Мониторинг микросервисной архитектуры: распределенная трассировка

Пользователь нажимает кнопку "Купить" в интернет-магазине. Казалось бы, простое действие. Но за кулисами разворачивается сложная симфония: проверка товара в каталоге, валидация пользователя, обращение к платежной системе, резервирование на складе, отправка email-уведомления, обновление рекомендательной системы. Двенадцать микросервисов, пять баз данных, три внешних API — и все это должно работать слаженно за доли секунды.
А теперь представьте, что что-то пошло не так. Заказ не оформился, пользователь получил ошибку 500, а вы не знаете, где именно сломалась цепочка. В монолитном приложении проблему можно было найти по стек-трейсу. В микросервисной архитектуре запрос проходит через десятки сервисов, каждый из которых ведет свои логи, и связать их в единую картину становится практически невозможным.
Именно здесь на сцену выходит мониторинг микросервисов — технология, которая позволяет проследить путь каждого запроса через всю распределенную систему. Без этого инструмента отладка микросервисов превращается в игру в угадайку, где каждый инцидент может растягиваться на часы поиска.
Особенно критична видимость для высоконагруженных систем, где на серверы для высоконагруженных приложений приходятся тысячи запросов в секунду, а каждый из них может затрагивать десятки микросервисов. Потеря производительности даже на миллисекунды может обернуться значительными потерями.
Анатомия сложности микросервисов
Микросервисная архитектура решает множество проблем монолитных приложений, но создает свои уникальные вызовы для мониторинга и диагностики.
Распределенная природа отказов
В монолитном приложении отказ обычно локализован — либо приложение работает, либо нет. В микросервисной архитектуре отказы имеют каскадный характер. Проблема в одном сервисе может привести к таймаутам в других, перегрузке резервных инстансов и общей деградации производительности системы.
Частичные отказы — особенность микросервисных систем. Пользователь может успешно авторизоваться, добавить товар в корзину, но не смочь оформить заказ из-за проблем с платежным сервисом. Такие ситуации сложно выявить традиционными методами мониторинга "доступен/недоступен".
Временные проблемы становятся особенно коварными в распределенной среде. Кратковременное увеличение латентности в одном сервисе может привести к исчерпанию пула соединений в других сервисах, создавая эффект домино по всей системе.
Сетевая нестабильность
Микросервисы общаются по сети, что добавляет еще один уровень сложности. Задержки в сети, потеря пакетов, временные недоступности могут маскироваться под проблемы приложений. Без proper мониторинга сетевого взаимодействия сложно понять, где заканчиваются проблемы инфраструктуры и начинаются проблемы кода.
Балансировщики нагрузки, service mesh, прокси-серверы — все эти компоненты добавляют дополнительные точки отказа и усложняют диагностику. Запрос может проходить через множество промежуточных узлов, каждый из которых вносит свою латентность и может стать источником проблем.
Принципы распределенной трассировки
Distributed tracing серверы работают по принципу "следования за запросом" через всю распределенную систему. Каждый запрос получает уникальный идентификатор, который передается между всеми сервисами и позволяет связать разрозненные логи в единую картину.
Trace ID: нить Ариадны в лабиринте микросервисов
Каждый входящий запрос получает уникальный Trace ID — идентификатор, который путешествует вместе с запросом через все сервисы. Этот ID добавляется в заголовки HTTP-запросов, сообщения очередей, записи в базу данных — везде, где происходит взаимодействие между компонентами системы.
Propagation — процесс передачи контекста трассировки между сервисами — требует изменений в коде приложений. Библиотеки инструментирования автоматизируют этот процесс для популярных фреймворков, но кастомные интеграции могут потребовать ручной работы.
Baggage — дополнительная информация, которая передается вместе с трассировкой. Это могут быть идентификаторы пользователей, версии приложений, feature flags или любые другие данные, полезные для анализа.
Spans: строительные блоки трассировки
Каждая операция внутри трассировки представлена в виде span — структуры данных, которая содержит информацию о времени начала и завершения операции, метаданные и связи с другими операциями.
