Мониторинг сетевой активности сервера: обнаружение аномалий
В половине третьего ночи сетевой интерфейс сервера внезапно начинает передавать данные со скоростью, в десять раз превышающей обычную. Антивирус молчит, система работает нормально, пользователей в это время нет. Что происходит? Криптомайнер? Утечка данных? А может быть, просто сбой в приложении, которое начало бесконечно дублировать запросы к базе данных?
Без грамотного мониторинга сетевой активности ответить на эти вопросы практически невозможно. Сеть — это кровеносная система любой IT-инфраструктуры, и аномалии в сетевом трафике часто становятся первыми симптомами серьезных проблем. Проблема в том, что современные серверы генерируют огромные объемы сетевого трафика, и выделить аномальные паттерны из этого потока данных — задача не для слабонервных.
Традиционный подход "посмотрим на графики пропускной способности" давно устарел. Злоумышленники научились маскировать свою активность под обычный трафик, а современные угрозы часто используют легитимные каналы связи для своих целей. Нужны более изощренные методы анализа, которые могут выявлять аномалии не только по объему трафика, но и по его характеру, временным паттернам и поведенческим особенностям.
Особенно важно это для корпоративного серверного оборудования, которое обслуживает критически важные бизнес-процессы. Простой из-за сетевых проблем или компрометация сервера могут обойтись значительно дороже, чем инвестиции в качественную систему мониторинга.
Анатомия сетевых аномалий
Прежде чем говорить о методах обнаружения, стоит разобраться в том, какие типы аномалий вообще существуют в сетевом трафике. Не все отклонения от нормы одинаково опасны, и важно уметь отличать реальные угрозы от безобидных флуктуаций.
Объемные аномалии
Самый очевидный тип нарушений — резкое изменение объема трафика. DDoS-атаки, вирусная активность или неконтролируемые процессы резервного копирования могут привести к многократному увеличению сетевой нагрузки.
Но объемные аномалии коварны своей кажущейся простотой. Современные угрозы часто используют медленные атаки, которые не создают заметных всплесков трафика. Постепенная утечка данных может выглядеть как обычная активность пользователей, а криптомайнеры часто ограничивают свою сетевую активность, чтобы не привлекать внимания.
Временные паттерны добавляют еще один слой сложности. Всплеск трафика в рабочее время может быть нормальным, а такой же всплеск ночью — поводом для беспокойства. Сетевая активность в выходные дни имеет свои особенности, которые нужно учитывать при анализе аномалий.
Поведенческие аномалии
Более изощренные угрозы проявляются через изменения в характере сетевого трафика. Сервер, который обычно принимает соединения, внезапно начинает активно инициировать исходящие подключения. Приложение, которое работало только с внутренними ресурсами, начинает обращаться к внешним адресам.
Изменения в протокольном составе трафика тоже могут сигнализировать о проблемах. Рост доли зашифрованного трафика может быть признаком компрометации, если происходит внезапно и без объяснимых причин. Появление необычных протоколов или портов часто указывает на нештатную активность.
Географические аномалии становятся все более актуальными в условиях глобализации киберугроз. Сервер, который обычно взаимодействует только с локальными ресурсами, внезапно начинает обмениваться данными с IP-адресами из стран, не связанных с деятельностью организации.
Временные аномалии
Многие типы вредоносной активности имеют характерные временные подписи. Боты часто активизируются в определенное время, криптомайнеры могут работать по расписанию, чтобы не мешать основной деятельности, а утечка данных часто происходит в нерабочее время.
Цикличность сетевой активности — важный индикатор для анализа. Здоровый сервер обычно демонстрирует предсказуемые паттерны нагрузки: пики в рабочее время, спады ночью и в выходные, сезонные колебания. Нарушение этих паттернов может указывать на проблемы.
Инструментарий современного сетевого мониторинга
Эффективный мониторинг сетевой активности требует комплексного подхода и использования различных инструментов, каждый из которых решает свои специфические задачи.
Анализ потоков данных
NetFlow, sFlow и IPFIX — стандартные протоколы для экспорта информации о сетевых потоках. Они позволяют получать детальную статистику о сетевом трафике без необходимости анализировать каждый пакет.
Коллекторы потоков агрегируют данные от сетевого оборудования и серверов, создавая централизованную картину сетевой активности. Современные коллекторы могут обрабатывать миллионы записей о потоках в секунду и предоставлять инструменты для их анализа в реальном времени.
