Предиктивный мониторинг: как предсказывать проблемы серверов

Представьте ситуацию: сервер с критически важной базой данных выходит из строя в самый неподходящий момент. Пользователи не могут работать, бизнес-процессы останавливаются, а IT-отдел в панике пытается восстановить работоспособность. Знакомая картина? Но что если я скажу, что подобных ситуаций можно избежать, предсказав проблему за несколько дней или даже недель?
Предиктивный мониторинг — это не фантастика, а реальность современных IT-инфраструктур. Эта технология позволяет анализировать поведение серверов, выявлять аномалии и предсказывать потенциальные отказы еще до их возникновения. Звучит как магия, но на самом деле за этим стоят математические алгоритмы, машинное обучение и грамотный анализ данных.
В эпоху, когда простой серверов может стоить компании тысячи рублей в час, способность предугадать проблемы становится не просто приятным бонусом, а необходимостью для выживания бизнеса. Особенно это актуально для офисной инфраструктуры, где даже базовый сервер в офис должен работать стабильно и предсказуемо.
Принципы работы предиктивного мониторинга
Традиционный мониторинг похож на пожарную службу — он реагирует на уже случившиеся проблемы. Вы получаете уведомление "диск переполнен" или "сервер недоступен", когда пользователи уже не могут работать. Прогнозирование проблем серверов работает совершенно иначе — оно анализирует тенденции и предупреждает о потенциальных проблемах задолго до их возникновения.
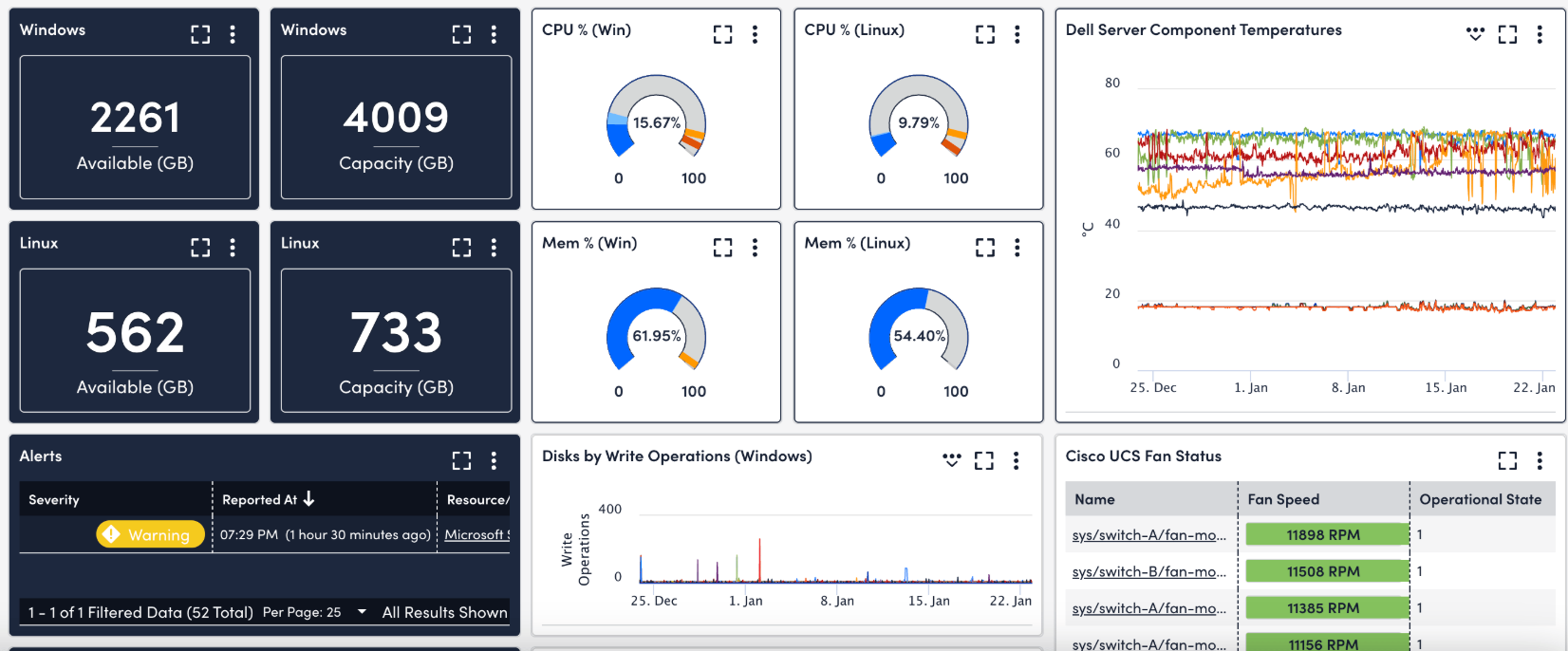
Основа предиктивного подхода — непрерывный сбор и анализ телеметрии. Каждую секунду сервер генерирует сотни метрик: загрузка процессора, использование памяти, температура компонентов, скорость работы дисков, сетевой трафик. Обычный мониторинг смотрит на эти показатели изолированно — превысил порог, отправил алерт. Предиктивная система рассматривает эти данные как многомерный временной ряд, ищет корреляции между различными метриками и выявляет паттерны, которые предшествуют отказам.
