Мониторинг виртуальных машин и контейнеров: инструменты и метрики
- Виртуальные машины vs контейнеры: в чём подвох для мониторинга
- Что мониторить в виртуальных машинах
- Метрики контейнеров: за чем следить в динамичном мире
- Инструменты: от классики до современных решений
- Автоматизация и алерты: как не проспать катастрофу
- Гибридный мониторинг: когда у вас есть всё
- Типичные грабли и как на них не наступить
- Будущее мониторинга: AI и предсказательная аналитика
- Практический результат
Современная IT-инфраструктура — это микс из виртуальных машин и контейнеров, каждый со своими особенностями и подводными камнями. ВМ работают как полноценные операционные системы и требуют соответствующего подхода к мониторингу. Контейнеры легче и быстрее, но их может быть сотни, и они постоянно создаются и умирают. И за этим миксом необходимо уследить с помощью правильно настроенного мониторинга.
Виртуальные машины vs контейнеры: в чём подвох для мониторинга
Прежде чем выбирать инструменты и метрики, давайте разберёмся, с чем имеем дело. Виртуальная машина — это полноценный виртуальный компьютер со своей ОС, ядром и всеми вытекающими. Она изолирована на уровне гипервизора и потребляет ресурсы как отдельный сервер. Контейнер же — это изолированный процесс, который делит ядро ОС с другими контейнерами и хост-системой.
Эта разница кардинально влияет на подход к мониторингу виртуальных машин. У ВМ вы отслеживаете полный стек: от виртуального железа до приложений. У контейнеров фокус смещается на процессы и их взаимодействие. ВМ живут месяцами и годами, контейнеры могут пересоздаваться каждые несколько минут.
| Параметр | Виртуальные машины | Контейнеры |
|---|---|---|
| Время запуска | Минуты | Секунды |
| Потребление ресурсов | Гигабайты RAM на ВМ | Мегабайты на контейнер |
| Изоляция | Полная на уровне гипервизора | На уровне процессов ОС |
| Жизненный цикл | Месяцы/годы | Минуты/часы/дни |
| Количество в типичной инфраструктуре | Десятки | Сотни/тысячи |
Из-за этих различий метрики контейнеров собираются и интерпретируются иначе. Если для ВМ нормально видеть стабильное потребление памяти в 8 ГБ, то контейнер, съедающий гигабайт — повод бить тревогу.
Что мониторить в виртуальных машинах
Виртуальная машина — это матрёшка из нескольких слоёв, и проблема может скрываться на любом из них. Базовый набор метрик включает:
CPU и его особенности. Смотрим не только на загрузку, но и на CPU Ready — время, которое ВМ ждёт доступа к физическому процессору. Если этот показатель выше 5%, у вас проблемы с распределением ресурсов на гипервизоре. Co-Stop показывает, сколько времени vCPU ждут друг друга — критично для многопроцессорных ВМ.
Память — не всё так просто. Кроме очевидного использования RAM, отслеживайте Memory Ballooning — когда гипервизор отбирает память у одной ВМ для другой. Swap на уровне гостевой ОС и на уровне гипервизора — это разные вещи, и оба могут убить производительность.
Дисковая подсистема и IOPS. Количество операций ввода-вывода в секунду часто становится узким местом. Отслеживайте не только IOPS, но и латентность — если задержка чтения превышает 20 мс, пользователи начнут замечать тормоза. Для баз данных критична латентность записи — даже 10 мс могут стать проблемой.
Сеть — невидимый убийца. Потеря пакетов даже в 0.1% может привести к деградации производительности TCP-соединений. Отслеживайте не только пропускную способность, но и количество retransmit'ов, латентность между ВМ, особенно если они на разных хостах.
Метрики контейнеров: за чем следить в динамичном мире
Контейнеры требуют другого подхода. Здесь важна не только текущая картина, но и динамика изменений. Основные метрики контейнеров, на которые стоит обратить внимание:
Количество и состояние контейнеров. Сколько контейнеров запущено, сколько в состоянии restart, сколько упало за последний час. Если контейнеры постоянно перезапускаются — это симптом серьёзных проблем.
CPU throttling. Контейнеры часто ограничены по CPU через cgroups. Метрика throttled_time показывает, сколько времени контейнер хотел работать, но не мог из-за лимитов. Высокие значения — признак того, что нужно пересмотреть лимиты или оптимизировать приложение.
Память и OOM killer. Контейнер, убитый из-за нехватки памяти — классика жанра. Отслеживайте не только текущее потребление, но и пиковые значения. Метрика memory.failcnt показывает, сколько раз контейнер пытался выделить память сверх лимита.
Сетевые соединения. В мире микросервисов контейнеры постоянно общаются друг с другом. Отслеживайте количество открытых соединений, время установления соединения, количество connection reset'ов.
