Репликация данных между системами хранения: настройка и сценарии применения

- Почему репликация — это не резервное копирование
- Физическая, логическая и триггерная: выбираем подход
- Синхронная vs асинхронная: вечная дилемма скорости и надежности
- Топологии: кто главный в оркестре данных
- Настройка: дьявол в деталях
- Практические сценарии: от e-commerce до больших данных
- Современный инструментарий
- Что дальше?
Вы когда-нибудь задумывались, почему банковская транзакция отражается в мобильном приложении мгновенно, даже если основной дата-центр находится за тысячи километров? Или почему интернет-магазин продолжает работать, когда половина серверов выходит из строя? Ответ кроется в технологии, которая незаметно работает в основе практически всех критически важных систем — репликации данных.
Репликация схд — это не просто создание копий. Это целая философия построения отказоустойчивых систем, где данные существуют одновременно в нескольких местах, постоянно синхронизируясь между собой. В отличие от резервного копирования, которое создает снимки данных на определенный момент времени, репликация поддерживает актуальность информации в режиме реального времени или близком к нему.
Почему репликация — это не резервное копирование
Многие путают эти понятия, и это приводит к дорогостоящим ошибкам при проектировании инфраструктуры. Резервная копия — это страховка на случай катастрофы. Вы восстанавливаете данные на момент последнего бэкапа и теряете все изменения после него. Репликация же создает живую, работающую копию, готовую мгновенно подхватить нагрузку при сбое основной системы.
Представьте интернет-магазин в "черную пятницу". Если основная база данных упадет, переключение на реплику займет секунды, и покупатели даже не заметят проблемы. С резервной копией вы потеряете все заказы за последние часы и проведете ночь, восстанавливая систему.
Физическая, логическая и триггерная: выбираем подход
Синхронизация хранилищ данных может происходить на разных уровнях, и выбор метода критически влияет на производительность и возможности системы.
Физическая репликация копирует данные блок за блоком, как будто вы делаете точную копию жесткого диска. Это быстро, эффективно, но негибко — реплика должна быть идентична источнику вплоть до версии операционной системы. Идеально для создания горячего резерва, но не подходит, если нужно реплицировать только часть данных или между разными платформами.
Логическая репликация работает на уровне изменений в базе данных — она понимает, что именно изменилось, и передает эту информацию. Вы можете реплицировать отдельные таблицы, фильтровать данные, даже трансформировать их на лету. Цена такой гибкости — дополнительная нагрузка на процессор и более сложная настройка.
Триггерная репликация — самый гибкий, но и самый ресурсоемкий метод. При каждом изменении срабатывает программный код, который решает, что и куда реплицировать. Это позволяет реализовать сложную бизнес-логику прямо в процессе репликации, но может существенно замедлить систему при большом потоке изменений.
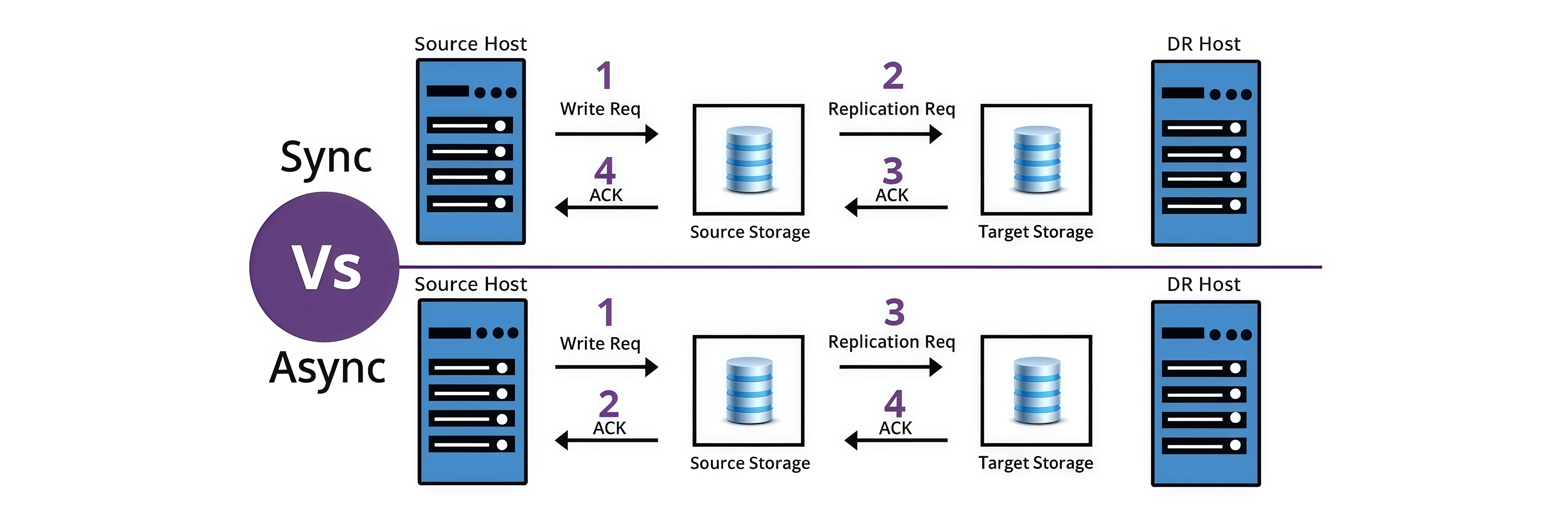
Синхронная vs асинхронная: вечная дилемма скорости и надежности
Выбор режима синхронизации — это всегда компромисс. Синхронная репликация гарантирует, что данные записаны во все системы одновременно. Транзакция считается завершенной только после подтверждения от всех реплик. Звучит надежно? Безусловно. Но есть нюанс — скорость работы определяется самым медленным звеном в цепи.
