Серверы для ИИ: как выбрать и собрать под реальные задачи


- Графические ускорители — рабочая лошадка сервера для ИИ
- Классы профессиональных GPU NVIDIA
- Оперативная память для сервера с ИИ
- Хранилище данных — библиотека для знаний ИИ
- Серверные платформы для ИИ: какие бывают, и чем отличаются
- Решения от NVIDIA: DGX и HGX
- Универсальные платформы
- Конфигурация сервера для ИИ: что еще нужно учесть при сборке
- Система охлаждения
- Кластеризация и распределение вычислений
- Совместимость с профильным ПО
- Питание
- Эксплуатация и поддержка ИИ-серверов: как наладить работу без лишних проблем
- Виртуализация и распределение ресурсов
- Готовые конфигурации под конкретные задачи
- Генераторы кода для небольших моделей
- Генераторы кода для крупных моделей
- Компьютерное зрение
- Сервер для обучения моделей
- Итог: как выбрать сервер для ИИ, чтобы не обжечься
Искусственный интеллект стал повседневным рабочим инструментом для любого бизнеса. Но для стабильной и надежной работы этого инструмента необходимо соответствующее «железо».
При выборе подходящего сервера для ИИ, нужно учесть, что он должен позволять решать 3 главные задачи:
- Обучение;
- Развертывание;
- Инференс (непосредственно работа с запросами пользователей).
Обучение требует огромного объема данных, которые нужно «переварить». На этом этапе все упирается в скорость работы с данными. Сервер для ИИ должен иметь большой объем дискового пространства для хранения датасетов и при этом работать с данными достаточно быстро, чтобы обучение занимало приемлемое количество времени.
Но дисковое пространство — это еще не все. Критически важен объем видеопамяти GPU. В идеале модель должна полностью загружаться в видеопамять ускорителя — это обеспечивает максимальную скорость работы. Современные большие языковые модели могут требовать от 24 ГБ до нескольких сотен гигабайт видеопамяти.
А что делать, если ИИ-модель не влезает в память одной видеокарты? Здесь на помощь приходит NVLink — высокоскоростной интерфейс от NVIDIA, который объединяет несколько GPU в единый пул когерентной памяти. Благодаря NVLink графические ускорители могут напрямую обращаться к памяти друг друга со скоростью до 1800 ГБ/с (это в 7 раз быстрее, чем через PCIe 6.0). Данные передаются между GPU напрямую, минуя шину PCIe, что критично для обучения больших моделей.
С инференсом тоже все не так просто. Если вы хотите получать ответы от нейросети быстро, то «железо» должно быть достаточно мощным. В основном скорость инференса зависит от мощности GPU, именно он обрабатывает запросы от пользователей.
А для такого мощного оборудования потребуется мощная система охлаждения, соответствующее питание, быстрая сеть, много оперативной памяти и т.д.
Мы расскажем о ключевых компонентах сервера для ИИ, объясним, в чем особенность платформ для ИИ, покажем, как выбирать «железо» для запуска нейросетей и дадим несколько примеров сборок сервера для разных задач из сферы ИИ. А если после прочтения захотите прикинуть бюджет — можно сконфигурировать сервер под свои задачи прямо на сайте.
Сервер для обучения нейросети и ее дальнейшей работы это довольно специфическая система. Для работы нейросети нужны огромные вычислительные мощности, И лучше всего с такой нагрузкой справляется GPU. Они лучше приспособлены для совершения матричных операций и обрабатывают данные быстрее CPU. Это позволяет обучать нейросеть на большом количестве данных за разумное время.
Но не один лишь GPU играет важную роль в сервере, предназначенном для работы ИИ. Центральный процессор тоже может помочь или помешать работе ИИ в зависимости от вашего выбора комплектующих.
CPU отвечает за первичную обработку данных для обучения, ввод и вывод, обращение к дискам и т.д. А в некоторые алгоритмы машинного обучения быстрее выполняются как раз на центральном процессоре, так что CPU для сервера, на котором будет работать ИИ, тоже нужно подбирать подходящий.
AMD EPYC vs Intel Xeon: чьи CPU лучше подходят для работы с ИИ?Вечная борьба двух производителей остается актуальной и на поле выбора процессора для работы ИИ — подробнее о том, что выгоднее для бизнеса: Intel или AMD, мы разбирали отдельно. В обеих линейках есть отличные модели, но как всегда важно смотреть на детали.
AMD EPYC с сокетом SP3 — много ядер, много потоков, и как итог — CPU подходит для обучения нейросети на огромном количестве данных. Многопоточная производительность поможет ускорить обработку ваших данных, даже если их будет очень много.
Intel Xeon на LGA3647 — мастер стабильности. Да, этот сокет поддерживает меньше ядер — до 40 в отличие от лимита в 64 ядра у SP3, зато в сочетании с процессорами от Intel вы получите их технологии. Специализированные инструкции вроде AVX-512 ускорят матричные вычисления, а Deep Learning Boost сделает обучение моделей быстрее. Такое предлагает только Intel Xeon.

Графические ускорители — рабочая лошадка сервера для ИИ
GPU за счет своей специфической архитектуры идеально походят для работы ИИ. В них используется большое количество Cuda-ядер. Все вычисления делятся на огромное количество параллельных потоков, что сильно экономит время работы над задачей. А еще производители стали выпускать специальные модели, «заточенные» под работу с ИИ.
Классы профессиональных GPU NVIDIA
Прежде чем переходить к конкретным моделям, важно понимать классификацию видеокарт NVIDIA для профессионального применения:
Карты для датацентров (H200, H100, A100, L40, L40S) — созданы для работы 24/7 в серверных стойках. Имеют пассивное охлаждение, требуют мощного обдува в серверных шасси. Поддерживают максимальные объемы памяти (80-141 ГБ), виртуализацию vGPU, имеют ECC-память. Оптимизированы для параллельных вычислений в кластерах. Цена начинается от 1,5 млн рублей.
Карты для рабочих станций (RTX 6000 Ada, RTX A6000, RTX A5000, Quadro) — баланс между производительностью и удобством установки. Имеют активное охлаждение, занимают 2 слота, можно устанавливать в обычные Tower-серверы. Поддерживают виртуализацию vGPU, имеют видеовыходы для мониторов. Отличное решение для средних компаний.