Например, система может заметить, что за две недели до отказа жесткого диска начинает расти время отклика на операции чтения, появляются периодические всплески активности контроллера диска, а количество переназначенных секторов медленно увеличивается. Каждый из этих показателей в отдельности может находиться в пределах нормы, но их комбинация сигнализирует о приближающейся проблеме.
Машинное обучение в действии
Сердце современного предиктивного мониторинга — алгоритмы машинного обучения. Но здесь важно понимать, что не существует универсального алгоритма, который подойдет для всех типов проблем. Различные задачи требуют разных подходов.
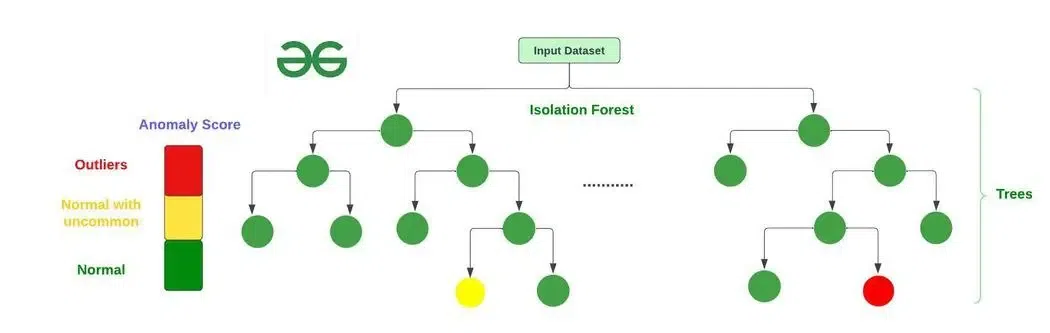
Обнаружение аномалий — первый рубеж защиты. Алгоритмы типа Isolation Forest работают по принципу "изоляции" необычных точек данных. Представьте, что вы пытаетесь найти единственный красный шар среди тысячи синих. Алгоритм строит случайные "разрезы" в пространстве данных и замечает, что красный шар изолируется гораздо быстрее — для его выделения требуется меньше разрезов. Точно так же аномальные значения метрик "выделяются" из общей массы нормальных данных.
Автоенкодеры — другой мощный инструмент для поиска аномалий. Это нейронные сети, которые учатся "сжимать" нормальные данные до компактного представления, а затем восстанавливать их обратно. Если сеть обучена на нормальных состояниях сервера, то при попытке восстановить аномальные данные она будет делать это с большой ошибкой. Высокая ошибка восстановления сигнализирует о том, что текущее состояние системы отличается от нормы.
