Мониторинг серверов Zabbix 2026: установка и контроль CPU/RAM
Три часа ночи, пятница. Телефон вибрирует — клиенты жалуются на тормоза. Вы заходите по SSH, запускаете htop и видите, что один из процессов сожрал 98% оперативной памяти. Сервер еле дышит. А ведь можно было узнать об этом за полтора часа до того, как упал response time — если бы стоял нормальный мониторинг.
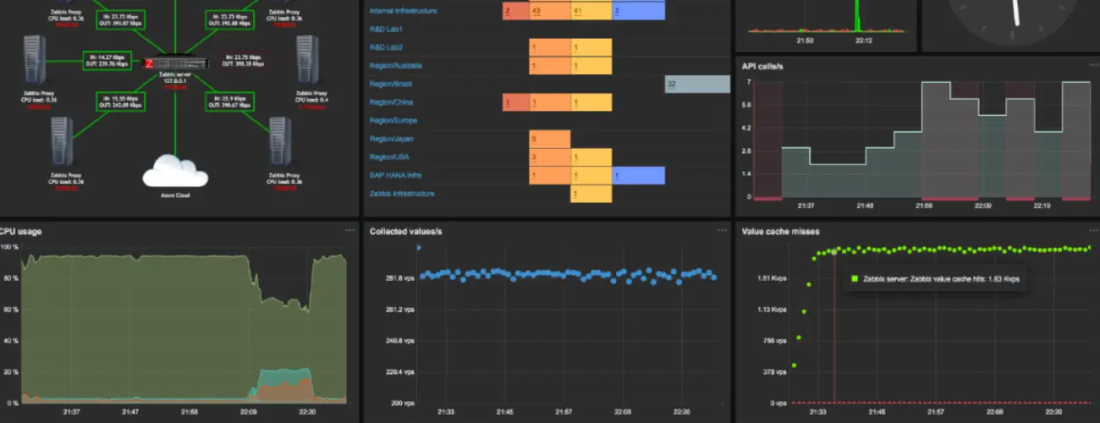
Zabbix — open-source платформа, которая закрывает эту задачу. 10 миллионов установок по миру, сбор данных в реальном времени с тысяч хостов, минимальная нагрузка на целевые машины. Сейчас актуальна ветка 7.4 (релиз — лето 2025), а LTS-версия 7.0 продолжает получать патчи. Разберём, как поднять сервер, настроить агенты и выстроить мониторинг linux серверов так, чтобы CPU и RAM были под контролем.
Что изменилось в ветке 7.x
Zabbix развивается быстро: за два года вышли 7.0 LTS, 7.2 и 7.4. Каждый релиз принёс что-то полезное для повседневной работы.
В 7.0 LTS появились асинхронные поллеры — вместо того чтобы ждать ответа от каждого хоста последовательно, сервер запускает до 1000 параллельных проверок. Это радикально ускорило сбор метрик в крупных инсталляциях. Тут же — балансировка нагрузки между прокси и их автоматическая отказоустойчивость. Если один прокси умирает, хосты автоматически переезжают на живой.
Версия 7.2 привезла Host Wizard — пошаговый мастер добавления хостов. Для тех, кто привык к ручной настройке, это может показаться мелочью. Но когда нужно ввести в мониторинг 50 новых серверов за день, визард экономит время. Тут же — мониторинг NVIDIA GPU через агент 2 и OAuth 2.0 для SMTP-уведомлений.
В 7.4 (текущий релиз) — вложенный LLD (Low-Level Discovery). Теперь можно строить цепочки обнаружения: найти гипервизоры → на каждом найти виртуальные машины → на каждой ВМ найти диски. Всё автоматически, без костылей. Плюс TLS-шифрование между фронтендом и сервером, которого ждали годами.
Установка Zabbix на Debian/Ubuntu
Развернуть сервер Zabbix можно за 15–20 минут. Ниже — последовательность для Debian 12 или Ubuntu 24.04 с PostgreSQL и Nginx. Если предпочитаете MySQL и Apache — принцип тот же, меняются только имена пакетов.
Подключаем репозиторий и ставим пакеты:
wget https://repo.zabbix.com/zabbix/7.4/release/debian/pool/main/z/zabbix-release/zabbix-release_latest+d...
dpkg -i zabbix-release_latest+debian12_all.deb
apt update
apt install zabbix-server-pgsql zabbix-frontend-php zabbix-nginx-conf zabbix-sql-scripts zabbix-agent2
Для Ubuntu 24.04 замените debian12 на ubuntu24.04 в URL пакета.
