производительности приложений — технология, которая позволяет заглянуть "под капот" программного обеспечения.
Современные приложения — сложные многослойные системы, где запрос пользователя проходит через веб-сервер, обращается к базе данных, вызывает внешние API и возвращает результат. Каждый из этих компонентов может стать узким местом, но без соответствующих инструментов найти проблему — все равно что искать иголку в стоге сена.
Application Performance Monitoring (APM) решает эту задачу, предоставляя детальную информацию о том, как работают приложения в реальном времени. Система отслеживает каждый запрос от момента поступления до момента отправки ответа, измеряет время выполнения отдельных операций и выявляет проблемные участки кода.
Особенно важен грамотный APM для офисных систем, работающих на локальных серверах. Даже базовый сервер для офиса может обслуживать десятки приложений одновременно, и без понимания их взаимодействия сложно обеспечить стабильную работу всей инфраструктуры.
Основы APM: что скрывается за аббревиатурой
Application Performance Monitoring — это методология и набор инструментов для отслеживания производительности программных приложений. В отличие от традиционного мониторинга серверов, который смотрит на метрики железа, APM сосредотачивается на том, как ведут себя сами приложения.
Давайте сравним веб-приложение с многоэтажным зданием. Обычный мониторинг показывает, сколько электричества потребляет здание и какая в нем температура. APM же заглядывает в каждую комнату, считает количество людей на каждом этаже и измеряет, сколько времени занимает подъем на лифте с первого этажа на десятый.
Ключевые задачи APM
Трассировка запросов позволяет проследить путь каждого запроса через всю систему. Когда пользователь нажимает кнопку "Отправить" в веб-форме, APM система фиксирует момент получения запроса веб-сервером, время обработки в приложении, запросы к базе данных, вызовы внешних сервисов и момент отправки ответа обратно пользователю.
Анализ узких мест помогает выявить компоненты системы, которые замедляют общую производительность. Это может быть медленный SQL-запрос, неоптимальный алгоритм или проблемы с сетевым соединением.
Мониторинг пользовательского опыта измеряет реальную производительность с точки зрения конечных пользователей. Система отслеживает время загрузки страниц, частоту ошибок и другие метрики, которые напрямую влияют на удовлетворенность пользователей.
Обнаружение аномалий автоматически выявляет отклонения от нормального поведения приложений. Система может заметить, что обычно быстрый API-вызов начал выполняться в два раза дольше, даже если это время все еще находится в допустимых пределах.
Архитектура современных APM систем
Эффективная APM система состоит из нескольких взаимосвязанных компонентов, каждый из которых выполняет свою специфическую роль.
Агенты приложений — это программные модули, которые встраиваются в код приложения или работают на уровне среды выполнения. Они собирают данные о производительности непосредственно из работающего приложения, практически не влияя на его производительность.
Современные агенты используют технологии byte code instrumentation, которые позволяют автоматически внедрять код мониторинга в уже скомпилированные приложения. Это означает, что во многих случаях для начала мониторинга достаточно просто подключить агент к приложению без изменения исходного кода.
Коллекторы данных собирают информацию от всех агентов в инфраструктуре и выполняют первичную обработку. Они агрегируют метрики, фильтруют шум и подготавливают данные для дальнейшего анализа. Коллекторы часто работают по принципу sampling — они анализируют не каждый запрос подряд, а статистически репрезентативную выборку, что снижает нагрузку на систему.
Аналитический движок обрабатывает собранные данные, строит временные ряды метрик, выявляет тренды и аномалии. Здесь применяются сложные математические модели и алгоритмы машинного обучения для автоматического обнаружения проблем.
Интерфейсы визуализации представляют данные в удобном для анализа виде. Современные APM решения предлагают интерактивные дашборды, где можно drill-down от общих метрик до деталей конкретного запроса.
APM сервер: центральная точка управления
Центральный сервер APM системы выполняет роль координатора всей инфраструктуры мониторинга. Он принимает данные от распределенных агентов, обеспечивает их хранение и предоставляет интерфейсы для анализа.