Важная особенность: в облачных платформах вроде Yandex Cloud метрики контейнеров обновляются каждые 15 секунд. Это позволяет быстро реагировать на проблемы, но также генерирует огромный объём данных, который нужно правильно агрегировать и анализировать
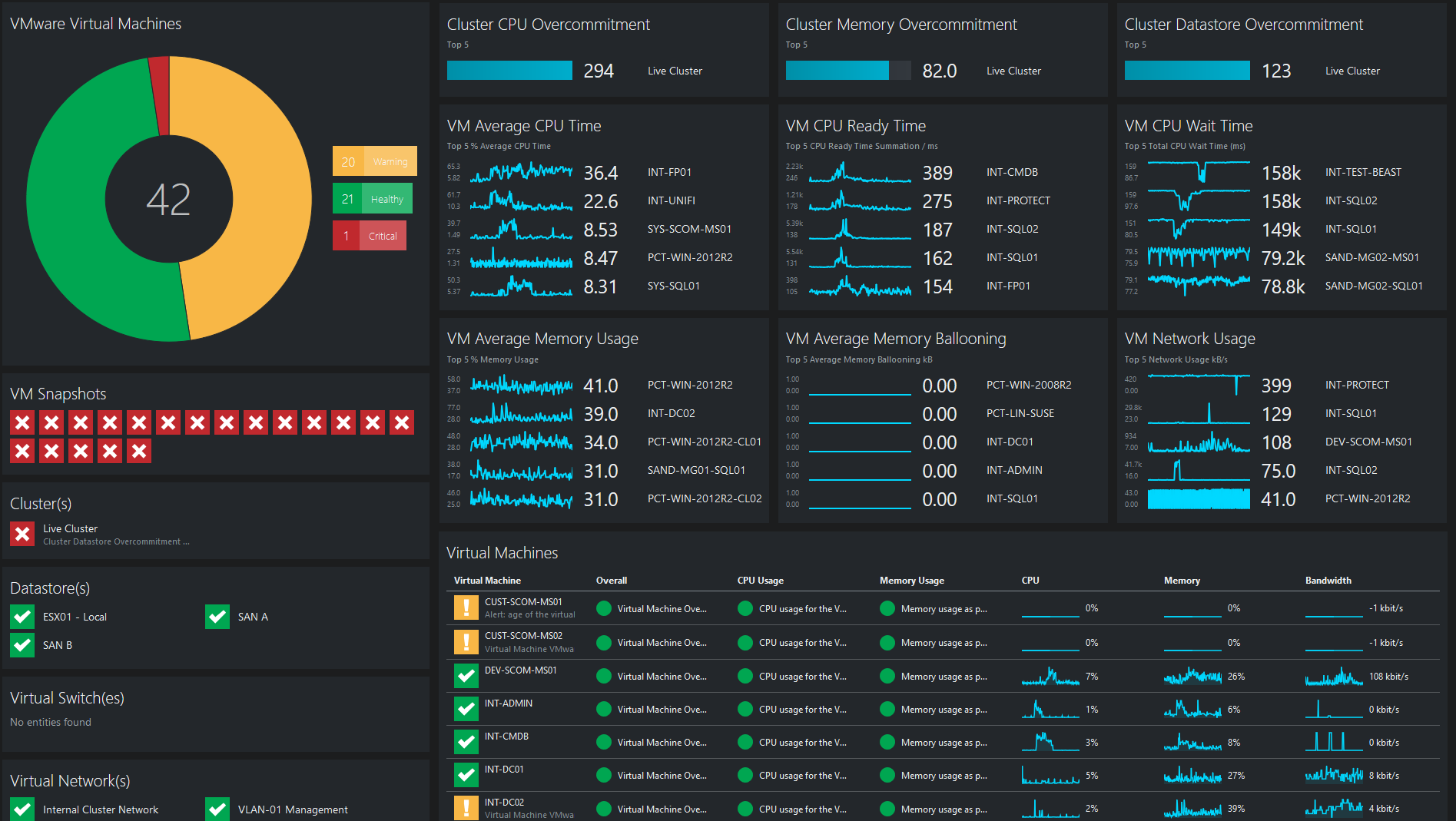
Инструменты: от классики до современных решений
Для виртуальных машин
Zabbix — старый добрый друг сисадминов. Бесплатный, с открытым исходным кодом, огромным сообществом и готовыми шаблонами для всего на свете. Удобный веб-интерфейс позволяет быстро настроить сбор метрик CPU, памяти, дисков и сети. Минус — требует времени на настройку и не очень дружелюбен к контейнерам.
VMware vRealize Operations — промышленный комбайн для тех, кто живёт в экосистеме VMware. Умеет не только собирать метрики, но и предсказывать проблемы с помощью машинного обучения. Определяет аномалии, строит прогнозы потребления ресурсов, даёт рекомендации по оптимизации. Минус — цена, которая может шокировать небольшие компании.
Nagios/Icinga — проверенные временем системы, которые отлично справляются с базовым мониторингом. Гибкие, расширяемые, но требуют прямых рук для настройки. Идеальны, когда нужен контроль над каждым аспектом мониторинга.