Создаём базу данных:
sudo -u postgres createuser --pwprompt zabbix
sudo -u postgres createdb -O zabbix zabbix
zcat /usr/share/zabbix/sql-scripts/postgresql/server.sql.gz | sudo -u zabbix psql zabbix
Прописываем пароль БД в /etc/zabbix/zabbix_server.conf:
Настраиваем Nginx — в файле /etc/zabbix/nginx.conf раскомментируйте директивы listen и server_name. Запускаем всё:
systemctl restart zabbix-server zabbix-agent2 nginx php8.2-fpm
systemctl enable zabbix-server zabbix-agent2 nginx php8.2-fpm
Открываете браузер, переходите на http://ваш_сервер — и попадаете в веб-установщик. Логин по умолчанию: Admin / zabbix. Первое, что стоит сделать после входа — сменить пароль.
Настройка Zabbix агента на целевых хостах
Установка zabbix на сервер — половина дела. Вторая половина — раскатать агенты. Zabbix agent 2 (написан на Go) умеет то, чего не умел первый агент: плагины для PostgreSQL, MySQL, Docker, Redis и десятков других сервисов прямо «из коробки».
На целевом хосте (Debian/Ubuntu):
wget https://repo.zabbix.com/zabbix/7.4/release/debian/pool/main/z/zabbix-release/zabbix-release_latest+d...
dpkg -i zabbix-release_latest+debian12_all.deb
apt update && apt install zabbix-agent2
Конфигурация агента — файл /etc/zabbix/zabbix_agent2.conf. Три параметра, которые нужно задать:
Server=IP_ВАШЕГО_ZABBIX_СЕРВЕРА
ServerActive=IP_ВАШЕГО_ZABBIX_СЕРВЕРА
Hostname=web-prod-01
Server — для пассивных проверок (сервер опрашивает агента). ServerActive — для активных (агент сам отправляет данные). Hostname должен совпадать с именем хоста в веб-интерфейсе Zabbix. Несовпадение — частая причина, почему данные «не приходят», и отладка занимает непропорционально много времени.
Для Astra Linux (на базе Debian) процедура та же, но используйте пакет для соответствующей версии Debian. Astra SE 1.7 — это Debian 10, Astra SE 1.8 — Debian 12.
Если у Вас Docker-инфраструктура, агент можно запустить контейнером:
docker run -d --name zabbix-agent2 \
-e ZBX_HOSTNAME="docker-host-01" \
-e ZBX_SERVER_HOST="IP_ZABBIX_СЕРВЕРА" \
--privileged --pid=host \
zabbix/zabbix-agent2:7.4-ubuntu-latest
Флаги --privileged и --pid=host нужны, чтобы агент видел процессы и ресурсы хоста, а не контейнера.
Мониторинг CPU: метрики и триггеры
После zabbix агент настройки пора перейти к метрикам. Стандартный шаблон «Linux by Zabbix agent» (идёт в комплекте) уже содержит основные items для CPU. Разберём, что именно он собирает и когда пора волноваться.
Ключевые метрики процессора:
| Метрика | Item key | Что показывает |
|---|---|---|
| Load Average (1/5/15 мин) | system.cpu.load[all,avg1] | Среднее число процессов в очереди выполнения |
| Утилизация user | system.cpu.util[all,user] | Время CPU в пользовательском пространстве, % |
| Утилизация system | system.cpu.util[all,system] | Время CPU в режиме ядра, % |
| Утилизация idle | system.cpu.util[all,idle] | Простой CPU, % |
| IO wait | system.cpu.util[all,iowait] | Ожидание I/O операций, % |
Load Average — коварная метрика. Значение 4.0 на одноядерном процессоре — катастрофа, на 64-ядерном EPYC — повод для зевоты. Поэтому шаблон нормализует значение: system.cpu.load[all,avg1] делится на число ядер (item system.cpu.num).
Zabbix поддерживает Low-Level Discovery для автоматического обнаружения ядер CPU. Это позволяет мониторить каждое ядро отдельно — удобно, когда нужно поймать процесс, который «прибит» к одному ядру (CPU pinning) и перегружает его, пока остальные 63 скучают.
Пример триггера для оповещения о высокой нагрузке:
Этот триггер сработает, если средняя утилизация CPU в user-space за 5 минут превысит 80%. Для продовых серверов 1С или тяжёлых баз данных порог можно поднять до 90% — они штатно нагружают CPU сильнее.