Игровые карты (RTX 4090, RTX 3090) — самые доступные для ИИ. Занимают 3-4 слота, высокое энергопотребление и тепловыделение. Не поддерживают виртуализацию, но имеют отличное соотношение цена/производительность для небольших проектов и стартапов.
Теперь рассмотрим конкретные модели:
NVIDIA H200 — новейший флагман, появившийся в конце 2023 года. Массовые поставки начались во второй половине 2024 года. Имеет 16 896 ядер CUDA, 528 тензорных ядер четвертого поколения и 141 ГБ памяти типа HBM3e — это серьезный скачок по сравнению с предыдущим поколением. Пропускная способность памяти достигает 4.8 ТБ/с, что критично для работы с большими языковыми моделями.
NVIDIA H100 — предыдущий флагман на архитектуре Hopper. Имеет 14 592 ядра CUDA, 456 тензорных ядер и 80 или 96 ГБ памяти типа HBM3. Пропускная способность памяти 3.0-4.0 ТБ/с. Тензорные ядра четвертого поколения с нативной поддержкой формата FP8 дают двукратное ускорение по сравнению с A100.
Важно: На текущий момент покупка H100 экономически нецелесообразна. При практически одинаковой стоимости с H200, последний предлагает на 45% больше видеопамяти (141 ГБ против 96 ГБ) и на 20-25% выше пропускную способность (4.8 ТБ/с против 4.0 ТБ/с). Это напрямую влияет на производительность в задачах обучения и инференса больших языковых моделей. Если вы сейчас выбираете между этими моделями — берите H200, разница в цене минимальна, а выигрыш в производительности существенный.
A100 имеет 6 912 CUDA-ядер, 432 тензорных ядра третьего поколения, 40 либо 80 ГБ памяти типа HBM2e в зависимости от конфигурации. Пропускная способность памяти 1.56-2.0 ТБ/с. Плюс доступны технологии NVLink и NVSwitch, увеличивающие пропускную способность между GPU для ускорения передачи данных при экстремально высоких нагрузках. Именно A100 стала самой массовой профессиональной видеокартой для ИИ-задач — её продали в несколько раз больше, чем предыдущих V100.
RTX 6000 Ada — новое поколение профессиональных карт с 18 176 ядрами CUDA, 48 ГБ памяти GDDR6 с ECC. Производительность FP16 достигает 91 TFLOPS. Важная особенность: не поддерживает NVLink, в отличие от предшественника RTX A6000.
RTX A6000 — предыдущее поколение на архитектуре Ampere с 10 752 ядрами CUDA, 48 ГБ памяти GDDR6. Ключевое преимущество — поддержка NVLink для объединения двух карт. Если вам критична скорость обмена между GPU, выбирайте A6000 вместо новой RTX 6000 Ada.
RTX A5000 предлагает 8 192 ядра CUDA, 24 ГБ памяти типа GDDR6, есть тензорные ядра второго поколения, доступна NVLink (до 2 карт) и есть трассировка лучей. Хороший баланс цены и производительности для средних задач.
L40S — специализированная карта для инференса с 18 176 ядрами CUDA и 48 ГБ памяти GDDR6. Оптимизирована для высокой пропускной способности при работе с множеством пользовательских запросов одновременно.
Для сравнения можно взглянуть на V100 — первые GPU от NVIDIA с тензорными ядрами, вышедшие в 2017 году. У них 5 120 CUDA-ядер, 640 тензорных ядер первого поколения, 16 или 32 ГБ памяти HBM2 и пропускная способность 0.9-1.1 ТБ/с. Именно с V100 началась эра массового внедрения GPU в дата-центрах.
Вот сводная таблица для сравнения флагманских моделей:
| Модель | V100 | A100 | H100 | H200 |
|---|---|---|---|---|
| Ядра CUDA | 5 120 | 6 912 | 14 592 | 16 896 |
| Ядра Tensor | 640 | 432 | 456 | 528 |
| Объем памяти, ГБ | 16 или 32 | 40 или 80 | 80 или 96 | 141 |
| Тип памяти | HBM2 | HBM2e | HBM3 | HBM3e |
| Пропускная способность, ТБ/с | 0.9-1.1 | 1.56-2.0 | 3.0-4.0 | 4.8 |
| Форм-факторы | PCIe, SXM2 | PCIe, SXM4 | PCIe, SXM5 | PCIe, SXM5 |
Одно из главных преимуществ GPU от NVIDIA — тензорные ядра. Tensor Core — это специализированные вычислительные блоки в GPU NVIDIA, оптимизированные для выполнения матричных операций, которые лежат в основе глубокого обучения и других задач искусственного интеллекта.
Но не только Nvidia понимает важность GPU для нейросетей, AMD тоже предлагает конкурентные решения. Линейка AMD Instinct представляет серьезную альтернативу для работы с ИИ.
AMD Instinct MI300X — флагманский ускоритель на архитектуре CDNA 3, специально разработанный для генеративного ИИ. Оснащен 192 ГБ памяти HBM3 с пропускной способностью свыше 5,3 ТБ/с и нативной поддержкой форматов FP8 и BF16 для ускорения ИИ-задач. Это делает MI300X особенно эффективным для инференса больших языковых моделей.
AMD Instinct MI350 — новейшее поколение на архитектуре CDNA 4 с памятью HBM3e (288 ГБ) и пропускной способностью до 8 ТБ/с. Поддерживает новые форматы INT4/FP4/FP6 для матричных вычислений. В одной платформе можно использовать до 8 GPU с суммарным объемом памяти до 2,3 ТБ. Ускорители MI350X рассчитаны на масштабные задачи генеративного ИИ и обучение LLM.
Для связи между GPU AMD использует проприетарную технологию Infinity Fabric, которая обеспечивает когерентный доступ к памяти и высокую пропускную способность, аналогично NVLink от NVIDIA. AMD активно развивает открытую программную экосистему ROCm с поддержкой PyTorch и TensorFlow, что делает Instinct реальной альтернативой решениям NVIDIA в корпоративных кластерах.
Еще одной важной особенностью специализированных GPU для ИИ является использование ECC-памяти. В обычных видеокартах такое не встретишь.