Анализ метаданных потоков часто более эффективен, чем глубокая инспекция пакетов, особенно для обнаружения поведенческих аномалий. Информация о размерах пакетов, продолжительности соединений, количестве переданных байтов может многое рассказать о характере трафика.

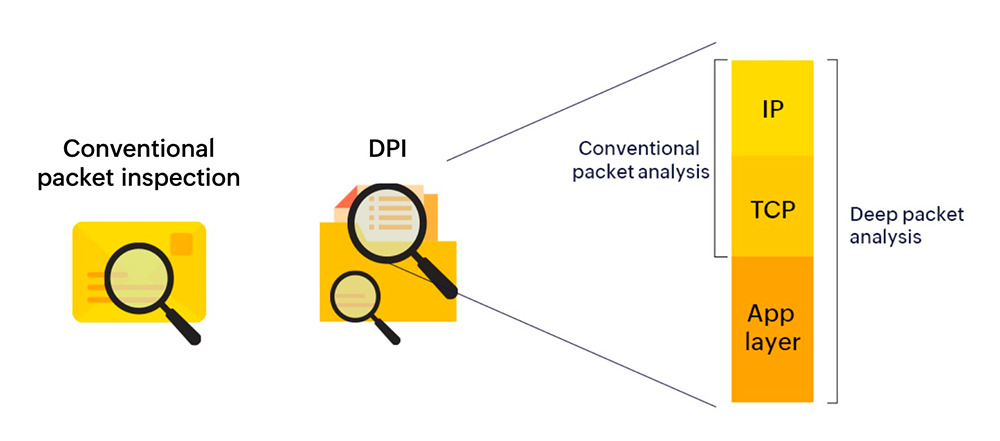
Глубокая инспекция пакетов
DPI (Deep Packet Inspection) позволяет анализировать содержимое сетевых пакетов, а не только их заголовки. Это открывает возможности для обнаружения более сложных угроз, которые могут скрываться внутри легитимного трафика.
Современные DPI решения используют сигнатурный анализ для выявления известных угроз и эвристические алгоритмы для обнаружения новых типов атак. Машинное обучение позволяет адаптироваться к эволюции угроз и выявлять ранее неизвестные паттерны вредоносной активности.
Однако DPI — ресурсоемкая технология, которая может создавать узкие места в высокопроизводительных сетях. Важно найти баланс между глубиной анализа и производительностью системы.
Поведенческая аналитика
Системы UEBA (User and Entity Behavior Analytics) фокусируются на анализе поведения сетевых сущностей — серверов, пользователей, приложений. Они строят профили нормального поведения и выявляют отклонения от установленных паттернов.
Машинное обучение играет ключевую роль в поведенческой аналитике. Алгоритмы анализируют исторические данные, выявляют закономерности и могут предсказывать аномалии на основе текущего поведения системы.
Адаптивные пороги позволяют системам автоматически подстраиваться под изменения в сетевой среде. Например, внедрение нового приложения может изменить паттерны трафика, и система должна адаптировать свои модели соответственно.
Системы мониторинга состояния сети в действии
Современные системы мониторинга состояния сети представляют собой сложные платформы, которые интегрируют множество технологий и подходов для обеспечения комплексной видимости сетевой активности.
Архитектура мониторинга
Эффективная система мониторинга состоит из нескольких уровней. Сенсоры сбора данных размещаются в ключевых точках сети и на серверах для получения максимально полной картины трафика. Они могут быть аппаратными или программными, в зависимости от требований к производительности и бюджета.
Уровень агрегации и предварительной обработки данных отвечает за фильтрацию шума, агрегацию метрик и первичный анализ аномалий. Здесь же происходит корреляция событий от различных источников для создания целостной картины происходящего.
Аналитический слой выполняет глубокий анализ данных с использованием статистических методов, машинного обучения и экспертных систем. Результаты анализа передаются в систему визуализации и оповещений для принятия решений операторами.
Интеграция источников данных
Комплексный мониторинг требует интеграции данных из множества источников. Сетевое оборудование предоставляет информацию о потоках и статистике портов. Серверы генерируют логи приложений и системные метрики. Системы безопасности добавляют контекст об угрозах и инцидентах.
Корреляция разнородных данных — один из ключевых вызовов современного мониторинга. События из различных источников нужно связать в единую временную линию и найти причинно-следственные связи между ними.