Требования к серверу APM довольно специфичны. Система должна обрабатывать большие объемы временных данных в реальном времени, поэтому важны быстрые диски и достаточный объем оперативной памяти. Сетевая подсистема тоже играет критическую роль — агенты постоянно отправляют данные на центральный сервер.
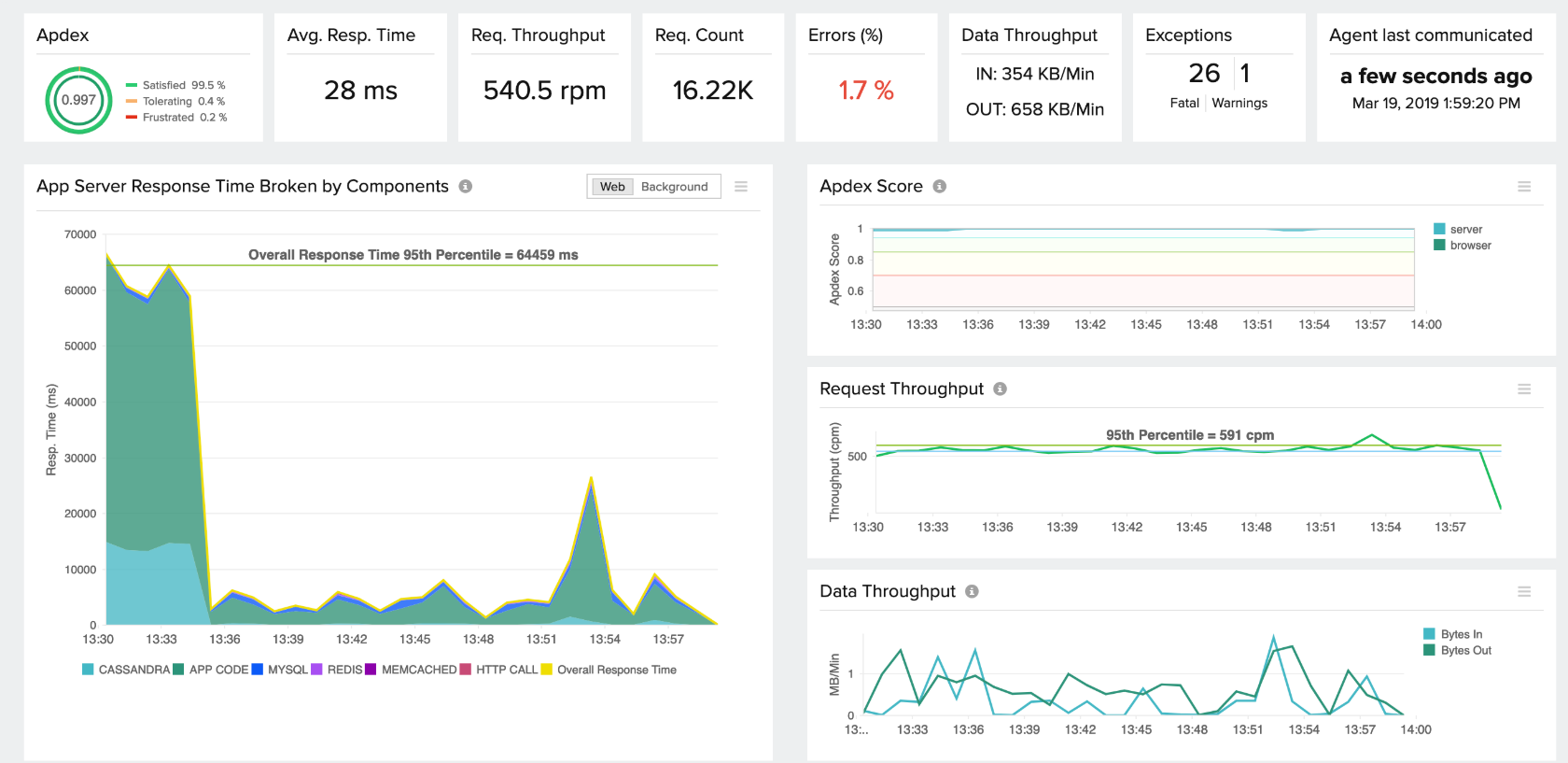
Ключевые метрики производительности
Понимание того, какие метрики действительно важны, определяет эффективность всей системы мониторинга. Не все показатели одинаково полезны для диагностики проблем.