Прогнозирование временных рядов решает задачу предсказания будущих значений метрик на основе исторических данных. LSTM сети (Long Short-Term Memory) особенно эффективны для этой задачи, поскольку способны "запоминать" долгосрочные зависимости в данных. Например, сеть может заметить, что загрузка процессора обычно растет по понедельникам утром, снижается в обед и имеет пики активности каждые три часа. Эти паттерны позволяют не только предсказать нормальное поведение, но и выявить отклонения от ожидаемых трендов.
Ключевые метрики и их интерпретация
Не все метрики одинаково ценны для предиктивного анализа. Важно сосредоточиться на показателях, которые действительно предсказывают проблемы, а не просто отражают текущее состояние системы.
Производительность процессора требует более глубокого анализа, чем просто процент загрузки. Важно отслеживать распределение нагрузки между ядрами, частоту переключений контекста, время ожидания ввода-вывода. Медленно растущая базовая загрузка может сигнализировать о утечке ресурсов в приложениях задолго до того, как система станет неотзывчивой.
Температурные показатели особенно важны для прогнозирования аппаратных отказов. Современные серверы имеют десятки температурных датчиков, и их показания нужно анализировать не изолированно, а в контексте нагрузки системы и условий окружающей среды. Постепенный рост температуры при неизменной нагрузке может указывать на проблемы с системой охлаждения или деградацию термоинтерфейса процессора.
Метрики памяти включают не только общее использование, но и паттерны выделения и освобождения памяти, активность swap-раздела, количество page faults. Медленные утечки памяти в приложениях часто проявляются как постепенный рост использования ОЗУ с характерными "ступенчатыми" скачками после перезапуска сервисов.
Состояние дисковой подсистемы критически важно для предсказания отказов накопителей. SMART-атрибуты жестких дисков предоставляют детальную информацию о состоянии механики, электроники и магнитных поверхностей. Однако интерпретация этих данных требует понимания специфики различных моделей дисков и их алгоритмов самодиагностики.
Архитектура предиктивных систем
Эффективная система предиктивного мониторинга — это сложный многокомпонентный организм, где каждая часть выполняет свою специфическую функцию.
Сбор данных начинается с агентов мониторинга, установленных на каждом сервере. Эти программы должны работать с минимальным влиянием на производительность системы, но при этом собирать достаточно детализированные данные. Частота сбора метрик — компромисс между детальностью мониторинга и нагрузкой на сеть и хранилище. Для большинства метрик достаточно интервала в 10-30 секунд, но критически важные показатели могут требовать более частого опроса.
Логи приложений содержат ценную информацию, но их обработка представляет отдельную сложность. Неструктурированные текстовые логи нужно парсить, извлекать из них значимые паттерны и преобразовывать в числовые метрики. Современные системы логирования позволяют структурировать данные в формате JSON, что существенно упрощает их последующий анализ.
Хранение временных рядов — критически важный компонент архитектуры. Обычные реляционные базы данных плохо подходят для хранения миллионов точек данных с временными метками. Специализированные time-series базы данных оптимизированы для таких задач и обеспечивают эффективное сжатие, быстрые запросы по временным диапазонам и автоматическое удаление устаревших данных.
Аналитический слой выполняет основную работу по предобработке данных и обучению моделей. Feature engineering — процесс создания новых признаков на основе исходных метрик — часто определяет успех всего проекта. Например, вместо использования абсолютных значений загрузки процессора может быть полезнее анализировать скорость изменения этого показателя или его отклонение от исторического среднего для данного времени суток.
Практические аспекты внедрения
Переход к предиктивному мониторингу — это не просто установка нового софта, а трансформация всего подхода к управлению IT-инфраструктурой. Успешное внедрение требует тщательного планирования и поэтапной реализации.
