Технологии дедупликации и сжатия данных в современных СХД
- Когда хранить одно вместо десяти становится искусством
- Фиксированный или переменный: вечная дилемма размера блоков
- Сейчас или потом: timing решает всё
- Сжатие: когда мало убрать копии
- Виртуализация: где дедупликация раскрывается во всей красе
- Резервное копирование: где экономия измеряется терабайтами
- Подводные камни: о чём молчат маркетологи
- Железо против софта: вечный спор
- Что дальше: взгляд в будущее
- Практический взгляд: что выбрать для вашего бизнеса
Представьте типичный корпоративный дата-центр. Сотня виртуальных машин, терабайты бэкапов, и счёт за хранение данных, который растёт быстрее, чем зарплаты IT-отдела. При этом если заглянуть внутрь этого цифрового хаоса, окажется, что примерно 60-70% всех данных — это копии одного и того же. Одинаковые операционные системы на виртуалках, повторяющиеся библиотеки, документы, которые кто-то сохранил в десяти разных местах "на всякий случай". И вот тут на сцену выходят две технологии, которые могут превратить этот беспорядок в стройную систему — дедупликация данных и сжатие.
Когда хранить одно вместо десяти становится искусством
Дедупликация — это, по сути, интеллектуальная уборка в вашем хранилище. Технология находит одинаковые данные и оставляет только один экземпляр, заменяя все остальные копии ссылками на оригинал. Звучит просто? На деле это похоже на игру в тетрис на уровне битов и байтов.
Работает это примерно так: система анализирует поступающие данные, вычисляет для каждого блока уникальный хеш-идентификатор (что-то вроде отпечатка пальца для данных), и проверяет — не встречался ли такой блок раньше. Если встречался — вместо сохранения копии система просто создаёт ссылку на уже существующий блок. Если вы когда-нибудь использовали символические ссылки в Linux, принцип похожий, только масштаб другой.
Но здесь начинаются нюансы. Дедупликация бывает разной глубины погружения. Файловая дедупликация — это как убрать из квартиры лишние копии одной и той же книги. Система просто находит полностью идентичные файлы и удаляет дубликаты. Просто, эффективно, но... не очень результативно в реальной жизни. Потому что даже если вы отредактировали в документе одну букву, для системы это уже два разных файла.
Блочная дедупликация работает умнее. Она разбивает файлы на блоки и ищет повторения на этом уровне. Изменили одну страницу в стостраничном документе? Система сохранит только изменённый блок, а остальные 99% останутся в единственном экземпляре. Это как если бы вместо покупки новой энциклопедии из-за одной устаревшей статьи вы просто заменили нужную страницу.
Фиксированный или переменный: вечная дилемма размера блоков
Тут мы подходим к интересному моменту. Блоки для дедупликации могут быть фиксированного или переменного размера, и выбор между ними — это всегда компромисс.
Фиксированные блоки — это как нарезать батон хлеба ровными кусками. Просто, быстро, предсказуемо. Система берёт данные и режет их на куски по 4, 8 или 16 килобайт. Обработка быстрая, нагрузка на процессор минимальная. Но есть проблема: если данные сдвинулись хотя бы на один байт (например, в начало файла добавили символ), все блоки "поедут", и система не узнает в них старые данные.
Переменные блоки решают эту проблему. Алгоритм ищет естественные границы в данных, используя технику, которая называется "скользящее окно". Это позволяет находить повторяющиеся участки даже если данные сместились. Эффективность дедупликации вырастает в разы, особенно на неструктурированных данных. Но и ресурсов такой подход требует заметно больше — процессор будет работать интенсивнее, а метаданных для хранения информации о блоках понадобится больше.
Сейчас или потом: timing решает всё
Ещё один важный выбор — когда выполнять дедупликацию. Inline-дедупликация происходит прямо в момент записи данных. Данные приходят, анализируются, дедуплицируются и только потом записываются на диск. Экономия места мгновенная, но есть цена — задержка при записи. Для систем резервного копирования, где скорость записи не критична, это отличный вариант.
Post-process дедупликация работает иначе. Сначала данные записываются как есть, а потом, в фоновом режиме, система начинает искать и удалять дубликаты. Это как сначала свалить все вещи в кладовку, а потом, когда будет время, разобрать и организовать. Производительность при записи не страдает, но нужно дополнительное место для временного хранения данных до дедупликации.
В реальности многие современные СХД используют гибридный подход. Критичные для производительности данные обрабатываются post-process, а бэкапы и архивы — inline. Умная система сама решает, что и когда оптимизировать.
Сжатие: когда мало убрать копии
Дедупликация убирает копии, но что делать с уникальными данными, которые всё равно занимают много места? Тут в игру вступает сжатие данных. Если дедупликация — это уборка дубликатов между файлами, то сжатие — это оптимизация внутри каждого уникального блока.
