Сбор и визуализация метрик серверов: Prometheus и Grafana

- Prometheus: сердце современного мониторинга
- Архитектура и компоненты
- Модель данных и метрики
- Grafana: визуализация метрик сервера в действии
- Создание эффективных дашбордов
- Переменные и шаблоны
- Настройка и интеграция
- Конфигурация Prometheus
- Интеграция с Grafana
- Алертинг и уведомления
- Alertmanager
- Каналы уведомлений
- Производительность и масштабирование
- Оптимизация хранения
- Федерация и шардинг
- Короткое заключение:
Представьте ситуацию: в понедельник утром пользователи жалуются на медленную работу корпоративного портала. Администратор заходит на сервер, видит нормальную загрузку процессора и памяти, но не может понять, что именно происходило в выходные. Журналы показывают только текущее состояние, а картина происходившего накануне остается неясной.
Именно такие ситуации делают системы мониторинга не просто полезными, а жизненно необходимыми для современной IT-инфраструктуры. Нужны инструменты, которые непрерывно собирают данные о работе серверов и представляют их в понятном виде. Среди множества решений связка prometheus grafana серверы стала де-факто стандартом для мониторинга в современных дата-центрах.
Prometheus собирает и хранит метрики, а Grafana превращает сухие цифры в красивые графики и дашборды. Вместе они создают мощную платформу для понимания того, что происходит с вашей инфраструктурой. Особенно важно это для корпоративных развертываний, где сервер для предприятий может обслуживать сотни пользователей одновременно.
Prometheus: сердце современного мониторинга
Prometheus — это система мониторинга и оповещений с открытым исходным кодом, разработанная в SoundCloud и впоследствии принятая Cloud Native Computing Foundation. Но что делает его особенным среди множества других решений для мониторинга?
Основное отличие Prometheus от традиционных систем — модель сбора данных. Вместо того чтобы ждать, когда агенты на серверах отправят метрики, Prometheus активно "вытягивает" данные из настроенных источников. Этот подход называется pull-моделью и обеспечивает более надежный и предсказуемый сбор информации.
Архитектура и компоненты
Prometheus состоит из нескольких ключевых компонентов, каждый из которых выполняет свою специфическую роль в процессе мониторинга.
Центральный сервер Prometheus отвечает за сбор и хранение метрик. Он периодически опрашивает настроенные endpoint'ы, получает данные в специальном текстовом формате и сохраняет их в встроенной time-series базе данных. Частота опроса настраивается индивидуально для каждой цели — от нескольких секунд для критически важных метрик до минут для менее важных показателей.
Exporters — программы, которые преобразуют метрики различных систем в формат, понятный Prometheus. Node Exporter собирает системные метрики Linux-серверов: загрузку процессора, использование памяти, дисковое пространство, сетевой трафик. MySQL Exporter извлекает статистику из базы данных MySQL. Nginx Exporter предоставляет метрики веб-сервера. Существуют exporters практически для любого популярного софта.
Pushgateway позволяет отправлять метрики в Prometheus из batch-задач и скриптов, которые работают недостаточно долго для прямого опроса. Это особенно полезно для мониторинга регулярных заданий и cron-скриптов.
Service Discovery автоматически обнаруживает новые цели для мониторинга. В динамичных средах, где серверы создаются и удаляются автоматически, ручная настройка каждой цели становится неуправляемой. Prometheus может интегрироваться с Kubernetes, Consul, DNS и другими системами для автоматического обнаружения новых сервисов.
Модель данных и метрики
Prometheus использует многомерную модель данных, где каждая метрика определяется именем и набором меток (labels). Например, метрика http_requests_total{method="GET", endpoint="/api/users", status="200"} показывает общее количество HTTP-запросов с определенными характеристиками.
Эта модель обеспечивает невероятную гибкость в анализе данных. Вы можете агрегировать метрики по любым меткам, фильтровать по значениям, сравнивать различные срезы данных. PromQL — язык запросов Prometheus — позволяет выполнять сложные вычисления и анализ временных рядов.