Метрики времени отклика
Response Time — основная метрика пользовательского опыта. Однако важно понимать разницу между средним временем отклика и процентилями. Среднее значение может скрывать проблемы, затрагивающие небольшой процент пользователей. 95-й процентиль показывает, что 95% запросов выполняются быстрее указанного времени, а 5% — медленнее.
Time to First Byte (TTFB) измеряет время от отправки запроса до получения первого байта ответа. Эта метрика особенно важна для веб-приложений, поскольку показывает скорость обработки запроса на сервере без учета времени передачи данных.
Database Response Time отслеживает время выполнения запросов к базе данных. Медленные SQL-запросы — частая причина проблем с производительностью, и их выявление критически важно для оптимизации.
Метрики пропускной способности
Throughput показывает количество запросов, обрабатываемых системой в единицу времени. Эта метрика помогает понять масштаб нагрузки и планировать ресурсы.
Concurrent Users отслеживает количество одновременно активных пользователей. Важно понимать разницу между общим количеством сессий и реально активными пользователями в данный момент.
Метрики ошибок
Error Rate измеряет процент неуспешных запросов. APM системы классифицируют ошибки по типам: HTTP 4xx (ошибки клиента), HTTP 5xx (ошибки сервера), исключения в коде приложения.
Mean Time to Detection (MTTD) показывает, как быстро система обнаруживает проблемы. Чем меньше это время, тем быстрее команда может отреагировать на инцидент.
Технологии распределенной трассировки
Современные приложения редко работают изолированно. Обычный веб-запрос может пройти через несколько микросервисов, обратиться к различным базам данных и внешним API. Распределенная трассировка позволяет отследить весь этот путь.
Trace ID — уникальный идентификатор, который присваивается каждому запросу и передается через все компоненты системы. Это позволяет объединить разрозненные логи и метрики в единую картину.
Span представляет отдельную операцию внутри трассировки. Каждый span имеет время начала, время завершения и может содержать дополнительные метаданные. Spans организованы в иерархическую структуру, отражающую последовательность вызовов.
Современные стандарты, такие как OpenTelemetry, обеспечивают совместимость между различными APM решениями и упрощают инструментирование приложений.
Sampling и производительность
Трассировка каждого запроса может создать значительную нагрузку на систему и привести к накоплению огромных объемов данных. Поэтому APM системы используют различные стратегии sampling.
Head-based sampling принимает решение о трассировке в начале запроса на основе предопределенных правил. Например, можно трассировать каждый 100-й запрос или все запросы от определенных пользователей.
Tail-based sampling анализирует полную трассировку и решает, сохранять ее или нет, на основе результатов выполнения. Это позволяет сохранить все трассировки с ошибками и случайную выборку успешных запросов.
Adaptive sampling динамически изменяет частоту трассировки в зависимости от текущей нагрузки и важности различных частей системы.
Выбор APM решения
Рынок APM решений предлагает множество вариантов — от enterprise платформ до open-source инструментов. Выбор зависит от специфики инфраструктуры, бюджета и требований к функциональности.
Enterprise решения предлагают богатую функциональность из коробки, профессиональную поддержку и интеграцию с существующими корпоративными системами. Они обычно включают автоматическое обнаружение приложений, готовые дашборды для популярных технологий и продвинутые возможности анализа.
Open-source инструменты дают больше гибкости и контроля, но требуют значительных усилий на настройку и поддержку. Такие решения подходят командам с глубокой технической экспертизой и специфическими требованиями.
Cloud-native платформы оптимизированы для современных микросервисных архитектур и контейнерных развертываний. Они автоматически интегрируются с Kubernetes, Docker и другими облачными технологиями.