Начинать стоит с аудита существующей системы мониторинга. Многие организации собирают больше данных, чем думают, но не используют их эффективно. Возможно, у вас уже есть история метрик за несколько месяцев, которую можно использовать для обучения первых моделей.
Выбор пилотного проекта критически важен для первого опыта. Лучше всего начинать с систем, где стоимость простоя высока, но при этом есть достаточно исторических данных для анализа. Почтовые серверы, системы учета времени или файловые хранилища часто становятся хорошими кандидатами.
Обучение команды — неотъемлемая часть процесса внедрения. Администраторы должны понимать, как интерпретировать предиктивные алерты и какие действия предпринимать. Важно объяснить разницу между обычными алертами ("проблема случилась сейчас") и предиктивными ("проблема может случиться через неделю").
Настройка порогов и правил эскалации требует особого внимания. Слишком чувствительная система будет генерировать много ложных срабатываний, что приведет к "усталости от алертов". Слишком грубая настройка может пропустить реальные проблемы. Рекомендуется начинать с консервативных настроек и постепенно повышать чувствительность по мере накопления опыта.
Вызовы и решения
Внедрение предиктивного мониторинга сталкивается с рядом типичных проблем, большинство из которых имеют проверенные решения.
Качество данных — фундаментальная проблема любой аналитической системы. Пропуски в данных, выбросы из-за ошибок измерения, рассинхронизация временных меток между различными источниками — все это может серьезно повлиять на точность моделей. Необходимо внедрить процедуры валидации данных на этапе сбора и предобработки.
Дрейф модели — постепенное снижение точности предсказаний из-за изменений в инфраструктуре или нагрузке — типичная проблема в динамичных средах. Решение заключается в регулярном переобучении моделей на свежих данных и мониторинге качества предсказаний.
Интерпретируемость результатов часто становится камнем преткновения. IT-команды хотят понимать, почему система предсказывает проблему, чтобы принимать обоснованные решения. Современные техники объяснимого ИИ, такие как LIME или SHAP, помогают понять, какие факторы влияют на предсказания модели.
Ложные срабатывания — проблема, которая может подорвать доверие к системе. Важно настроить правильные метрики качества и постоянно отслеживать соотношение истинно положительных и ложно положительных предсказаний. Система должна "учиться" на своих ошибках и корректировать алгоритмы.
Измерение эффективности
Оценка эффективности предиктивного мониторинга требует комплексного подхода, включающего как технические, так и бизнес-метрики.
Точность предсказаний можно измерять различными способами. Precision показывает, какая доля предсказанных проблем действительно происходит. Recall отражает, какую долю реальных проблем система успевает предсказать. F1-score объединяет эти метрики в единый показатель качества.
Время упреждения — критически важная метрика, которая показывает, насколько заранее система предупреждает о проблемах. Слишком раннее предупреждение может быть неактуальным к моменту планового обслуживания, слишком позднее не дает времени на реакцию.
Бизнес-метрики часто более понятны руководству. Снижение времени внеплановых простоев, экономия на экстренном ремонте оборудования, улучшение пользовательского опыта — эти показатели напрямую влияют на итоговую прибыльность IT-операций.
Будущее технологии
Предиктивный мониторинг продолжает эволюционировать под влиянием новых технологических трендов. Автоматизированное машинное обучение упрощает создание и настройку моделей, делая эту технологию доступной для команд без глубокой экспертизы в области data science.
Edge computing приближает аналитику к источникам данных, что особенно важно для географически распределенных инфраструктур. Локальная обработка данных снижает латентность и уменьшает нагрузку на сеть.
Интеграция с платформами AIOps открывает возможности для полной автоматизации реакции на предиктивные алерты. Система может не только предсказать проблему, но и автоматически запланировать профилактическое обслуживание или перераспределить нагрузку между серверами.
Предиктивный мониторинг превращается из экзотической технологии в стандартный инструмент современных IT-операций.