Для многопроцессорных систем (двухсокетные серверы на EPYC или Xeon) полезно мониторить не только общую утилизацию, но и распределение нагрузки между сокетами. Если один сокет загружен на 95%, а второй отдыхает на 10% — это сигнал о проблемах с NUMA affinity или неправильной привязке процессов.
Через UserParameter можно добавить кастомные метрики, которых нет в стандартном шаблоне:
UserParameter=cpu.context_switches,cat /proc/stat | awk '/ctxt/{print $2}'
UserParameter=cpu.interrupts,cat /proc/stat | awk '/intr/{print $2}'
Рост числа context switches часто указывает на конкуренцию потоков за процессорное время. Это особенно актуально для серверов 1С и СУБД, где сотни потоков конкурируют за ядра.
Настройка уведомлений в Telegram или Slack — отдельная тема. В Zabbix 7.x оба мессенджера поддерживаются как встроенные типы оповещений (Media types). Для Telegram достаточно указать токен бота и chat_id. Для Slack — настроить Incoming Webhook. Есть нюанс с эскалациями: можно построить цепочку «алерт в Telegram → если за 15 минут не подтвердили → SMS → если за 30 минут не решили → звонок дежурному». Это настраивается через Actions и Operations в веб-интерфейсе.
Контроль RAM и SWAP
Память — второй ресурс, за которым нужен глаз да глаз. Утечка памяти в приложении может «съесть» всю RAM за несколько часов, и сервер уйдёт в OOM Killer, прибивая случайные процессы (спойлер: он почти всегда убивает не тот процесс, который нужно).
| Метрика | Item key | Что показывает |
|---|---|---|
| Доступная память | vm.memory.size[available] | RAM, доступная приложениям (с учётом кэшей), байты |
| Доступная память, % | vm.memory.size[pavailable] | То же, в процентах |
| Свободный SWAP | system.swap.size[,free] | Свободное пространство SWAP, байты |
| Использованный SWAP, % | system.swap.size[,pfree] | Свободный SWAP, % |
| Общий объём RAM | vm.memory.size[total] | Полный объём физической памяти |
Ориентироваться стоит на vm.memory.size[available], а не на vm.memory.size[free]. Linux активно использует свободную RAM под дисковый кэш, и free почти всегда показывает значение близкое к нулю. Это нормально. А вот available учитывает кэши, которые ядро может освободить по требованию, — и даёт реальную картину.
Триггер для обнаружения утечки памяти:
avg(/Linux by Zabbix agent/vm.memory.size[available],1h) < 100M and
trend(/Linux by Zabbix agent/vm.memory.size[available],1h:now-1d) > 500M
Логика: если доступная RAM прямо сейчас меньше 100 МБ, а сутки назад в это же время было больше 500 МБ — вероятно, что-то течёт. Это грубый пример, но он работает как триггер для расследования.
Что касается SWAP — его активное использование на сервере (когда pfree падает ниже 50%) обычно означает, что RAM не хватает. Алерт на SWAP — не про SWAP. Он про то, что пора добавлять серверную оперативную память или разбираться, кто её потребляет.
Отдельная боль — виртуальные машины VMware. Гипервизор может балунить (memory ballooning) RAM у гостевой ОС, и внутри ВМ всё выглядит нормально, пока не начинаются тормоза. Zabbix умеет собирать метрики VMware через API — состояние ballooning, swapping на уровне гипервизора, overcommit ratio. Шаблон «VMware Guest» покрывает эти сценарии, а в 7.2 добавили мониторинг maintenance status гипервизора.
Для ИТ-руководителей, которые мыслят категориями ROI: один инцидент с OOM Killer на продуктивном сервере 1С в рабочее время — это час простоя 50+ пользователей. Посчитайте среднюю зарплату сотрудника в минуту, умножьте на 50 и на 60 — получите стоимость одной аварии. Мониторинг с предиктивными алертами (тренд потребления RAM растёт — оповещаем за 2 часа до кризиса) окупается за первый предотвращённый инцидент.