Для контейнеров
Prometheus + Grafana — золотой стандарт мониторинга контейнеров. Prometheus собирает метрики, Grafana красиво их визуализирует. Нативная поддержка Kubernetes, автообнаружение сервисов, мощный язык запросов PromQL. Бесплатно, открыто, с огромным количеством готовых дашбордов.
cAdvisor — специализированный инструмент от Google для сбора метрик контейнеров. Автоматически обнаруживает все контейнеры на хосте, собирает детальную статистику по CPU, памяти, сети и дискам. Экспортирует метрики в Prometheus, InfluxDB и другие системы. Лёгкий, не требует настройки — запустил и работает.
Datadog/New Relic — SaaS-решения для тех, кто готов платить за удобство. Автоматическое обнаружение сервисов, интеграция с сотнями технологий, мощная аналитика и алерты. APM-функциональность позволяет отслеживать производительность не только инфраструктуры, но и кода приложений.
Автоматизация и алерты: как не проспать катастрофу
Мониторинг без алертов — как пожарная сигнализация без звука. Настройка правильных уведомлений — это искусство балансирования между "пропустить критическую проблему" и "получать 100 алертов в час о ерунде".
Современные платформы позволяют настраивать многоуровневые алерты. Предупреждение при 70% загрузке CPU, критический алерт при 90%. Но не забывайте про корреляцию метрик — если одновременно растёт CPU и время отклика приложения, это важнее, чем просто высокая загрузка процессора.
Используйте разные каналы для разной критичности. Telegram для предупреждений, SMS для критических проблем, телефонный звонок для катастроф. И обязательно настройте эскалацию — если дежурный не отреагировал за 15 минут, алерт уходит руководителю.
Гибридный мониторинг: когда у вас есть всё
Согласно исследованию Flexera 2024 State of the Cloud Report, 89% компаний используют гибридную инфраструктуру, совмещая виртуальные машины и контейнеры. И это создаёт интересный вызов для мониторинга — нужно одновременно следить за медленными, стабильными ВМ и быстрыми, эфемерными контейнерами.
Используйте единую платформу визуализации. Grafana отлично справляется с этой задачей — может получать данные и от Zabbix (через плагин), и от Prometheus. Создавайте унифицированные дашборды, где рядом отображаются метрики ВМ и контейнеров, обслуживающих одно приложение.
Настройте сквозной мониторинг. Если ваше приложение использует базу данных в ВМ и микросервисы в контейнерах, отслеживайте полный путь запроса. Distributed tracing (Jaeger, Zipkin) поможет увидеть, где именно теряется время.
Типичные грабли и как на них не наступить
Переизбыток метрик. Соблазн мониторить всё подряд приводит к информационному шуму. Начните с базового набора и добавляйте метрики по мере необходимости. Лучше хорошо понимать 20 ключевых метрик, чем тонуть в тысячах непонятных графиков.
Игнорирование базовых проверок. Прежде чем внедрять сложные системы, убедитесь, что работает базовый мониторинг: пинг, доступность портов, свободное место на дисках. Количество раз, когда проблема была в забитом логами диске, исчисляется тысячами.
Отсутствие документации. Через полгода вы забудете, почему установили именно такой порог для алерта. Документируйте: какие метрики за что отвечают, какие пороги установлены и почему, что делать при срабатывании алерта.
Будущее мониторинга: AI и предсказательная аналитика
Современные системы всё чаще используют машинное обучение для анализа метрик. Они учатся понимать, что нормально для вашей инфраструктуры, и алертят об аномалиях, даже если формально все пороги в норме. Внезапный рост времени отклика на 50 мс может быть предвестником серьёзных проблем, хотя формально всё ещё в пределах SLA.
Предсказательная аналитика позволяет планировать масштабирование заранее. Система анализирует исторические данные и предупреждает: "При текущих темпах роста через две недели закончится место на диске" или "В Black Friday нагрузка превысит возможности инфраструктуры".
Практический результат
Правильно настроенный мониторинг виртуальных машин и контейнеров — это не просто красивые графики. Это спокойствие, когда вы точно знаете состояние своей инфраструктуры. Это быстрое решение проблем — вместо часов поиска вы за минуты находите корень проблемы. Это экономия — вы видите недоиспользуемые ресурсы и можете их перераспределить.
Начните с малого. Выберите один критичный сервис и настройте для него полноценный мониторинг. Определите ключевые метрики, настройте алерты, создайте дашборд. Когда увидите результат — масштабируйте подход на всю инфраструктуру.
Помните: мониторинг — это не разовая задача, а постоянный процесс. Инфраструктура меняется, появляются новые сервисы, меняются паттерны нагрузки. Регулярно пересматривайте метрики и пороги, обновляйте инструменты, обучайте команду. И тогда ваша инфраструктура не упадёт именно в тот момент, когда вы отошли за кофе.