Банки часто используют синхронную репликацию для критически важных операций. Когда вы переводите деньги, система дожидается подтверждения записи во всех дата-центрах. Да, операция займет на долю секунды больше, зато исключена ситуация, когда деньги списались, но не пришли получателю из-за сбоя.
Асинхронная репликация работает по принципу "отправил и забыл". Основная система не ждет подтверждения от реплик, что дает высокую скорость работы. Социальные сети и стриминговые сервисы предпочитают именно этот метод — лучше показать пост с небольшой задержкой в другом регионе, чем замедлить работу для всех пользователей.
Существует и гибридный подход — полусинхронная репликация. Система ждет подтверждения хотя бы от одной реплики, а остальные синхронизируются асинхронно. Это дает баланс между надежностью и производительностью.
Топологии: кто главный в оркестре данных
Архитектура репликации определяет, как системы взаимодействуют друг с другом. Классическая схема master-slave проста и предсказуема: один сервер принимает все изменения, остальные только читают. Это решает проблему конфликтов — нет споров о том, какая версия данных правильная.
Но что если мастер упадет? Нужно быстро выбрать нового лидера из реплик, и здесь начинаются сложности. Какая реплика самая актуальная? Как избежать split-brain, когда два сервера считают себя мастерами?
Топология master-master позволяет писать данные в любой узел. Звучит удобно, особенно для географически распределенных систем. Офис в Москве работает со своим мастером, офис в Екатеринбурге — со своим, данные синхронизируются между ними. Но конфликты неизбежны: что делать, если один и тот же документ одновременно изменили в двух местах?
Каскадная репликация создает иерархию: мастер реплицирует на первый уровень реплик, те в свою очередь — на второй уровень. Это снижает нагрузку на основной сервер, но увеличивает задержку распространения изменений до конечных узлов.
Настройка: дьявол в деталях
Техническая настройка репликации схд начинается с оценки пропускной способности сети. Сколько данных изменяется в единицу времени? Хватит ли канала для синхронной репликации? Многие недооценивают этот момент и сталкиваются с растущей задержкой репликации.
На уровне систем хранения нужно настроить снэпшоты и журналирование изменений. Современные СХД поддерживают репликацию на уровне железа — это быстро и не нагружает серверы, но привязывает к конкретному вендору. Программная репликация универсальнее, но требует ресурсов сервера.
Мониторинг репликации — отдельная история. Недостаточно знать, что репликация работает. Важно отслеживать задержку (replication lag), размер очереди изменений, количество конфликтов. Растущая задержка — первый признак проблем, которые лучше решить до того, как они станут критичными.
Практические сценарии: от e-commerce до больших данных
В электронной коммерции репликация решает задачу географического распределения. Покупатели из Владивостока получают данные с ближайшего сервера, не дожидаясь ответа из Москвы. При этом критичные данные (остатки товара, заказы) синхронизируются в реальном времени, а каталог товаров может обновляться асинхронно.
Аналитические системы используют репликацию для разделения OLTP и OLAP нагрузки. Оперативная система обрабатывает транзакции, а её реплика используется для построения отчетов и аналитики. Это позволяет запускать тяжелые запросы без влияния на производительность основной системы.
В больших данных репликация обеспечивает не только отказоустойчивость, но и локальность вычислений. Hadoop по умолчанию хранит три копии каждого блока данных, размещая их на разных узлах. Это позволяет обрабатывать данные там, где они физически находятся, минимизируя сетевой трафик.

Современный инструментарий
Выбор инструментов для синхронизации хранилищ данных зависит от используемых технологий. PostgreSQL предлагает встроенную потоковую репликацию с возможностью создания каскадных схем. MySQL традиционно силен в master-slave репликации, а Galera Cluster добавляет возможности multi-master.
Для гетерогенных окружений существуют специализированные решения. Apache Kafka стал стандартом для репликации потоков данных между разными системами. Debezium превращает изменения в базах данных в события, которые можно обрабатывать и маршрутизировать гибко.
Облачные провайдеры предлагают управляемые сервисы репликации. AWS Database Migration Service может реплицировать данные между разными типами баз данных с минимальными простоями. Azure SQL Database автоматически создает геореплики для критичных данных.
Что дальше?
Репликация данных эволюционирует вместе с требованиями бизнеса. Edge computing требует репликации на тысячи узлов с минимальной задержкой. Blockchain предлагает новый взгляд на распределенную репликацию с криптографическими гарантиями целостности. Квантовые вычисления обещают мгновенную синхронизацию через квантовую запутанность — хотя это пока больше похоже на научную фантастику.
Главное помнить: репликация — это инструмент, а не самоцель. Прежде чем настраивать сложные схемы синхронизации, определите, какие проблемы вы решаете. Иногда простого резервного копирования достаточно, а иногда даже самая продвинутая репликация не спасет от плохо спроектированной архитектуры. Технологии меняются, но принцип остается неизменным — данные должны быть доступны тогда и там, где они нужны бизнесу