Иерархические отношения между spans отражают вложенность операций. Родительский span может представлять обработку HTTP-запроса, а дочерние spans — обращения к базе данных, вызовы других сервисов, выполнение бизнес-логики.
Tags и logs добавляют контекст к операциям. Tags — структурированные метаданные (пользователь, версия, статус ошибки), а logs — временные события с произвольными данными (исключения, отладочная информация).
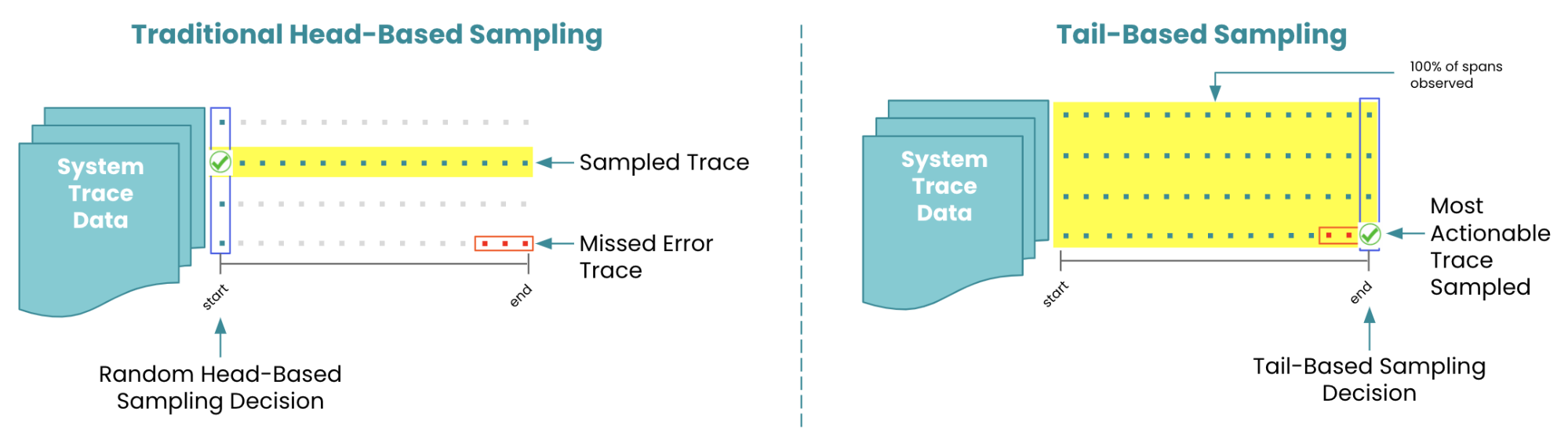
Sampling: баланс между полнотой и производительностью
Трассировка каждого запроса может создать огромную нагрузку на систему и привести к накоплению терабайтов данных. Sampling позволяет выбирать только определенный процент запросов для детальной трассировки.
Head-based sampling принимает решение о трассировке в начале запроса. Простые стратегии включают случайную выборку (каждый сотый запрос) или rate limiting (не более X трассировок в секунду). Более сложные алгоритмы могут учитывать тип запроса, пользователя или другие факторы.
Tail-based sampling анализирует полную трассировку и принимает решение о ее сохранении на основе результатов. Это позволяет сохранять все трассировки с ошибками и случайную выборку успешных запросов, но требует больше ресурсов для обработки.
Технологические стандарты и протоколы
Экосистема распределенной трассировки стандартизируется вокруг нескольких ключевых проектов и спецификаций.
OpenTelemetry: объединение усилий
OpenTelemetry представляет собой слияние проектов OpenTracing и OpenCensus и стремится стать единым стандартом для сбора телеметрии из приложений. Проект предоставляет SDK для большинства популярных языков программирования и автоматическое инструментирование для популярных библиотек.
