Проблемы производительности в виртуализированных средах и их решение

- Пять главных убийц производительности
- Синдром шумного соседа
- VM Sprawl — когда виртуалок слишком много
- Невидимый налог гипервизора
- Проблема переподписки ресурсов
- Слепые зоны мониторинга
- Как вернуть скорость вашим виртуальным машинам
- Правильное распределение ресурсов
- Оптимизация ввода-вывода
- NUMA и правильная работа с памятью
- Автоматизация и профили оптимизации
- Защита без жертв
- Мониторинг — ваши глаза в виртуальном мире
Представьте: понедельник, 9 утра, ваш критически важный сервис работает в три раза медленнее обычного. Мониторинг показывает, что с виртуальной машиной всё в порядке — CPU загружен на 40%, памяти хватает, диски не перегружены. Но приложение еле шевелится. Знакомо? Вы столкнулись с одной из классических проблем производительности виртуализации, которые мучают IT-инфраструктуры по всему миру.
По данным VMware, до 70% компаний регулярно сталкиваются с деградацией производительности в виртуализированных средах, при этом на поиск причин уходит в среднем 4-6 часов рабочего времени специалистов. А теперь умножьте эти часы на зарплату сисадмина и добавьте потери от простоя бизнес-процессов — цифры получаются впечатляющие.
Пять главных убийц производительности
Виртуализация — штука коварная. Вроде бы всё настроено правильно, железо мощное, а система работает как старенький Pentium. Давайте разберем основные причины, почему ваши ВМ могут тормозить, даже когда ресурсов вроде бы достаточно.
Синдром шумного соседа
Это как жить в коммуналке — соседская ВМ внезапно решила пересчитать всю базу данных или запустить антивирусную проверку, и ваше приложение начинает задыхаться. В одном физическом сервере несколько виртуальных машин конкурируют за общие ресурсы, и если одна из них становится слишком прожорливой, остальные начинают голодать.
Реальный кейс: крупный интернет-магазин потерял 15% конверсии из-за того, что на том же хосте крутилась система аналитики, которая каждый час запускала тяжелые отчеты. Покупатели не готовы ждать загрузку страницы больше 3 секунд — они просто уходят к конкурентам.
VM Sprawl — когда виртуалок слишком много
Виртуальные машины размножаются быстрее, чем вы успеваете их документировать. Разработчики создают тестовые среды и забывают их удалить, менеджеры требуют отдельные ВМ для каждого проекта, а в итоге у вас работает 200 виртуалок вместо необходимых 50.
Это не просто беспорядок — каждая лишняя ВМ съедает ресурсы гипервизора на управление, даже если она простаивает. Плюс усложняется диагностика: попробуйте найти проблемную ВМ среди сотни других, когда все они названы vm-test-01, vm-test-02 и так далее.
Невидимый налог гипервизора
Гипервизор — это не волшебная палочка, которая бесплатно делит железо между виртуальными машинами. Он сам потребляет от 5 до 15% вычислительных ресурсов на свою работу. Для преобразования виртуальных адресов в физические, эмуляцию устройств и управление памятью нужны циклы процессора.
| Операция | Потери производительности | Влияние на бизнес |
|---|---|---|
| CPU-виртуализация | 5-10% | Увеличение времени обработки запросов |
| Эмуляция ввода-вывода | 10-20% | Замедление работы с базами данных |
| Управление памятью | 3-7% | Задержки при переключении контекста |
| Сетевая виртуализация | 5-15% | Увеличение латентности API |
Проблема переподписки ресурсов
Overcommitment — это когда вы обещаете виртуальным машинам больше, чем есть на самом деле. Выделили 10 ВМ по 8 ГБ памяти на сервере с 64 ГБ? Пока все не работают одновременно — всё хорошо. Но стоит нагрузке вырасти, и начинается своппинг, который превращает вашу инфраструктуру в улитку.