Современные СХД используют различные алгоритмы сжатия: LZ4 для скорости, ZSTD для баланса, GZIP для максимальной степени сжатия. Выбор алгоритма — это всегда компромисс между степенью сжатия, скоростью и нагрузкой на процессор. LZ4 сжимает быстро, но не очень сильно. GZIP сожмёт лучше, но процессор попотеет.
Интересно, что сжатие и дедупликация прекрасно дополняют друг друга. Сначала дедупликация убирает крупные повторения между блоками, потом сжатие оптимизирует оставшиеся уникальные данные. Вместе они могут сократить объём хранения в 5-10 раз на типичных корпоративных данных. На виртуальных машинах результаты ещё впечатлительнее — 20-кратное сокращение не редкость.
Виртуализация: где дедупликация раскрывается во всей красе
Виртуализированные среды — это просто рай для дедупликации. Представьте: у вас сто виртуальных машин с Windows Server. В каждой — одинаковая ОС, одинаковые системные библиотеки, часто одинаковое ПО. Без дедупликации вы храните сто копий Windows. С дедупликацией — одну копию плюс уникальные данные каждой машины.
VMware vSAN, Nutanix, HPE SimpliVity — все ведущие платформы виртуализации встроили дедупликацию прямо в свою архитектуру. И это не просто экономия места. Меньше данных — быстрее репликация между площадками, быстрее бэкапы, меньше нагрузка на сеть при миграции виртуальных машин.
Но есть и обратная сторона медали. Все эти виртуалки теперь зависят от одних и тех же блоков данных. Повредился блок с системной библиотекой — пострадают все машины, которые на него ссылаются. Поэтому критически важна надёжность хранения дедуплицированных данных. Современные СХД решают эту проблему через избыточность — критичные блоки хранятся в нескольких копиях, даже после дедупликации.
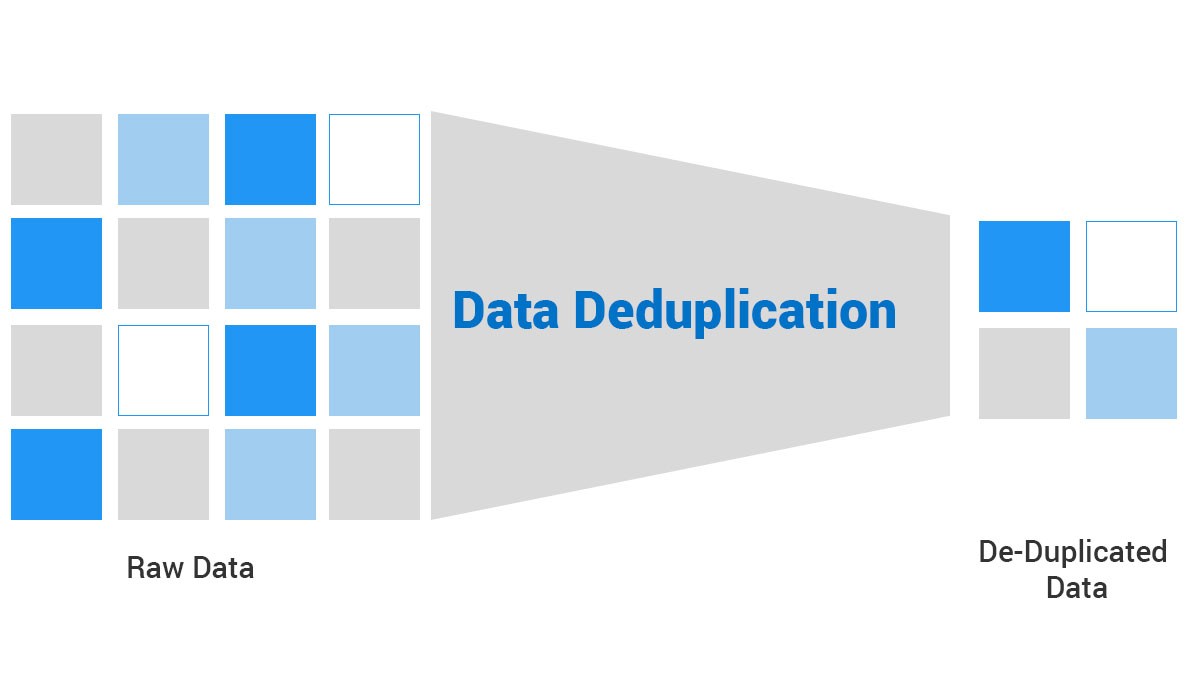
Резервное копирование: где экономия измеряется терабайтами
Если виртуализация — это хорошая площадка для дедупликации, то системы резервного копирования — это её звёздный час. Подумайте сами: вы делаете полный бэкап сервера каждую неделю. Между бэкапами меняется может 5-10% данных. Без дедупликации каждый бэкап — это полная копия. С дедупликацией — только изменившиеся блоки.