Collectors обеспечивают гибкую обработку телеметрических данных. Они могут принимать данные в различных форматах, обрабатывать их (фильтрация, агрегация, обогащение) и отправлять в различные системы хранения.
Vendor-agnostic подход OpenTelemetry позволяет избежать привязки к конкретным решениям. Приложения инструментируются один раз, а данные могут отправляться в любые совместимые системы.
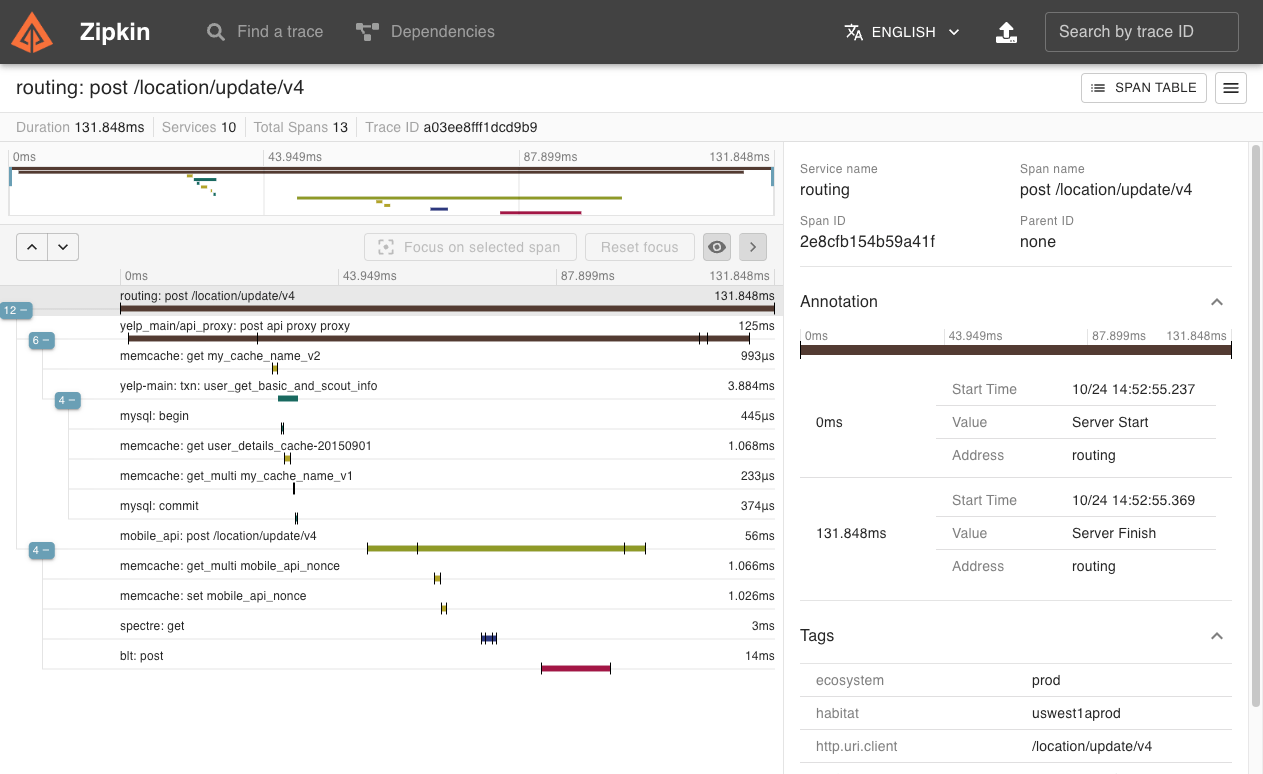
Jaeger и Zipkin: пионеры трассировки
Jaeger, разработанный в Uber, ориентирован на высокую производительность и масштабируемость. Он может обрабатывать миллионы spans в секунду и обеспечивает эффективное хранение данных в Elasticsearch, Cassandra или других backend'ах.
Zipkin, созданный в Twitter, фокусируется на простоте развертывания и использования. Он предлагает готовые решения для небольших и средних инсталляций, но может масштабироваться до enterprise нагрузок.