Особенно опасна переподписка CPU. Когда виртуальных процессоров больше, чем физических ядер, планировщик гипервизора начинает жонглировать задачами, создавая дополнительные задержки. В критических системах это может привести к тайм-аутам и потере данных.
Слепые зоны мониторинга
В физическом сервере проблему найти относительно просто — посмотрел метрики и понял, что тормозит. В виртуализированной среде у вас минимум три слоя: физический хост, гипервизор и гостевая ОС. И проблема может быть на любом из них.
Без правильно настроенного мониторинга вы будете искать проблему вслепую. Гостевая ОС показывает свободную память, но на уровне гипервизора идет активный своппинг. Или виртуальный CPU загружен на 100%, а физические ядра при этом простаивают — просто планировщик не может эффективно распределить нагрузку.
Как вернуть скорость вашим виртуальным машинам
Теперь, когда мы знаем врага в лицо, давайте разберем конкретные методы оптимизации ВМ. Спойлер: волшебной кнопки "сделать всё быстро" не существует, но есть проверенные практики, которые реально работают.
Правильное распределение ресурсов
Первое правило — не жадничайте с железом. Если ваш бизнес зависит от производительности приложений, экономия на серверах выйдет боком. Оптимальная загрузка физических хостов — 60-70%. Это даёт запас для пиковых нагрузок и предотвращает деградацию при сбоях.
Используйте резервирование ресурсов для критичных ВМ. Да, это снижает плотность виртуализации, но гарантирует стабильную работу важных сервисов. Настройте Resource Pools с разными приоритетами — пусть тестовые среды страдают первыми, а продакшн получает ресурсы в приоритете.
Оптимизация ввода-вывода
Диски и сеть — главные узкие места в виртуализации. Для улучшения дисковой производительности используйте:
- Paravirtual SCSI вместо эмулируемых контроллеров — это даст прирост до 30% в операциях ввода-вывода
- Выделенные LUN для баз данных и других I/O-интенсивных приложений
- SSD-кэширование для часто используемых данных — даже небольшой SSD-кэш может кардинально улучшить отзывчивость
Для сетевой оптимизации внедрите SR-IOV — технология позволяет виртуальным машинам напрямую работать с сетевой картой, минуя гипервизор. В высоконагруженных системах это может снизить латентность в 2-3 раза.
NUMA и правильная работа с памятью
Современные серверы используют архитектуру NUMA, где память физически привязана к определённым процессорам. Если виртуальная машина обращается к "чужой" памяти, производительность падает на 20-30%.
Настройте NUMA-affinity для критичных ВМ — привяжите их к конкретным NUMA-нодам. Используйте Huge Pages для уменьшения overhead на управление памятью. Для Java-приложений и баз данных это может дать прирост производительности до 15%.
Автоматизация и профили оптимизации
Ручная настройка сотен виртуалок — путь в никуда. Используйте профили оптимизации под разные типы нагрузок:
- Latency-sensitive для приложений реального времени
- Throughput для batch-обработки
- Desktop для VDI-инфраструктуры
Внедрите автоматическое перераспределение ресурсов с помощью DRS (Distributed Resource Scheduler) или аналогов. Система сама будет мигрировать ВМ между хостами для балансировки нагрузки.
Защита без жертв
Отдельная головная боль — антивирусы в виртуальной среде. Представьте: 50 виртуалок одновременно запускают сканирование по расписанию. Storage начинает плакать кровавыми слезами, а пользователи — звонить в техподдержку.
Решение — использовать безагентную защиту на уровне гипервизора. Один антивирусный модуль проверяет все ВМ, не нагружая каждую из них отдельным агентом. Это экономит 5-10% CPU на каждой виртуальной машине и существенно снижает нагрузку на диски.
Если агентная защита необходима, настройте исключения для виртуальных дисков и системных файлов гипервизора. И обязательно разнесите расписание сканирования — пусть ВМ проверяются по очереди, а не все разом.