Нормализация данных обеспечивает единообразие форматов и терминологии. Различные системы могут использовать разные способы представления IP-адресов, временных меток или идентификаторов пользователей, и все это нужно привести к общему стандарту.
Автоматизация обнаружения аномалий
Ручной анализ сетевого трафика становится практически невозможным в условиях современных объемов данных. Автоматизация — не роскошь, а необходимость для эффективного обнаружения аномалий.
Статистические методы
Базовые статистические методы остаются фундаментом многих систем обнаружения аномалий. Анализ отклонений от среднего значения, построение доверительных интервалов и оценка стандартных отклонений позволяют выявлять простые объемные аномалии.
Временной анализ добавляет важное измерение к статистическим методам. Сезонная декомпозиция позволяет выделить долгосрочные тренды, сезонные колебания и случайные флуктуации. Аномалии выявляются как значительные отклонения от предсказанных значений.
Многомерный анализ учитывает взаимосвязи между различными метриками. Изолированное увеличение объема трафика может быть нормальным, но в сочетании с изменением географического распределения соединений может указывать на проблему.
Машинное обучение в сетевом мониторинге
Алгоритмы кластеризации группируют похожие типы сетевой активности и выявляют паттерны, которые не укладываются в существующие кластеры. Новые типы активности автоматически привлекают внимание как потенциальные аномалии.
Нейронные сети, особенно автоэнкодеры, эффективны для обнаружения сложных аномалий в многомерных данных. Они обучаются воспроизводить нормальные паттерны трафика, и высокая ошибка реконструкции сигнализирует об аномалии.
Алгоритмы классификации могут быть обучены на размеченных данных для автоматического распознавания известных типов угроз. Ensemble методы комбинируют предсказания нескольких алгоритмов для повышения точности и снижения количества ложных срабатываний.
Адаптивные системы
Статические правила и пороги быстро устаревают в динамичной сетевой среде. Адаптивные системы автоматически корректируют свои параметры на основе изменений в инфраструктуре и паттернах трафика.
Обучение с подкреплением позволяет системам улучшать свою точность на основе обратной связи от операторов. Когда аналитик подтверждает или опровергает аномалию, система корректирует свои модели для улучшения будущих предсказаний.
Федеративное обучение открывает возможности для обмена знаниями между различными организациями без раскрытия конфиденциальных данных. Модели обнаружения угроз могут улучшаться за счет опыта всего сообщества.
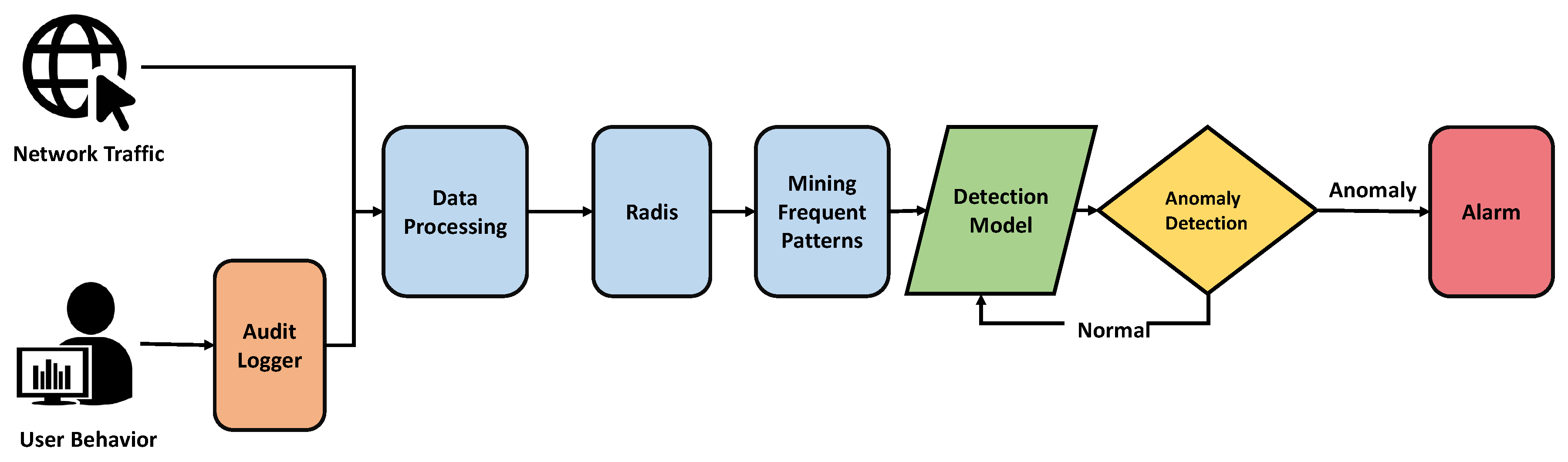
Интерпретация результатов и принятие решений
Обнаружение аномалии — только половина успеха. Не менее важно правильно интерпретировать результаты и принять адекватные меры реагирования.