Совместимость между системами обеспечивается через стандартные форматы данных. Трассировки, собранные с помощью Jaeger, могут быть переданы в Zipkin и наоборот.
Service Mesh и автоматическая трассировка
Istio, Linkerd и другие service mesh решения предоставляют автоматическую трассировку без изменений в коде приложений. Sidecar прокси перехватывают весь сетевой трафик и автоматически добавляют трассировочную информацию.
Преимущества такого подхода включают нулевые изменения в коде, автоматическое покрытие всех сетевых взаимодействий и централизованную конфигурацию политик трассировки. Однако видимость ограничивается только сетевыми вызовами, и внутренняя логика приложений остается непрозрачной.
Комбинированный подход сочетает автоматическую трассировку от service mesh с ручным инструментированием критически важных участков кода приложений.
Архитектура систем трассировки
Эффективная система distributed tracing состоит из нескольких взаимосвязанных компонентов, каждый из которых решает свои специфические задачи.
Инструментирование приложений
Автоматическое инструментирование использует техники byte code modification или dynamic proxying для автоматического добавления трассировочного кода в приложения. Это работает для популярных фреймворков и библиотек, но может пропустить кастомную логику.
Ручное инструментирование дает полный контроль над тем, какие операции трассируются и какая информация собирается. Разработчики могут добавлять spans для бизнес-операций, включать релевантные метаданные и настраивать sampling на уровне кода.
Гибридный подход комбинирует автоматическое инструментирование для стандартных операций (HTTP-запросы, обращения к БД) с ручными spans для бизнес-логики.
Сбор и агрегация данных
Агенты трассировки работают на каждом сервере и собирают spans от локальных приложений. Они выполняют буферизацию, батчинг и первичную обработку данных перед отправкой в централизованные системы.
Коллекторы принимают данные от множества агентов, выполняют дополнительную обработку и маршрутизируют их в системы хранения. Они также могут выполнять sampling, фильтрацию и обогащение данных.
Load balancing между коллекторами обеспечивает горизонтальную масштабируемость системы сбора. При росте нагрузки можно добавлять новые инстансы коллекторов без изменения конфигурации приложений.
Хранение и индексация
Time-series базы данных оптимизированы для хранения больших объемов временных данных трассировки. Они обеспечивают эффективное сжатие, быстрые запросы по временным диапазонам и автоматическое удаление устаревших данных.
Индексирование метаданных позволяет быстро находить трассировки по различным критериям: сервису, операции, пользователю, статусу ошибки. Правильная стратегия индексирования критична для производительности поисковых запросов.
Партиционирование данных по времени и другим атрибутам позволяет оптимизировать хранение и обеспечивать параллелизм запросов. Старые данные могут храниться в более дешевых storage системах или удаляться автоматически.
Анализ и визуализация трассировок
Сбор данных — только первая часть задачи. Превращение raw данных трассировки в actionable insights требует продвинутых инструментов анализа и визуализации.
Waterfall диаграммы: анатомия запроса
Классическое представление трассировки в виде waterfall диаграммы показывает временную последовательность всех операций. Каждый span представлен в виде полосы, длина которой соответствует времени выполнения операции.
Критический путь — последовательность операций, которая определяет общее время выполнения запроса. Выявление узких мест на критическом пути позволяет сосредоточить усилия по оптимизации на наиболее важных компонентах.
Параллельные операции показывают возможности для дальнейшего распараллеливания. Операции, которые выполняются последовательно, но могут быть распараллелены, представляют потенциал для улучшения производительности.
Dependency mapping: карта взаимодействий
Анализ трассировок позволяет автоматически построить карту зависимостей между сервисами. Такая карта показывает, какие сервисы с какими взаимодействуют, частоту и характер этих взаимодействий.
Топология сервисов помогает понять архитектуру системы и выявить критические компоненты. Сервисы с большим количеством входящих соединений могут стать узкими местами, а сервисы с большим количеством исходящих соединений — источниками каскадных отказов.