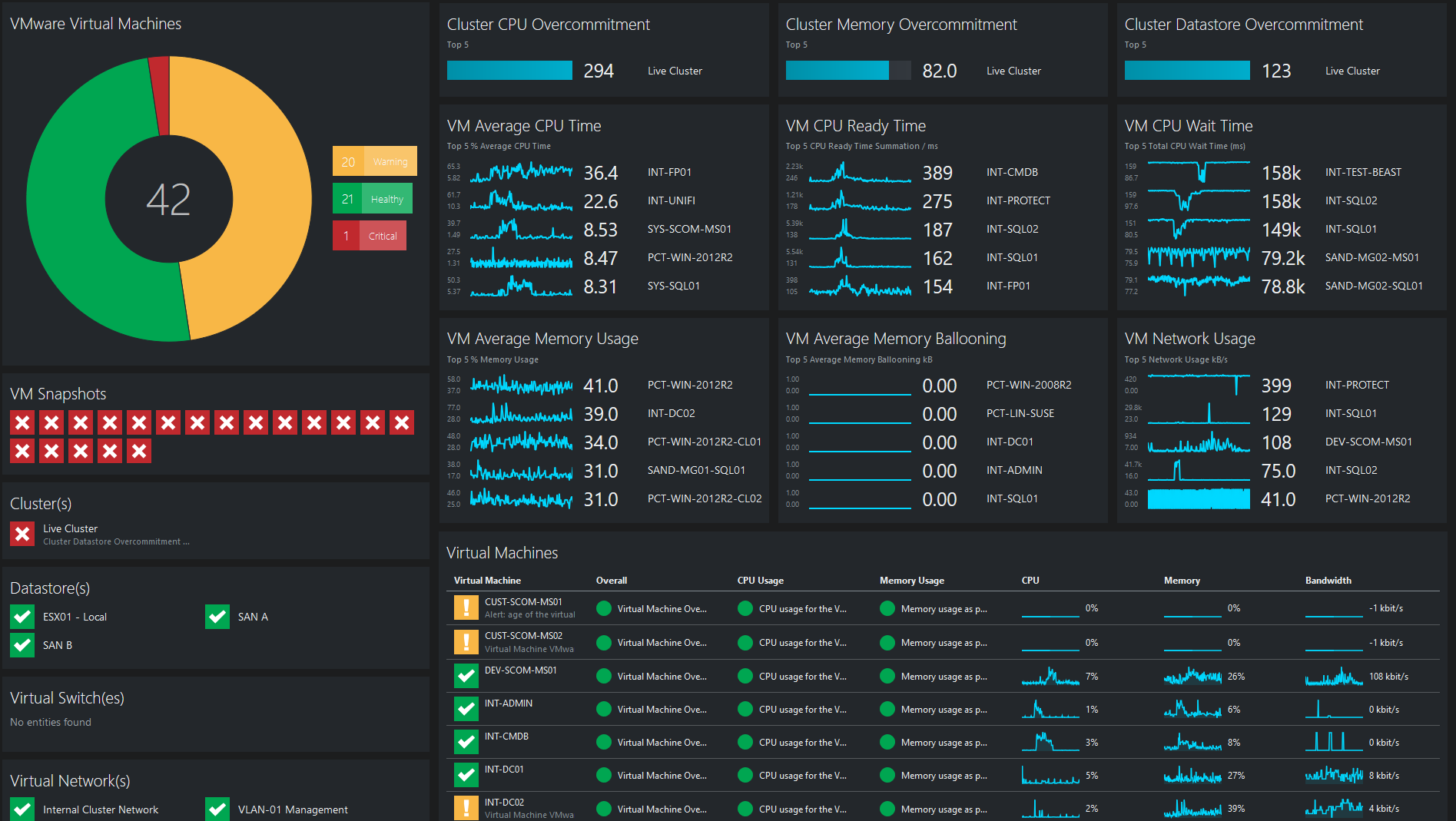
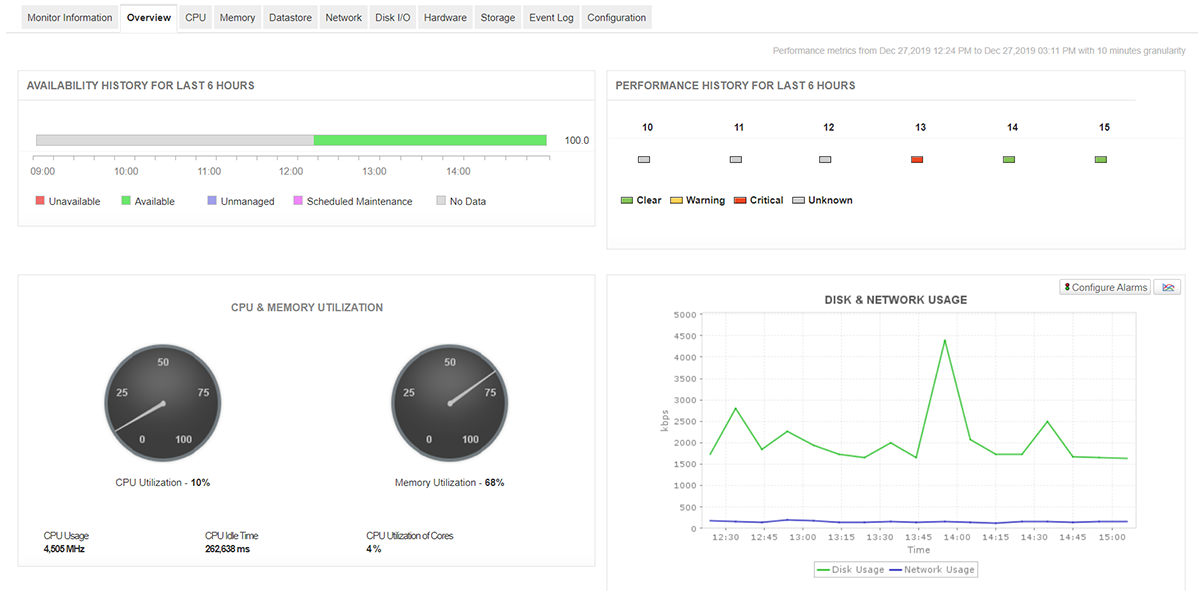
Мониторинг — ваши глаза в виртуальном мире
Без правильного мониторинга оптимизация ВМ превращается в гадание на кофейной гуще. Вам нужно видеть метрики на всех уровнях:
Физический уровень: температура, загрузка CPU, память, диски, сеть
Уровень гипервизора: CPU Ready, Memory Ballooning, SWAP, Co-Stop
Гостевые ОС: метрики приложений, время отклика, очереди
Настройте алерты на критичные показатели. CPU Ready больше 10%? Пора добавлять ядра или уменьшать количество ВМ на хосте. Memory Ballooning активен? Проверьте распределение памяти. Co-Stop растёт? Проблемы с планировщиком vCPU.
Взгляд в будущее
Виртуализация продолжает развиваться. Контейнеры и Kubernetes постепенно вытесняют классические ВМ для микросервисных архитектур. Но для legacy-приложений и систем, требующих полной изоляции, виртуальные машины останутся актуальными ещё долго.
Проблемы производительности виртуализации — это не приговор, а вызов, который можно и нужно решать. Главное — подходить к вопросу системно: правильно планировать ресурсы, использовать современные технологии оптимизации и не забывать про мониторинг.
Помните: каждый процент улучшения производительности — это не просто цифры в отчёте. Это довольные пользователи, которые не ждут загрузки страниц. Это разработчики, которые быстрее деплоят код. Это бизнес, который работает без сбоев. И да, это спокойный сон системного администратора, которого не будят в 3 часа ночи с криком "всё упало!"
Виртуализация — мощный инструмент, но как любой инструмент, она требует умелого обращения. Инвестируйте время в изучение и настройку, и ваши виртуальные машины отблагодарят вас стабильной и быстрой работой.