Поддержка NVLink в разных поколениях GPUПри выборе видеокарт для multi-GPU конфигураций критически важно учитывать поддержку NVLink:
Поддерживают NVLink:
- H100/H200 — до 8 карт через NVSwitch
- A100 — до 8 карт через NVSwitch
- RTX A6000/A5000 (Ampere) — до 2 карт
- RTX 3090/3090 Ti — только 2 карты
- Quadro RTX 8000/6000 (Turing) — до 2 карт
НЕ поддерживают NVLink:
- RTX 6000 Ada и вся линейка Ada Lovelace для рабочих станций
- RTX 4090/4080/4070 и вся потребительская серия 40xx
- L40/L40S
Отсутствие NVLink не означает невозможность использования нескольких карт — они успешно работают через PCIe с помощью device_map='auto' или фреймворков типа DeepSpeed. Но скорость обмена будет ниже: PCIe 4.0 дает ~32 ГБ/с против 600-900 ГБ/с у NVLink.
Flash Attention 2 и совместимость архитектурFlash Attention 2 — технология оптимизации работы с памятью, которая может снизить потребление VRAM на 40-60% при работе с длинными контекстами и ускорить обучение на 50-70%.
Важно: Flash Attention 2 работает только на картах с архитектурой Ampere и новее:
- ✅ RTX 3090/3090 Ti, RTX 4090, RTX A6000, RTX 6000 Ada, A100, H100, H200
- ❌ RTX 2080 Ti, Quadro RTX 8000/6000, V100, T4
Это делает карты Turing (Quadro RTX 8000) менее привлекательными для работы с современными LLM, несмотря на 48 ГБ памяти.
Еще одной важной особенностью специализированных GPU для ИИ является использование ECC-памяти. В обычных видеокартах такое не встретишь.
Оперативная память для сервера с ИИ
Необходимый для сервера объем RAM зависит от того, насколько большой датасет будет использоваться и от сложности самой нейросети. Но в целом для мощных моделей рекомендуем брать от 256 Гб и больше. С таким объемом и обучение, и инференс будут проходить быстрее.
Используйте память с частотой от 4800 МГц. Не стоит экономить и брать модели прошлых поколений. И обязательно выбирайте ECC-память — подробнее об особенностях и типах серверной оперативной памяти читайте в нашем гайде. Функция коррекции ошибок важна для любого сервера, но в случае работы ИИ особенно.
Хранилище данных — библиотека для знаний ИИ
Данные, на которых будет обучаться нейросеть, обычно занимают большой объем. Чем больше датасет, тем больше для него требуется дискового пространства. И здесь можно было бы использовать массив HDD, но они не обеспечат достаточную скорость работы с данными.
Для хранения этих данных нужно использовать SSD. Брать нужно NVMe SSD, которые выдают скорость чтения-записи данных около 3 ГБ/с. Это быстрее не только HDD, но и классических SSD, подключаемых по интерфейсу SATA.
Еще один способ ускорить работу с датасетом — использовать объектное хранилище данных. Работа с объектами проходит быстрее, хранилище проще масштабировать, и управлять данными тоже можно быстрее за счет того, что метаданные (описание объектов, свойства и индексы) хранятся в отдельной таблице.
Но как и в любой другой СХД, в случае с сервером для ИИ нужно правильно распределять данные по дискам. Большие архивы, данные из которых используются не очень часто, можно хранить на HDD, так как в этом случае скорость работы с данными не так важна, как доступный объем.
ИтогКонфигурация сервера для ИИ всегда будет отличаться от конфигурации сервера для других задач. Обучение нейросетевых моделей и работа с ними это специфический процесс, но сейчас ИИ настолько распространен, что производители «железа» предлагают целые линейки комплектующих специально под сервера для ИИ. Выбирайте из них и будьте уверены, что ваш сервер справится с задачей.
Серверные платформы для ИИ: какие бывают, и чем отличаются
С ключевыми комплектующими разобрались, но все они не работают сами по себе. Как обычному компьютеру нужна материнская плата, система охлаждения и блок питания, так же серверу нужна серверная платформа. Ее выбор тоже требует внимания. Специфика работы с ИИ влияет и на выбор платформы.

Решения от NVIDIA: DGX и HGX
К счастью, на рынке есть готовые решения, на базе которых можно собрать идеальный сервер для ИИ. К примеру, варианты от NVIDIA: DGX и HGX.
NVIDIA DGX это готовое решение, которое уже адаптировано под работу с искусственным интеллектом. Эти сервера оснащаются топовыми GPU для ИИ, в NVIDIA DGX A100 установлено 8 процессоров A100, которые объединены между собой через NVLink/NVSwitch для уменьшения задержек при работе с данными.
Естественно, сервер поддерживает все технологии NVIDIA в области ИИ. Фреймворки TensorFlow, PyTorch, облачные решения NVIDIA Base Command, в общем, все, что нужно, будет доступно «из коробки». Ну и плюсом система охлаждения, питание и все остальное тоже подобрано так, что ничего менять не придется.
NVIDIA DGX подойдет для:
- Обучения крупных ИИ-моделей (нейросети, NLP, компьютерное зрение);
- Исследований в области ИИ в лабораториях и университетах.
- Корпоративных решений для анализа Big Data и автоматизации.
NVIDIA HGX очень похож на своего коллегу, но является более гибкой платформой. Тут используется модульная структура, позволяющая использовать 4 или 8 GPU. Например, HGX H100/H200: поддерживает до 8 GPU на базе архитектуры Hopper, с возможностью объединения до 256 GPU через NVLink.
Есть еще и новейшая версия HGX B300 на архитектуре Blackwell, которая поддерживает до 16 GPU, объединенных через NVLink 5-го поколения, с пропускной способностью 1.8 ТБ/с между GPU.
В HGX H100/H200 используются тензорные ядра 4-го поколения, поддерживающие форматы FP8, FP16, TF32, что ускоряет обучение ИИ-моделей в 3–6 раз по сравнению с предыдущими поколениями.
Многие крупные компании по типу Dell, HPE, Supermicro выбирают эту платформу, чтобы добавить в нее CPU, систему охлаждения и другие компоненты по своему выбору, исходя из задач конкретного сервера. В итоге они получают отличную производительность, адаптированную под любые условия.