Шаблоны, LLD и интеграция с Grafana
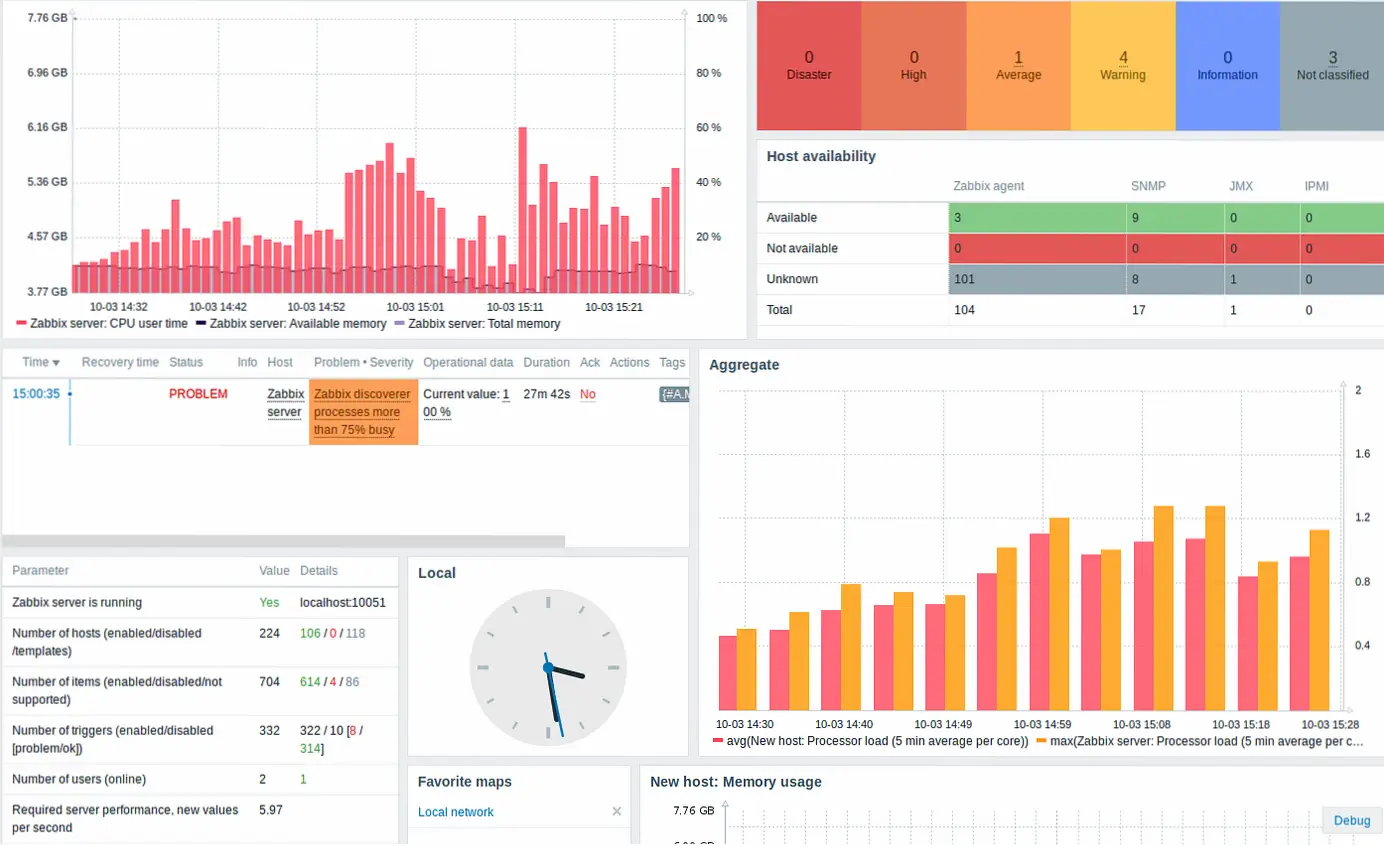
Zabbix идёт с набором готовых шаблонов — «Linux by Zabbix agent», «Linux by Zabbix agent active», шаблоны для конкретных СУБД, веб-серверов и оборудования. Шаблон для Linux покрывает CPU, RAM, SWAP, диски, сетевые интерфейсы и базовую информацию об ОС. Подключается к хосту в два клика.
Low-Level Discovery (LLD) — штука, ради которой стоит полюбить Zabbix. LLD автоматически находит файловые системы, сетевые интерфейсы, ядра CPU и создаёт items/triggers/graphs для каждого обнаруженного элемента. Добавили новый диск? Через 60 секунд (интервал discovery по умолчанию) он уже в мониторинге.
В 7.4 LLD стал вложенным: discovery-правило может содержать внутри себя другие discovery-правила. Практический пример: обнаружить все виртуальные машины на гипервизоре → внутри каждой ВМ обнаружить диски → для каждого диска создать метрики. Особенно полезно это для сред, где физические серверы конвертированы в виртуальные (P2V) и структура хранилищ неоднородна — раньше для этого приходилось городить скрипты и external checks.