Типы метрик в Prometheus охватывают большинство сценариев мониторинга. Counter увеличивается монотонно и подходит для подсчета событий: количества запросов, ошибок, отправленных байтов. Gauge может увеличиваться и уменьшаться, отражая текущее состояние: использование памяти, температуру, количество активных соединений. Histogram группирует наблюдения в настраиваемые buckets и подходит для измерения времени отклика или размеров запросов.
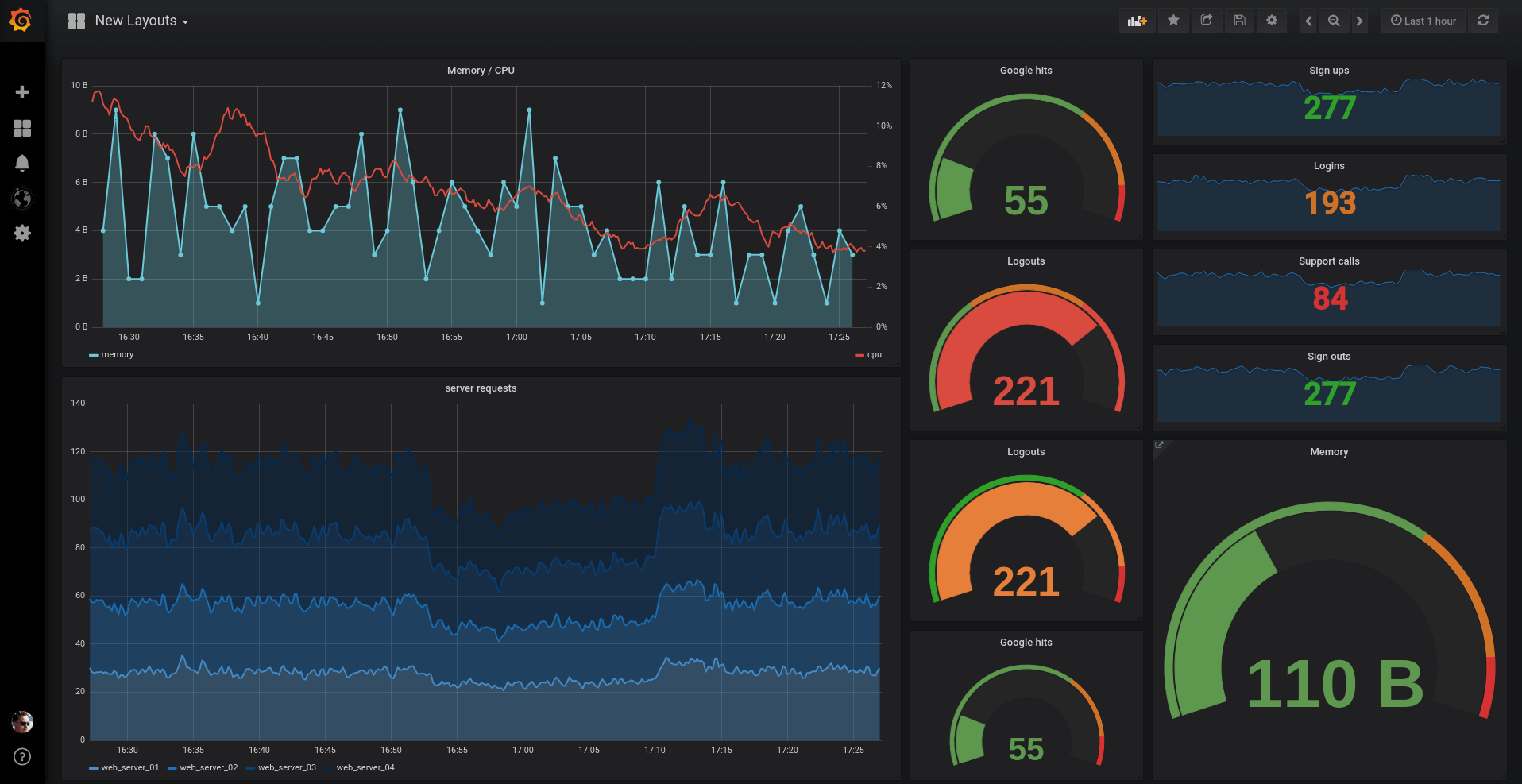
Grafana: визуализация метрик сервера в действии
Данные Prometheus ценны, но их raw-формат сложен для восприятия. Grafana превращает числовые временные ряды в интуитивно понятные графики, диаграммы и дашборды.