Критерии выбора
Поддержка технологий — первый фактор для рассмотрения. APM решение должно иметь готовые агенты для всех используемых в организации языков программирования и фреймворков.
Масштабируемость критически важна для растущих инфраструктур. Система должна справляться с увеличением нагрузки без значительного снижения производительности.
Интеграция с существующими инструментами упрощает внедрение и повышает эффективность. APM система должна интегрироваться с системами мониторинга инфраструктуры, инструментами CI/CD и платформами управления инцидентами.
Стоимость владения включает не только лицензии, но и затраты на развертывание, обучение команды и ongoing поддержку.

Процесс внедрения APM
Успешное внедрение APM — это не разовая задача, а процесс, который требует планирования и координации между различными командами.
Инвентаризация приложений — первый шаг к пониманию масштаба задачи. Нужно составить список всех приложений, их технологического стека, критичности для бизнеса и текущих проблем с производительностью.
Пилотный проект позволяет получить первый опыт работы с APM и продемонстрировать ценность технологии. Лучше всего выбрать приложение средней сложности с известными проблемами производительности — это даст возможность быстро показать результат.
Инструментирование приложений может потребовать изменений в коде или конфигурации. Современные агенты APM стараются минимизировать эти изменения, но полностью избежать их удается не всегда.
Обучение команды — критически важный аспект внедрения. Разработчики должны понимать, как интерпретировать данные APM и использовать их для оптимизации кода. Операционная команда должна уметь настраивать алерты и реагировать на проблемы производительности.
Настройка алертов и порогов
Грамотная настройка системы оповещений определяет эффективность APM в операционной деятельности. Слишком много алертов приводит к "усталости от уведомлений", слишком мало — к пропуску важных проблем.
Baseline метрики нужно установить для каждого приложения индивидуально. Нормальное время отклика для простого API может составлять 50 миллисекунд, а для сложного отчета — несколько секунд.
Процентильные пороги часто более полезны, чем средние значения. Алерт на 95-й процентиль времени отклика покажет проблемы, затрагивающие небольшую группу пользователей, которые могут остаться незамеченными при анализе средних значений.
Корреляционные алерты учитывают взаимосвязи между различными метриками. Например, рост времени отклика в сочетании с увеличением нагрузки на базу данных может указывать на проблемы с SQL-запросами.
Анализ и оптимизация производительности
Сбор данных — только начало процесса. Главная ценность APM заключается в способности превращать эти данные в actionable insights для улучшения производительности приложений.
Анализ трендов показывает, как изменяется производительность приложений со временем. Постепенное увеличение времени отклика может указывать на проблемы с памятью, рост объемов данных или деградацию производительности базы данных.
Корреляционный анализ помогает выявить связи между различными метриками. Например, можно обнаружить, что время отклика API увеличивается при росте количества одновременных пользователей, что указывает на проблемы с масштабируемостью.
Сравнительный анализ различных версий приложения позволяет оценить влияние изменений кода на производительность. APM системы могут автоматически сравнивать метрики до и после развертывания новой версии.
Оптимизация на основе данных
APM данные предоставляют конкретные направления для оптимизации производительности. Вместо общих рекомендаций типа "оптимизируйте базу данных" система показывает конкретные медленные запросы и проблемные участки кода.
Оптимизация SQL-запросов часто дает максимальный эффект при минимальных усилиях. APM системы показывают не только время выполнения запросов, но и планы их выполнения, что помогает выявить отсутствующие индексы или неэффективные join'ы.
Кэширование — еще одна популярная стратегия оптимизации. APM данные помогают определить, какие операции выполняются наиболее часто и могут выиграть от кэширования.
Асинхронная обработка позволяет вынести длительные операции из основного потока обработки запросов. APM показывает, какие операции занимают больше всего времени и могут быть кандидатами для асинхронного выполнения.
Мониторинг производительности приложений превратился из "nice to have" в критически важный компонент современных IT-операций. Без понимания того, как ведут себя приложения, сложно обеспечить качественный пользовательский опыт и эффективно использовать ресурсы инфраструктуры.