Дашборды мониторинга в Zabbix — полноценный инструмент. Виджеты для графиков, Top hosts, проблемы, карты сети, SLA-отчёты. Но если хочется красивых дашбордов уровня «показать CTO на совещании», Grafana — проверенный выбор. Подключение Zabbix как Data Source в Grafana делается через официальный плагин:
grafana-cli plugins install alexanderzobnin-zabbix-app
systemctl restart grafana-server
После этого в Grafana добавляете Zabbix Data Source, указываете URL API (http://zabbix-server/api_jsonrpc.php), логин и пароль — и получаете доступ ко всем метрикам. Grafana хороша для агрегированных панелей: CPU по всем серверам на одном экране, топ-10 хостов по потреблению RAM, тренды загрузки за месяц.
Для продвинутых задач есть Zabbix API — полноценный JSON-RPC интерфейс. Через него можно писать скрипты на Python для автоматизации: массовое добавление хостов, генерация отчётов, интеграция с CMDB. Библиотека py-zabbix упрощает работу с API:
from pyzabbix import ZabbixAPI
zapi = ZabbixAPI("http://zabbix-server")
zapi.login("Admin", "zabbix")
# Получить все хосты с CPU load > 4
triggers = zapi.trigger.get(
only_true=True,
filter={"description": "CPU load"},
output=["triggerid", "description", "lastchange"]
)
Zabbix vs Prometheus: что выбрать
Вопрос «Zabbix или Prometheus» всплывает регулярно. Ответ зависит от инфраструктуры и задач.
| Критерий | Zabbix | Prometheus |
|---|---|---|
| Архитектура | Push/Pull, агенты + сервер | Pull (scrape), экспортеры |
| Конфигурация | Веб-интерфейс + API | YAML-файлы |
| Хранение данных | PostgreSQL / MySQL / TimescaleDB | Встроенная TSDB (retention ~15 дней по умолчанию) |
| Визуализация | Встроенные дашборды | Нужна Grafana |
| Alerting | Встроенный, эскалации, расписания | Отдельный компонент Alertmanager |
| Сетевое оборудование | SNMP, IPMI «из коробки» | Нужны экспортеры |
| Kubernetes | Поддерживается через Agent 2 | Нативная интеграция |
| Язык запросов | Item keys + простые выражения | PromQL (мощнее) |
Если у Вас «классическая» серверная инфраструктура — bare metal, виртуализация, сетевое оборудование — Zabbix закроет задачи одним инструментом. Он умеет SNMP, IPMI для аппаратного мониторинга (температуры, вентиляторы, состояние дисков в RAID-контроллерах), агентский мониторинг ОС и приложений, алерты с эскалациями. Для серверов Dell PowerEdge или HP ProLiant мониторинг через IPMI позволяет отслеживать аппаратное здоровье без установки агента — достаточно указать IP-адрес IPMI-интерфейса (iDRAC, iLO) и учётные данные.
Prometheus — выбор для cloud-native стека: Kubernetes, микросервисы, автоскейлинг. PromQL мощнее выражений Zabbix для аналитических запросов. Но у Prometheus нет встроенной визуализации (нужна Grafana), нет агентов для железа и ограниченный retention «из коробки».
Часто оба инструмента используют параллельно: Prometheus — для Kubernetes-кластеров, Zabbix — для остальной инфраструктуры. Grafana становится единым «стеклом» для обоих источников.
Что дальше: мониторинг как инвестиция
Каждая минута незапланированного простоя стоит денег. Для среднего бизнеса это от нескольких тысяч до десятков тысяч рублей в минуту — зависит от сервиса. Грамотно настроенный мониторинг превращает аварии из «пожара» в «предупреждение за 30 минут».
Начните с малого: поставьте Zabbix, подключите стандартные шаблоны для Linux, настройте алерты на CPU и RAM в Telegram. Это займёт час. Потом добавьте мониторинг дисков, сети, конкретных приложений. Подключите Grafana для красивых дашбордов. Напишите пару скриптов для автоматизации.
Zabbix — не единственный инструмент мониторинга. Но для серверной инфраструктуры в 2026 году он остаётся тем решением, которое работает сразу после установки и масштабируется от 5 хостов до 5000 без смены платформы. А ведь именно это и нужно, когда телефон звонит в три ночи.