NVIDIA HGX это выбор для:
- Облачных вычислений и SaaS-платформ;
- Масштабной обработки данных в реальном времени;
- Развёртывания ИИ-сервисов в дата-центрах.
Универсальные платформы
Есть на рынке и универсальные решения, которые дают еще больше гибкости и возможностей масштабирования. К тому же они предлагают оптимальное соотношение цены и функционала.
HPE ProLiant предлагает 4 линейки с разной модульной структурой:
- DL (стоечные, высокая плотность),
- ML (башенные, хорошая масштабируемость),
- BL (блейд-серверы),
- SL (гипермасштабируемые решения).
Поддерживаются процессоры Intel Xeon Scalable (до 28 ядер на процессор) и AMD EPYC Gen4 (до 128 ядер), оперативная память DDR5-4800 (Gen11/Gen12) с объёмом до 6 ТБ, NVMe Gen5 (до 1600W), SAS/SATA и гибридных конфигураций (например, DL380 Gen10 — до 30 дисков).
Но самое главное — современные поколения платформы поддерживают подключение до 8 GPU.
Есть и несколько полезных технологий от производителя, которые больше нигде не встретишь. HPE iLO дает возможность удаленно управлять сервером, а Silicon Root of Trust защищает от физических и программных атак.
Большая гибкость платформы и поддержка современных поколений комплектующих делает из серии HPE ProLiant отличный конструктор, с помощью которого можно получить машину, подходящую для работы ИИ, но комплектующие при этом придется подбирать самостоятельно, готовых решений производитель не предлагает.
Dell PowerEdge тоже предлагает гибкую модульную структуру с поддержкой актуального «железа» для различных задач. Есть башенные и стоечные серверы, а также сверхплотные и блейд-серверы.
Поддерживаются процессоры Intel Xeon Scalable до 4 поколения и AMD EPYC 3 и 4 поколений. Серверы 16-го поколения (G16) оснащены DDR5 и PCIe 5.0, что увеличивает пропускную способность на 100% по сравнению с предыдущими версиями.
До 6 ТБ DDR4/DDR5 (в моделях R750) и поддержка NVMe Gen4/Gen5, SAS/SATA, а также гибридных конфигураций.
Помимо гибкости в сборке семейство Dell PowerEdge многие ценят за надежность, обеспечиваемую резервируемыми компонентами охлаждения и питания. А еще есть поддержка интеграции с VMware, Microsoft Azure Stack, NVIDIA GPU.
И наконец Huawei FusionServer — серия от китайского производителя, которая так же как и предыдущие варианты, имеет модульную структуру.
Поддерживаются процессоры Intel Xeon Scalable 3 поколения для V6 и E5-2600 v3/v4 для V3-серий. Технологии Intel Turbo Boost, Hyper-Threading и Virtualization для ускорения многопоточных задач тоже в наличии, что является большим плюсом.
По оперативной памяти поддержка до 32 DIMM DDR4 (2288H V6) или 16 DIMM DDR4 (RH1288 V3) с поддержкой ECC. А дисковое хранилище поддерживает все те же гибкие конфигурации: SAS/SATA HDD, NVMe SSD и Intel Optane PMem.
Есть и набор полезных для любого сервера технологий:
- iBMC — встроенный модуль для удаленного мониторинга, диагностики и управления через KVM.
- Аппаратное шифрование AES-NI и TPM 2.0.
- Fault Diagnosis & Management (FDM), которая прогнозирует сбои за 7–30 дней с высокой точностью.
Уже захотели приобрести сервер из этой линейки? Погодите, тут есть один нюанс. Huawei FusionServer поддерживают до 8 GPU, но совместима платформа только с китайскими чипами Ascend.
Эти GPU разработаны специально для ИИ, но пока что мало обкатаны, а некоторые модели, заявленные как аналоги популярных решений от Nvidia, еще только тестируются. Возможно эти чипы действительно смогут стать альтернативой уже проверенным процессорам от других производителей, но пока они не получили большого распространения, брать их может быть рискованно.
Supermicro GPU SuperServer — это линейка серверов от американского производителя, который специализируется на высокоплотных решениях для дата-центров. Supermicro предлагает одни из самых гибких конфигураций на рынке.
Например, модель SYS-420GP-TNR поддерживает до 10 полноразмерных GPU PCIe x16 Gen4 в форм-факторе 4U. Это одна из самых плотных конфигураций среди универсальных платформ. Официально сертифицирована для работы с GPU NVIDIA: H100 (PCIe), A100, A40, A30 и серия RTX (A6000/A5000). Поддерживаются также некоторые карты Intel, например, Intel Data Center GPU Flex 170 для медиапроцессинга.
Архитектура построена по принципу "dual-root", где графические процессоры равномерно распределены между двумя CPU, что позволяет эффективно масштабировать производительность и оптимизировать нагрузку. Шасси оснащено 12 горизонтальными слотами PCIe 4.0 x16 FHFL для установки GPU, а также отсеками для 24 горячезаменяемых 2.5-дюймовых дисков (SATA/SAS/NVMe).
Питание осуществляется от 4 резервированных блоков питания мощностью 2000 Вт каждый, сертифицированных по стандарту Titanium. Сервер входит в линейку NVIDIA-Certified Systems, что гарантирует оптимальную работу со всем стеком ИИ и прохождение тестирования на совместимость с ПО из каталога NVIDIA NGC.
Supermicro особенно популярны в сегменте построения GPU-кластеров и могут служить основой для создания сертифицированных решений NVIDIA DGX SuperPOD. Это делает их отличным выбором для компаний, которые планируют масштабировать инфраструктуру для ИИ.
ASUS ESC (Enterprise Server & Cloud) — серверная линейка от тайваньского производителя, известного своими инновациями в области охлаждения и высокой плотности GPU.
Флагманская модель ESC8000-E12 вмещает до 8 двухслотовых графических процессоров в форм-факторе 4U. Просторный корпус позволяет разместить 2 процессора, до 32 модулей оперативной памяти и обширный массив накопителей.
В конфигурациях на базе Intel Xeon поддерживаются новейшие поколения GPU NVIDIA, включая серию Hopper (H100, H200), а также профессиональные RTX 6000 Ada и будущие карты на архитектуре Blackwell. Предлагаются также модификации на AMD EPYC, способные работать с 8 GPU NVIDIA или ускорителями AMD Instinct MI250/MI300.