Grafana — веб-приложение для визуализации данных, которое может работать с десятками различных источников данных. Но именно интеграция с Prometheus сделала эту связку особенно популярной в мире DevOps.
Создание эффективных дашбордов
Хороший дашборд рассказывает историю о состоянии системы с первого взгляда. Не стоит размещать на одном экране все доступные метрики — это создает информационный шум и затрудняет анализ.
Иерархический подход к дашбордам работает лучше всего. Верхний уровень показывает общее состояние инфраструктуры: доступность сервисов, общую нагрузку, количество ошибок. Drill-down дашборды предоставляют детальную информацию о конкретных компонентах: метрики отдельного сервера, производительность базы данных, статистика приложения.
Выбор типа визуализации зависит от характера данных и цели анализа. Временные ряды идеально подходят для отображения трендов: загрузка процессора за последние 24 часа, рост объема данных в базе. Single stat панели показывают текущие значения ключевых метрик: количество активных пользователей, свободное место на диске. Heat maps эффективны для анализа распределений: время отклика запросов, нагрузка по времени суток.
Цветовое кодирование помогает быстро выявлять проблемы. Зеленый цвет для нормальных значений, желтый для предупреждений, красный для критических ситуаций. Пороговые значения можно настроить индивидуально для каждой панели, учитывая специфику конкретных метрик.
Переменные и шаблоны
Переменные в Grafana позволяют создавать универсальные дашборды, которые можно использовать для мониторинга различных серверов или сервисов. Вместо создания отдельного дашборда для каждого сервера вы создаете один шаблон с переменной $server, которая динамически изменяет отображаемые данные.
Query переменные автоматически заполняются из данных Prometheus. Например, переменная может содержать список всех доступных серверов, извлеченный из метрик. Пользователь может выбрать нужный сервер из dropdown-меню, и все панели дашборда автоматически обновятся.
Interval переменные позволяют пользователям изменять временное разрешение графиков. Для анализа долгосрочных трендов можно выбрать агрегацию по часам или дням, для детальной диагностики — по минутам или секундам.
Настройка и интеграция
Развертывание связки Prometheus и Grafana требует планирования архитектуры и понимания специфики инфраструктуры.
Конфигурация Prometheus
Файл конфигурации prometheus.yml определяет, откуда и как часто собирать метрики. Секция scrape_configs содержит список целей для мониторинга. Каждая цель может иметь свои параметры: интервал опроса, timeout, метки, аутентификацию.
Static_configs подходит для стабильных сред, где список серверов редко изменяется. Вы явно указываете IP-адреса и порты всех целей для мониторинга. Для динамичных сред лучше использовать service discovery — автоматическое обнаружение целей через DNS, Consul, Kubernetes API или другие механизмы.
Relabeling — мощный механизм для модификации меток метрик во время сбора. Можно переименовывать метки, добавлять новые на основе существующих, фильтровать ненужные метрики. Это особенно полезно для унификации схемы меток в гетерогенной среде.
Интеграция с Grafana
Подключение Prometheus как источника данных в Grafana — простая процедура, но важно правильно настроить параметры. URL должен указывать на HTTP API Prometheus, обычно это http://prometheus-server:9090. При использовании аутентификации нужно настроить соответствующие credentials.