Весовые характеристики связей показывают интенсивность взаимодействия между сервисами. Это помогает в планировании размещения сервисов, оптимизации сетевой топологии и выявлении аномальных паттернов взаимодействия.
Статистический анализ
Агрегация метрик по времени позволяет выявлять тренды в производительности системы. Постепенное увеличение латентности может сигнализировать о проблемах производительности, утечках памяти или росте нагрузки.
Процентильный анализ дает более полную картину распределения времени отклика, чем простые средние значения. 95-й и 99-й процентили показывают поведение системы в наихудших случаях, что критично для пользовательского опыта.
Сравнительный анализ различных версий приложений помогает оценить влияние изменений на производительность. A/B тестирование на уровне трассировки позволяет принимать обоснованные решения о внедрении новых версий.
Производительность и оптимизация
Системы трассировки сами по себе потребляют ресурсы и могут влиять на производительность мониторируемых приложений.
Overhead инструментирования
Сбор трассировочных данных добавляет накладные расходы на каждую операцию в приложении. Современные библиотеки стремятся минимизировать этот overhead, но в высоконагруженных системах даже миллисекунды могут быть критичными.
Асинхронная отправка данных отделяет процесс сбора от передачи данных. Spans буферизируются в памяти и отправляются в фоновом режиме, минимизируя влияние на латентность основных операций.
Адаптивный sampling может динамически изменять интенсивность трассировки в зависимости от нагрузки системы. При высокой нагрузке доля трассируемых запросов автоматически снижается для уменьшения overhead'а.
Масштабирование хранения
Объемы данных трассировки могут быть огромными. Крупные системы генерируют миллионы spans в час, что требует соответствующих возможностей хранения и обработки.
Горячие и холодные данные имеют разные требования к производительности доступа. Недавние трассировки нуждаются в быстром доступе для интерактивного анализа, а старые данные могут храниться в более медленных, но дешевых системах.
Компрессия и агрегация помогают снизить объемы хранимых данных. Старые трассировки могут быть агрегированы до статистических метрик, сохраняя важную информацию при значительном сокращении объема.
Интеграция с экосистемой мониторинга
Distributed tracing наиболее эффективна в сочетании с другими инструментами observability.
Корреляция с метриками и логами
Три столпа observability — метрики, логи и трассировки — дополняют друг друга и дают полную картину состояния системы. Метрики показывают что происходит, логи объясняют почему, а трассировки показывают где.
Trace ID в логах позволяет быстро переходить от анализа трассировки к детальным логам конкретных операций. Структурированное логирование с включением трассировочных идентификаторов автоматизирует этот процесс.
Метрики, извлеченные из трассировок, могут использоваться для алертинга и dashboards. RED метрики (Rate, Errors, Duration) или USE метрики (Utilization, Saturation, Errors) рассчитываются на основе трассировочных данных.
Алертинг на основе трассировок
Традиционные алерты основаны на метриках отдельных сервисов. Алерты на основе трассировок могут учитывать поведение всей системы end-to-end.
SLA мониторинг становится более точным с использованием трассировок. Вместо мониторинга отдельных компонентов можно отслеживать время выполнения полных пользовательских journey.
Аномальное поведение в паттернах трассировок может сигнализировать о проблемах раньше, чем традиционные метрики. Изменения в топологии вызовов или необычные паттерны ошибок могут предупредить о развивающихся проблемах.
Интеграция с APM платформами
Application Performance Monitoring платформы все чаще включают возможности distributed tracing как неотъемлемую часть. Это обеспечивает единообразный пользовательский опыт и упрощает корреляцию данных.
Автоматическое обнаружение проблем с использованием machine learning алгоритмов может анализировать паттерны трассировок для выявления аномалий и предсказания проблем.
Бизнес-метрики, извлеченные из трассировок, помогают связать техническую производительность с бизнес-результатами. Конверсия, revenue per request, customer satisfaction можно коррелировать с техническими метриками.