Для дополнительного расширения предусмотрены 2 слота PCIe 5.0 x16, а также 2 слота M.2 для SSD. Мощная подсистема питания включает до 4 блоков по 3000 Вт, а интеллектуальная система управления вентиляторами гарантирует стабильную работу даже при максимальных нагрузках.
Линейка ESC8000 обладает сертификацией NVIDIA-Certified Systems, что подтверждает полную совместимость с программным стеком NVIDIA, включая CUDA и драйверы, контейнеры NGC, а также наборы NVIDIA AI Enterprise для генеративного ИИ. Сервер полностью готов к установке и ускорению популярных фреймворков, таких как TensorFlow, PyTorch и TensorRT.
ASUS ESC отлично подходит для развертывания масштабной инфраструктуры глубокого обучения, высокоплотного инференса с распределением ресурсов GPU между задачами, а также для высокопроизводительных вычислений (HPC), требующих мощностей GPU. Благодаря сертификации NVIDIA, эти серверы легко интегрируются в существующие рабочие процессы ИИ.
Конфигурация сервера для ИИ: что еще нужно учесть при сборке
Стабильную и качественную работу сервера помимо GPU, CPU и другого «железа» обеспечивают и остальные компоненты. Важно подобрать подходящую систему охлаждения, учесть совместимость с профильным ПО, заложить базу для масштабирования. Вот небольшой чек-лист того, о чем нужно подумать перед покупкой сервера.
Поддержка NVLink и PCIe 5.0Скорость передачи данных критически важна при обучении нейросетей. Если использовать старые технологии и стандарты, то даже топовые GPU потратят на обучение гораздо больше времени, чем вы рассчитывали.
NVLink — это высокоскоростная шина от NVIDIA, предназначенная для соединения GPU между собой и с CPU, оптимизированная для задач искусственного интеллекта ИИ и высокопроизводительных вычислений.
NVLink 5.0 (Blackwell) обеспечивает скорость 1.8 ТБ/с на модуль при минимальных задержках (буквально наносекунды). Каждый GPU соединен с другими через коммутатор NVSwitch, что исключает узкие места. При этом GPU могут совместно использовать память, ускоряя обмен данными. Поддерживается до 256 GPU в связке, это целый кластер.
PCI Express 5.0 — последний стандарт шины для подключения периферийных устройств (GPU, SSD, сетевых карт) к CPU или чипсету. Скорость передачи данных 128 ГБ/с для конфигурации x16. Задержки тут выше, так как взаимодействие идет через CPU, но все равно скорость работы всей системы при использовании PCI Express 5.0 заметно увеличивается.
Обе технологии дополняют друг друга: PCIe 5.0 обеспечивает общую связность системы, а NVLink ускоряет взаимодействие GPU в специализированных кластерах.

Система охлаждения
Современные серверы для ИИ с профильными GPU потребляют огромное количество энергии, а значит и сильно нагреваются. Система охлаждения важна для любого сервера, но при выборе сервера для ИИ нужно подходить к охлаждению очень внимательно.
Воздушное охлаждение остается основным вариантом для большинства GPU-серверов. Современные серверные видеокарты в форм-факторе PCIe специально разработаны с blower-style системой охлаждения, оптимизированной для работы внутри серверного шасси. При правильной организации воздушных потоков такое охлаждение эффективно справляется с задачей.
Принцип работы такой же, как у обычных серверов — воздушный поток отводит тепло через оптимизированные каналы вентиляции. Производители серверов, такие как Dell, HPE, Supermicro и ASUS, тщательно проектируют шасси с учетом мощных GPU: устанавливают высокопроизводительные вентиляторы в ключевых точках, используют термостойкие материалы и внедряют автоматическое управление скоростью вращения вентиляторов.
Для стабильной работы воздушного охлаждения GPU-серверов критически важны условия в дата-центре:
- Температура входящего воздуха: По стандарту ASHRAE H1 для высокоплотного оборудования требуется 18-22°C
- Правильная организация холодных и горячих коридоров: Разделение воздушных потоков предотвращает смешивание горячего и холодного воздуха
- Достаточная производительность систем кондиционирования: CRAC/CRAH системы должны обеспечивать необходимый объем охлажденного воздуха
- Охлаждаемые стойки: Для плотных конфигураций желательно использовать стойки с дополнительным охлаждением
Воздушное охлаждение эффективно работает для конфигураций до 20-30 кВт на стойку. Это покрывает большинство задач — от серверов с 1-4 GPU для инференса до систем с 8 GPU для обучения моделей среднего размера.
Однако у воздушного охлаждения есть физические ограничения. При плотности свыше 50 кВт на стойку требуется такой объем воздушного потока (более 7850 кубических футов в минуту), что система становится неэффективной. В таких случаях — например, для плотных конфигураций с 8-10 топовых GPU H200 в форм-факторе 2U-4U — требуется переход на жидкостное охлаждение.
Жидкостное охлаждение это более современный вариант. Тепло отводится через специальные хладагенты, а иногда воду, циркулирующую в замкнутом контуре.
Такая система охлаждения гораздо эффективнее обычных кулеров, жидкость отводит в сотни раз больше тепла, чем воздух. К тому же жидкостные системы охлаждения более компактные, так что сервер с таких охлаждением будет проще разместить.
Стоит такое удовольствие больше, чем воздушное охлаждение. Цены в среднем на 30-50% выше. К тому же есть риск утечки хладагента, а утечка означает остановку сервера на период ремонта или замены охлаждения.
При использовании небольшого сервера для ИИ на 1-4 GPU, то вам скорее всего хватит воздушного охлаждения. Но если планируется крупный кластер да еще и с серверами высокой плотности, то выбирайте жидкостное охлаждение.
Кластеризация и распределение вычислений
С обучением крупных ИИ-моделей типа GPT-4 или Llama один сервер не справится. Чтобы этот процесс занимал не годы, а хотя бы дни, используются кластеры серверов, в которых вычисления распределяются между несколькими машинами.
Чтобы кластер ускорял процесс, передача данных между объединенными GPU должна быть быстрой. Здесь на помощь приходит технология InfiniBand. Она обеспечивает скорость передачи данных до 400 Гбит/с на порт при задержке в 0.6 мкс (микросекунд).