Veeam, Commvault, Veritas NetBackup — все современные системы резервного копирования используют дедупликацию как базовую технологию. Результаты впечатляют: коэффициент дедупликации 20:1 или даже 50:1 — обычное дело для долгосрочных архивов. Это значит, что вместо 50 терабайт бэкапов вы храните всего один терабайт уникальных данных.
Более того, дедупликация работает не только внутри одного сервера, но и между разными системами. Есть файл, который хранится на десяти серверах? В дедуплицированном хранилище он займёт место только один раз. Это называется глобальной дедупликацией, и это одна из причин, почему современные backup-решения так эффективны.
Подводные камни: о чём молчат маркетологи
Теперь о том, о чём обычно не пишут в рекламных брошюрах. Дедупликация — это не волшебная палочка, у неё есть своя цена.
Во-первых, производительность. Да, вы экономите место, но процессор работает интенсивнее. На высоконагруженных системах с большим потоком случайных операций ввода-вывода дедупликация может стать узким местом. Особенно это заметно на системах с inline-дедупликацией при интенсивной записи.
Во-вторых, память. Для быстрой работы система должна держать в оперативной памяти индекс всех дедуплицированных блоков. Чем больше уникальных блоков, тем больше нужно RAM. На петабайтных хранилищах счёт может идти на сотни гигабайт оперативной памяти только для индексов дедупликации.
В-третьих, риск коллизий хешей. Вероятность того, что два разных блока данных дадут одинаковый хеш, ничтожно мала (для SHA-256 это примерно 1 к 10^77), но она не нулевая. Поэтому критически важные системы часто используют дополнительную проверку — побайтовое сравнение блоков с одинаковыми хешами.
Железо против софта: вечный спор
Реализовать дедупликацию можно по-разному. Программная дедупликация работает на уровне операционной системы или приложения. Windows Server Deduplication, ZFS dedup, btrfs — примеры программных решений. Плюсы очевидны: гибкость, низкая стоимость входа, возможность использовать на любом железе. Минусы тоже: нагрузка на центральный процессор, потребление оперативной памяти.
Аппаратная дедупликация выполняется специализированными чипами прямо в контроллере СХД. HPE StoreOnce, Dell EMC Data Domain — классические примеры. Производительность выше, нагрузка на сервер нулевая, но и стоимость решения вырастает значительно. Плюс вы привязываетесь к конкретному вендору и его экосистеме.
Появляются и гибридные решения, где часть работы делает специализированное железо (например, вычисление хешей), а часть — программное обеспечение. Это попытка найти золотую середину между производительностью и стоимостью.
Что дальше: взгляд в будущее
Технологии дедупликации и сжатия продолжают развиваться. Машинное обучение уже используется для предсказания, какие данные стоит дедуплицировать в первую очередь, а какие лучше оставить как есть. Системы учатся распознавать паттерны использования данных и оптимизировать свою работу под конкретную нагрузку.
Развивается и интеграция с другими технологиями. Дедупликация всё теснее связывается с tiering (распределением данных по уровням хранения), репликацией, системами аналитики. СХД превращаются в интеллектуальные системы, которые не просто хранят данные, но и активно оптимизируют их размещение и представление.
NVMe и persistent memory открывают новые возможности для дедупликации. Сверхбыстрые накопители позволяют выполнять inline-дедупликацию даже на высоконагруженных системах без заметной деградации производительности. А persistent memory идеально подходит для хранения индексов дедупликации — скорость как у RAM, но данные сохраняются при перезагрузке.
Практический взгляд: что выбрать для вашего бизнеса
Выбор технологии дедупликации и сжатия зависит от ваших задач и данных. Для систем резервного копирования дедупликация практически обязательна — экономия места перевешивает все возможные недостатки. Для виртуализации — тоже однозначное "да", особенно если у вас много однотипных виртуальных машин.
А вот для баз данных с высокой нагрузкой стоит подумать. Если это OLAP-система с редкими, но объёмными загрузками данных — дедупликация может помочь. Если OLTP с постоянным потоком мелких транзакций — скорее всего, игра не стоит свеч.
Интересный компромисс — селективная дедупликация. Вы указываете системе, какие данные дедуплицировать (например, архивы и бэкапы), а какие оставить как есть (горячие базы данных). Многие современные СХД поддерживают такой режим работы.
Технологии дедупликации и сжатия данных уже стали неотъемлемой частью современных систем хранения. Они позволяют компаниям справляться с экспоненциальным ростом данных без пропорционального увеличения расходов на хранение. Да, это не серебряная пуля, и у технологии есть свои ограничения. Но для большинства корпоративных сценариев преимущества значительно перевешивают недостатки.
Главное — понимать, где и как применять эти технологии. Не нужно включать дедупликацию везде только потому, что она есть. Но и игнорировать возможность сократить объём хранения в 5-10 раз тоже неразумно. Как всегда в IT, ключ к успеху — в понимании своих данных и задач. А дедупликация и сжатие — это просто инструменты, которые при правильном применении могут сэкономить вам много денег и нервов.