Контекстуализация аномалий
Любая аномалия должна рассматриваться в контексте текущей ситуации в организации. Всплеск сетевой активности может быть связан с запланированными работами, внедрением нового ПО или изменениями в бизнес-процессах.
Корреляция с внешними событиями помогает отличить реальные угрозы от ложных срабатываний. Календарь событий организации, график обновлений ПО, информация о проводимых работах — все это должно учитываться при анализе аномалий.
Географический и временной контекст также критически важен. Сетевая активность с IP-адресов стран, где у организации есть офисы или партнеры, требует иной оценки, чем трафик из регионов без деловых связей.
Система приоритизации
Не все аномалии одинаково критичны, и система мониторинга должна помогать операторам сосредоточиться на наиболее важных событиях. Система оценки рисков должна учитывать тип аномалии, затрагиваемые активы, потенциальные последствия и достоверность обнаружения.
Автоматическая классификация аномалий по категориям помогает операторам быстро понять характер проблемы. Подозрение на утечку данных требует иного реагирования, чем предполагаемая DDoS-атака или технический сбой.
Эскалационные процедуры должны обеспечивать своевременное привлечение нужных специалистов. Сетевые аномалии могут требовать участия различных команд: сетевых администраторов, специалистов по безопасности, разработчиков приложений.
Автоматизация реагирования
Некоторые типы аномалий требуют немедленной реакции, которую невозможно обеспечить при ручном режиме работы. Автоматические ответные меры могут значительно сократить время реагирования на инциденты.
Блокировка подозрительного трафика может быть первой линией защиты против атак. Однако автоматическая блокировка должна быть тщательно настроена, чтобы не нарушить работу легитимных сервисов.
Изоляция скомпрометированных систем помогает предотвратить распространение угрозы. Автоматическое переключение трафика на резервные системы может обеспечить непрерывность работы сервисов во время инцидента.
Интеграция с общей системой мониторинга
Мониторинг сетевой активности не должен существовать в изоляции от других систем наблюдения за IT-инфраструктурой. Интеграция с системами мониторинга серверов, приложений и безопасности создает синергетический эффект и повышает общую эффективность обнаружения проблем.
Корреляция с метриками инфраструктуры
Сетевые аномалии часто связаны с проблемами на уровне инфраструктуры. Высокая загрузка процессора может привести к задержкам в сетевой обработке. Проблемы с дисками могут вызвать изменения в паттернах сетевого трафика приложений.
Совмещение временных рядов различных метрик помогает выявить причинно-следственные связи между событиями. Визуализация корреляций в едином интерфейсе ускоряет диагностику и помогает операторам быстрее находить корневые причины проблем.
Прогнозирование на основе комплексных данных более точно, чем анализ изолированных метрик. Модели машинного обучения могут учитывать взаимосвязи между сетевыми и системными параметрами для более точного предсказания проблем.
Единая панель управления
Консолидация информации из различных систем мониторинга в единой панели управления критически важна для эффективной работы операционных команд. Переключение между множественными интерфейсов замедляет анализ и увеличивает вероятность ошибок.
Настраиваемые дашборды позволяют различным ролям фокусироваться на релевантной информации. Сетевые администраторы, специалисты по безопасности и операторы приложений имеют разные потребности в информации, и интерфейс должен адаптироваться к этим потребностям.
Система уведомлений должна интеллектуально группировать связанные события и избегать спама неважными сообщениями. Контекстно-зависимые алерты, которые учитывают текущее состояние всей системы, более полезны, чем изолированные уведомления.
Вместо заключения:
Современные угрозы становятся все более изощренными, и традиционные методы мониторинга уже не справляются с их обнаружением. Успешная система мониторинга сочетает передовые технологии машинного обучения с глубоким пониманием специфики бизнеса и IT-процессов организации. Она должна быть достаточно чувствительной, чтобы выявлять слабые сигналы угроз, но при этом не создавать информационный шум ложными срабатываниями.