По итогу получаем ускорение обмена данными между GPU происходит в 5–10 раз быстрее, чем через классический Ethernet. А еще поддержку NVIDIA Collective Communications Library для синхронизации GPU и возможность подключения до 10 000 узлов в одном кластере.
Есть еще один вариант — Ethernet 200G. Он имеет не такие впечатляющие показатели скорости и задержки: 200 Гбит/с на порт и ~5–10 мкс. Зато работает с TCP/IP-стеком и легко интегрируется в существующую инфраструктуру. Плюс поддерживает виртуализацию и облачные среды Kubernetes и OpenStack. В общем, классическая гибкость и универсальность. Стоит, кстати, Ethernet 200G дешевле, чем InfiniBand.
Совместимость с профильным ПО
«Железо» без софта — ничто. Для серверов, ориентированных на обучение и использование ИИ, разработаны фреймворки и технологии, оптимизирующие работу сервера. Прежде, чем покупать себе сервер для ИИ, нужно узнать, с какими из этих технологий будет совместимо ваше «железо».
NVIDIA CUDA — основная платформа для ускорения вычислений на GPU NVIDIA. Она обеспечивает поддержку фреймворков TensorFlow и PyTorch через библиотеки и драйверы. Все серверы с GPU NVIDIA поддерживают CUDA и оптимизированы для максимальной производительности.
Но при этом требуется строгое соответствие версий CUDA и ПО. Например, TensorFlow 2.15 работает только с CUDA 11.8, а PyTorch 2.3 — с CUDA 12.1.
AMD ROCm — это альтернатива CUDA для GPU от AMD. Поддерживает запуск CUDA-приложений через ZLUDA — слой совместимости, транслирующий вызовы CUDA в HIP/ROCm без модификации исходного кода.
Если говорить простым языком, это значит, что серверы на базе AMD могут выполнять CUDA-приложения с производительностью, близкой к нативной.
К сожалению, не все библиотеки полностью поддерживаются, так что нужно исходить из того, что будете использовать.
TensorFlow и PyTorch — самые актуальные фреймворки для ИИ.
TensorFlow оптимизирован для CUDA, но будьте внимательны, последние версии требуют CUDA 12.x и cuDNN 8.9+. С AMD фреймворк работает через ROCm.
Тут важно внимательно следить за версиями, потому что легко наткнуться на несовместимость. Например, TensorFlow 2.10 работает только с CUDA 11.2.
С PyTorch все чуть проще. Он поддерживает CUDA, ROCm и даже Intel oneAPI. Актуальная версия PyTorch 2.3 работает с ROCm 6.0 для AMD и CUDA 12.1 для NVIDIA.
И наконец Kubernetes — незаменимый инструмент для управления ИИ-кластерами. У него есть интеграция как с NVIDIA, так и AMD.
Плагин NVIDIA GPU Operator автоматизирует установку драйверов и мониторинг GPU. А работа с чипами от AMD обеспечивается через ROCM Operator и плагин k8s-device-plugin для выделения ресурсов GPU.
Система хранения данныхДля работы с ИИ критически важна скорость доступа к данным:
Системный диск: NVMe SSD минимум 1 ТБ для ОС и рабочих данных Хранилище датасетов: NVMe SSD 4-8 ТБ или массив из нескольких дисков Архивное хранение: HDD для долгосрочного хранения обученных моделей
Питание
Правильный расчет питания критически важен для стабильной работы:
Основное правило: блок питания должен иметь запас мощности 40% от суммарного TDP всех компонентов. Это связано с пиковыми нагрузками, которые могут превышать номинальное потребление.
Примеры расчета:
- RTX 4090 (450W TDP) → минимум 630W на карту с запасом
- 2×RTX 4090 + система → минимум 1600W блок питания
Для multi-GPU систем рекомендуется использовать серверные блоки питания с резервированием (1+1 или N+1).
Эксплуатация и поддержка ИИ-серверов: как наладить работу без лишних проблем
Каждому хочется, чтобы после запуска сервер сам по себе работал, не ломался, не выдавал ошибок и вообще минимально тревожил системных администраторов. К сожалению, нажать кнопку «Старт» и уехать в отпуск не получится, потому что серверу требуется поддержка и грамотное управление.
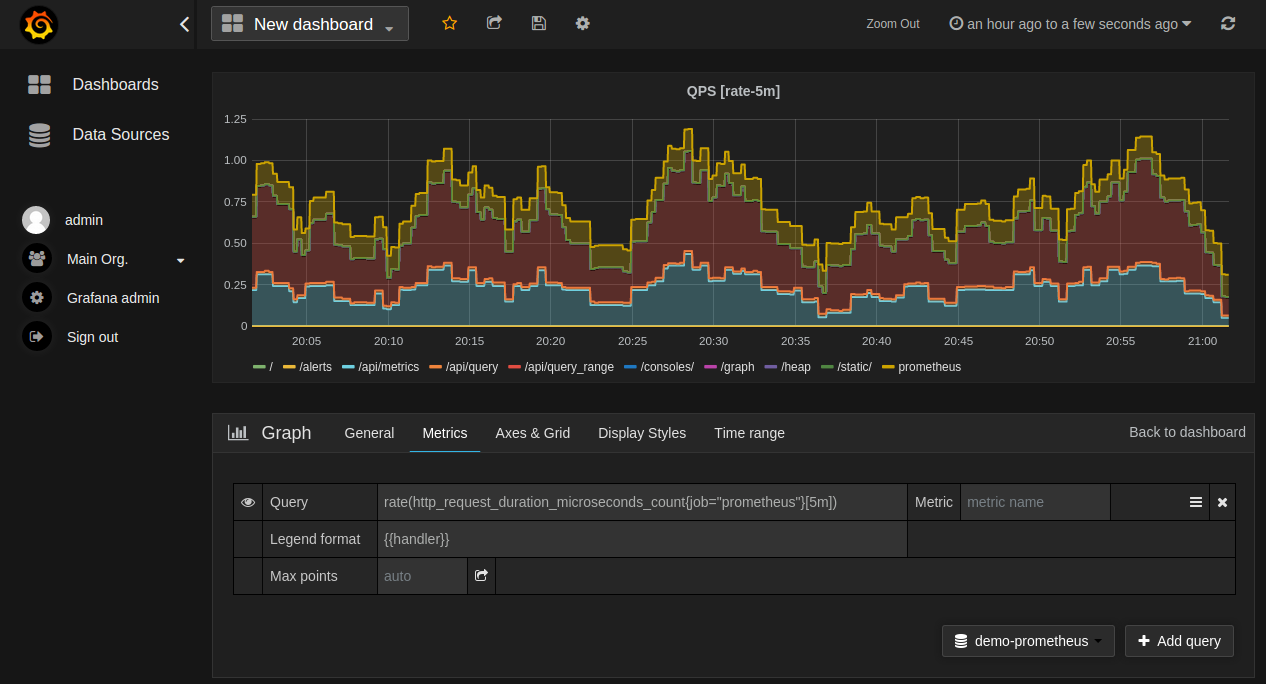
Мониторинг нагрузки и управление ресурсами
Инструменты для мониторинга нагрузки нужны серверу так же, как приборная панель автомобилю. Без этого будет вообще непонятно, что происходит с вашим сервером.