Query timeout определяет максимальное время выполнения запросов. Слишком маленькое значение может приводить к ошибкам при выполнении сложных запросов, слишком большое — к зависанию интерфейса. HTTP method лучше оставить как GET, если не требуется передача больших запросов.
Организация дашбордов в папки помогает поддерживать порядок в больших инсталляциях. Можно создать папки по командам, типам сервисов, уровням инфраструктуры. Права доступа настраиваются на уровне папок, что позволяет разграничить доступ между различными группами пользователей.
Алертинг и уведомления
Сбор и визуализация метрик — только часть полноценной системы мониторинга. Автоматические уведомления о проблемах критически важны для поддержания работоспособности инфраструктуры.
Alertmanager
Prometheus включает встроенную систему алертинга, но для продвинутой функциональности используется отдельный компонент — Alertmanager. Он получает алерты от Prometheus и занимается их маршрутизацией, группировкой, подавлением дубликатов и отправкой уведомлений.
Правила алертов определяются в конфигурации Prometheus с помощью PromQL запросов. Можно настроить алерты на основе любых доступных метрик: высокую загрузку процессора, заполнение диска, недоступность сервиса, аномальное количество ошибок.
Группировка алертов предотвращает спам уведомлений. Если одновременно падают десять серверов в одном дата-центре, лучше получить одно сводное уведомление, чем десять отдельных. Alertmanager может группировать алерты по меткам: по локации, типу сервиса, команде ответственной за инфраструктуру.
Каналы уведомлений
Современные команды используют различные каналы коммуникации, и система алертинга должна интегрироваться с существующими инструментами. Email остается популярным для некритичных уведомлений. Slack и Teams хорошо подходят для командной работы и позволяют обсуждать инциденты в контексте алерта.
PagerDuty и аналогичные сервисы предназначены для критических уведомлений, которые требуют гарантированной доставки и эскалации. Они могут звонить, отправлять SMS, push-уведомления и автоматически эскалировать нерешенные инциденты.
Webhooks обеспечивают интеграцию с корпоративными системами управления инцидентами, ITSM платформами или custom решениями.
Производительность и масштабирование
По мере роста инфраструктуры объем собираемых метрик увеличивается экспоненциально. Prometheus, изначально разработанный для мониторинга отдельных сервисов, может столкнуться с ограничениями при масштабировании на тысячи серверов.
Оптимизация хранения
Prometheus использует собственный формат хранения временных рядов, оптимизированный для write-heavy нагрузок и эффективного сжатия. Данные группируются в блоки по временным промежуткам, обычно по 2 часа для новых данных.
Retention policy определяет, как долго хранить данные. Для большинства метрик достаточно 15-30 дней детальных данных. Более старые данные можно агрегировать или удалять. Некоторые организации настраивают долгосрочное хранение в объектных хранилищах вроде S3.
Сэмплирование помогает снизить объем данных без существенной потери информации. Вместо сбора метрик каждые 15 секунд можно увеличить интервал до минуты для несущественных показателей.
Федерация и шардинг
Prometheus federation позволяет создавать иерархические системы мониторинга. Локальные инстансы Prometheus собирают метрики в своих зонах ответственности, а центральный инстанс агрегирует важные метрики со всех локальных серверов.
Шардинг разделяет нагрузку между несколькими инстансами Prometheus. Каждый инстанс отвечает за мониторинг определенного набора сервисов или регионов. Grafana может работать с несколькими источниками данных одновременно, объединяя данные из различных шардов.
Кластерные решения вроде Thanos или Cortex предоставляют горизонтально масштабируемые альтернативы single-node Prometheus для enterprise инсталляций.
Короткое заключение:
Связка Prometheus и Grafana стала золотым стандартом мониторинга в современных IT-инфраструктурах благодаря гибкости, масштабируемости и богатому функционалу. Правильная настройка этих инструментов требует понимания специфики конкретной инфраструктуры и четкого планирования архитектуры мониторинга.