Grafana + Prometheus — отличная связка, закрывающая большую часть задач по мониторингу состояния сервера. Prometheus собирает данные о работе сервера, Главное его отличие от аналогичных мониторинговых инструментов заключается в том, что он сам собирает информацию с заданных устройств, а не ждет, пока сервер отправит ему данные. Настраивается все это очень гибко благодаря специальному языку PromQL.
С помощью Prometheus вы будете анализировать производительность моделей машинного обучения в реальном времени и отслеживать задержки и использование ресурсов.
А Grafana выведет все собранные данные в виде наглядных и удобных графиков и дашбордов. Большинство мониторинговых программ передают собранные данные в таком виде, в котором их нельзя или сложно прочитать, поэтому для визуализации используют специальное ПО.
Если вы используете GPU NVIDIA, то выбирайте NVIDIA DCGM. Это профессиональный инструмент для мониторинга, управления и диагностики GPU в дата-центрах, адаптированный для использования на серверах для обучения ИИ.
NVIDIA DCGM собирает информацию о загрузке ядер GPU, их температуре, использовании памяти и других параметрах. На основе этих данных программа сама обнаруживает «узкие места» в работе сервера.
Плюс есть функция ограничения мощности, разделение физических ядер на несколько виртуальных и изолирование задач между пользователями. Это может быть полезно при работе нескольких команд над разными задачами с одним сервером.
Вот несколько советов по лучшим практикам управления сервером:
- Установите базовые показатели. Определите типичные для работы вашего сервера показатели, чтобы быстро выявлять аномалии. Например, если ИИ-модель потребляет 80% GPU при пиковой нагрузке, отклонения от этого значения говорят о проблемах.
- Оптимизируйте сбор данных. Фильтрация данных: Уменьшайте объём собираемых метрик, исключая то, что вам не нужно. Кэширование: Используйте кэширование промежуточных результатов вычислений для снижения нагрузки на CPU/GPU.
- Балансируйте нагрузку. Для распределённых ИИ-систем применяйте балансировщики, например, Kubernetes и стратегии гибкого распределения ресурсов.
- Обеспечьте безопасность данных. Шифруйте данные мониторинга, настройте права доступа к этим данным. Для ИИ-систем также критично избегать утечек тренировочных данных.
- Планируйте использование ресурсов. Анализируйте исторические данные для прогнозирования будущих потребностей. Например, если ИИ-модель требует удвоения ресурсов каждые 6 месяцев, заранее планируйте апгрейд и подготовьтесь к нему.
Виртуализация и распределение ресурсов
Виртуализация и контейнеризация встречаются на большинстве серверов. Это необходимый элемент грамотной и эффективной эксплуатации.
Proxmox — самый распространенный инструмент для выделения на сервере изолированных виртуальных машин. Если вы ещё не определились с платформой виртуализации, рекомендуем изучить полный разбор популярных гипервизоров. Proxmox позволяет разделять GPU между разными командами и задачами, запускать специфичный софт для экспериментов или решения специфичных задач и обеспечивать безопасность данных.
Поддерживается интеграция с Ceph для распределенного хранилища данных, что очень актуально для больших датасетов. Proxmox имеет открытый исходный код, то есть использовать его можно бесплатно, при его возможностях это буквально подарок.
Docker — «база» для контейнеризации. Позволяет упаковывать приложения в изолированные контейнеры с общим ядром ОС. Это очень полезно, например, для обхода проблем с совместимостью версий ПО, потому что контейнеры фиксируют версии библиотек.
Плюс контейнеры потребляют меньше ресурсов, чем виртуальная машина. С их помощью управлять ресурсами сервера будет гораздо проще. Да и переносить приложения с помощью контейнеров гораздо проще, когда потребуется, вы быстро переедете из локального сервера в виртуальный.
А для управления кластерами контейнеров подойдет Kubernetes. Это самый распространенный софт для распределения нагрузок и управления большими серверными структурами.
Kubernetes поможет запустить распределенное обучения моделей на сотнях GPU, автоматически масштабирует сервисы инференса при пиковой нагрузке и даже перезапустит упавшие узлы с моделями.
Комбинируя эти технологии, вы получите оптимально работающий сервер, который позволит эффективно использовать GPU для обучения моделей и инференса, даст возможность экспериментировать с разными моделями на одной машине и будет гораздо удобнее в использовании, чем монолитный сервер.

Готовые конфигурации под конкретные задачи
Несколько конфигураций сервера для ИИ, которые мы рекомендуем в зависимости от задач, стоящих перед сервером.
Генераторы кода для небольших моделей
Автодополнение в IDE, рефакторинг легаси, генерация тестов — всё это работает на языковых моделях. Для небольших команд подойдут модели до 13B параметров, которые обеспечат комфортную скорость отклика без лишних затрат.
Конфигурация:
- GPU: NVIDIA RTX A5000 × 1 (24 ГБ GDDR6)
- CPU: Intel Xeon Silver 4314 × 2
- RAM: 128 ГБ
- Блок питания: 2000W × 2 (резервирование 1+1)
Такая конфигурация запустит CodeLlama 13B, StarCoder или WizardCoder и обеспечит быструю работу для команды разработчиков. Одной RTX A5000 достаточно для комфортной работы с моделями до 13B параметров в квантизованном виде.
Генераторы кода для крупных моделей
Если нужна модель покрупнее (33-70B параметров) — такие модели лучше понимают контекст проекта и реже генерируют некорректный код. Они справятся с более сложными задачами рефакторинга и архитектурными решениями.
Конфигурация:
- GPU: NVIDIA RTX 6000 Ada × 2 (48 ГБ GDDR6 с ECC)
- CPU: Intel Xeon Gold 6430 × 2
- RAM: 256 ГБ
- Блок питания: 2000W × 2 (резервирование 1+1)
Подойдет для моделей типа CodeLlama 34B/70B (в 4-битной квантизации), Phind-CodeLlama или DeepSeek Coder 33B.
Корпоративный GPT-ассистент (DeepSeek, Qwen3, Llama)Если вы дообучаете модели под свои корпоративные данные или запускаете большие модели с длинным контекстом — потребуется серьезная мощность.
Конфигурация для дообучения:
- GPU: NVIDIA H200 141GB × 4 (с NVLink)
- CPU: AMD EPYC 9654 (Genoa) × 2
- RAM: DDR5 ECC RDIMM 4800 MHz × 24 (768 ГБ)
- Блок питания: 3000W × 4 (резервирование N+1)
Для задач, где достаточно готовых компактных моделей без дообучения, можно обойтись меньшими ресурсами:
Конфигурация для инференса:
- GPU: NVIDIA RTX 6000 Ada × 2 (48 ГБ каждая, суммарно 96 ГБ)
- CPU: AMD EPYC 9124 × 1
- RAM: DDR5 ECC RDIMM 4800 MHz × 8 (256 ГБ)
- Блок питания: 2000W × 2
Две RTX 6000 Ada позволят работать с квантизованными версиями Llama 70B, а для простых корпоративных чат-ботов с моделями 7-13B параметров достаточно даже одной RTX A4000.
Компьютерное зрение
Распознавание лиц, контроль качества на производстве, детекция объектов на видео в реальном времени. Здесь важен баланс производительности и стоимости.
Конфигурация:
- GPU: NVIDIA RTX A5000 × 4 (оптимальное соотношение цена/производительность)
- CPU: Intel Xeon Silver 4410Y × 2
- RAM: DDR5 ECC RDIMM 4800 MHz × 12 (384 ГБ)
- Блок питания: 2400W × 2
Подходит для YOLO, Detectron2, EfficientDet и других популярных фреймворков компьютерного зрения. Способен обрабатывать 10-20 видеопотоков 4K в реальном времени. Для более требовательных задач можно заменить на 2×RTX 6000 Ada.
Сервер для обучения моделей
Конфигурация оптимизирована под задачи глубокого обучения (LLM, компьютерное зрение, NLP) с учетом баланса производительности, масштабируемости и энергоэффективности.
Конфигурация:
- GPU: NVIDIA H200 80GB SXM5 × 8 или A100 80GB × 8
- CPU: AMD EPYC 9654 (Genoa) × 2
- RAM: 768 ГБ
- Блок питания: 3500W × 3 (резервирование N+1)
Такая конфигурация подойдет для обучения больших языковых моделей (Llama 3, Mistral) с десятками миллиардов параметров, а также для файнтюнинга моделей класса 70B.
Бюджетный вариант: Tower-серверА если бюджет ограничен? Можно сэкономить на форм-факторе и выбрать башенный (Tower) сервер. Это компромиссное решение для небольших компаний или стартапов.
Что может Tower-сервер:
- Формат обычной башни — помещается под стол или в небольшую серверную комнату
- Вместимость: до 4 GPU двойной ширины (но с ограничениями по питанию)
- Стоимость в 2-3 раза ниже стоечных конфигураций
Типовая конфигурация Tower-сервера:
- GPU: NVIDIA RTX 4090 × 2 (24 ГБ каждая) или RTX A5000 × 2
- CPU: Intel Xeon W9-3475X
- RAM: 256 ГБ
- Блок питания: 2000W × 1
Но есть нюансы:
- Воздушное охлаждение в компактном корпусе может не справиться с пиковой нагрузкой 4 GPU
- Жесткие ограничения на количество дисков и планок оперативной памяти
- Максимум 2 блока питания, а часто и вовсе 1 — это ограничивает количество мощных карт.
Tower-сервер отлично подойдет для экспериментов с ИИ, разработки прототипов или работы небольшой команды data scientists. С двумя RTX 4090 можно комфортно работать с квантизованными моделями до 30-40B параметров.
Итог: как выбрать сервер для ИИ, чтобы не обжечься
Выбор сервера для ИИ — это не обычная задача сисадмина, а полноценный проект, требующий глубокого понимания ваших задач и технических возможностей. Искусственный интеллект — мощный инструмент, но он работает эффективно только на правильно подобранной конфигурации.
Что важно знать при выборе сервера для ИИ:
Железо должно соответствовать задачам. Не переплачивайте за H200, если вам достаточно A5000 для инференса компактных моделей. И наоборот — не экономьте на GPU, если планируете обучать большие языковые модели.
Комплектующие должны быть совместимы друг с другом. Особое внимание уделите поддержке NVLink — если планируете обучение больших моделей, выбирайте RTX A6000 вместо RTX 6000 Ada, несмотря на то, что последняя новее. Проверьте, поддерживает ли выбранная платформа нужное количество GPU, хватит ли мощности блоков питания (помните про 40% запас), справится ли система охлаждения.
Сервер должен работать с необходимыми фреймворками. Убедитесь в наличии сертификации NVIDIA-Certified или NGC-Ready, если используете CUDA. Для AMD проверьте совместимость с ROCm.
Нужна поддержка и гарантия. ИИ-серверы — это дорогостоящее оборудование, которое должно работать стабильно.
Чтобы сделать наилучший выбор, мы рекомендуем обратиться к нашим ИТ-инженерам. Мы создадим персональную конфигурацию под ваши задачи с учетом заданного бюджета — от компактных решений для инференса до мощных кластеров для обучения LLM. Наши специалисты помогут избежать типичных ошибок при выборе комплектующих, подберут оптимальное соотношение производительности и стоимости, а также обеспечат быструю поставку и ввод в эксплуатацию.







