SMART-мониторинг дисков на серверах: расшифровка показателей

Диск умирает не мгновенно — он долго посылает сигналы о помощи, которые администраторы должны уметь правильно интерпретировать. В три утра, когда сервер с критически важной базой данных внезапно становится недоступным, уже поздно вспоминать о том, что неделю назад система показывала странные значения каких-то там SMART атрибутов.
Проблема не в том, что современные диски ненадежны. Наоборот — они стали намного умнее своих предшественников и научились предупреждать о приближающихся проблемах. Но эти предупреждения зашифрованы в виде числовых кодов, таблиц атрибутов и статистических данных, которые выглядят как китайская грамота для неподготовленного человека.
smart мониторинг диска — это не просто периодическая проверка "жив-мертв". Это искусство чтения между строк, понимания того, как различные показатели связаны друг с другом и что они говорят о текущем состоянии и прогнозах на будущее. Особенно важно это для критически важных систем хранения данных, где отказ одного диска может парализовать работу целого предприятия.
Внутренний доктор каждого диска
Self-Monitoring, Analysis and Reporting Technology появилась в мире накопителей как ответ на растущую сложность и важность систем хранения данных. Каждый современный диск — это по сути маленький компьютер с собственным процессором, памятью и операционной системой, которая непрерывно следит за состоянием всех компонентов.
SMART работает как встроенная система медицинского мониторинга. Представьте пациента в реанимации, подключенного к множеству датчиков, которые отслеживают пульс, давление, температуру и десятки других параметров. SMART делает то же самое с диском — мониторит температуру, количество ошибок, скорость вращения, время поиска и множество других критически важных показателей.
Философия предиктивной диагностики
Главная ценность SMART заключается не в том, чтобы констатировать уже произошедший отказ, а в способности предсказать его заранее. Система анализирует тренды изменения различных параметров и может с высокой вероятностью определить, что диск начинает деградировать еще до того, как это станет заметно пользователям.
Однако SMART — это не хрустальный шар. Система может пропустить внезапные отказы, связанные с механическими повреждениями или скачками напряжения. Зато она отлично справляется с выявлением постепенной деградации, которая составляет большинство дисковых отказов.
Каждый производитель дисков реализует SMART по-своему, используя собственные алгоритмы расчета и интерпретации параметров. Это создает определенные сложности в интерпретации данных, но основные принципы остаются универсальными.

Анатомия SMART атрибутов
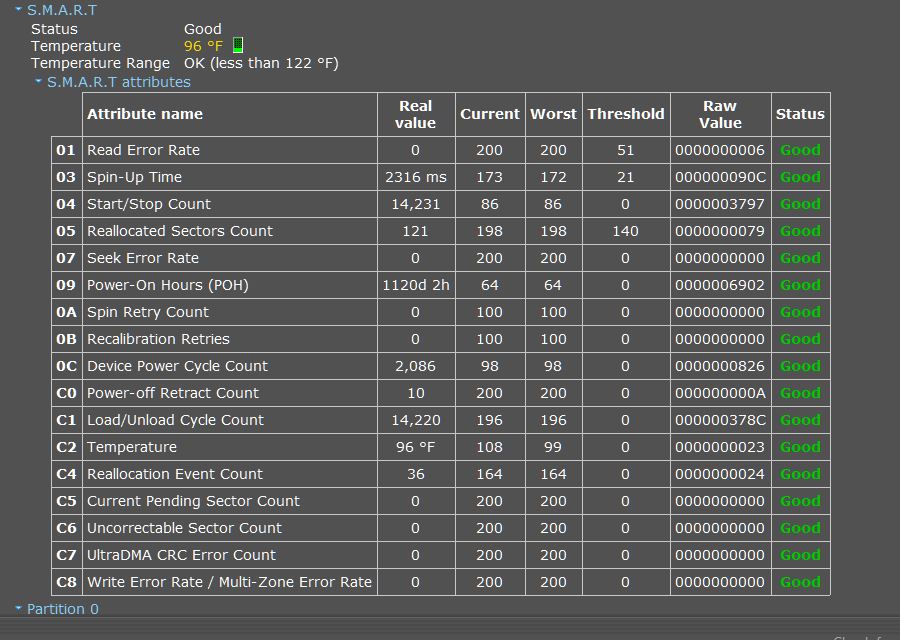
Каждый SMART атрибут — это многослойная структура данных, которая содержит не только текущее значение параметра, но и дополнительную информацию для его интерпретации.
Attribute ID — уникальный номер, который идентифицирует конкретный параметр. Например, атрибут 05 всегда означает количество переназначенных секторов, независимо от производителя диска.
Attribute Name — человекочитаемое название параметра. Здесь начинаются первые сложности — разные производители могут использовать разные названия для одного и того же атрибута.
Current Value — нормализованное значение от 1 до 253 (или 254), где более высокие числа обычно означают лучшее состояние. Производители используют собственные алгоритмы нормализации, поэтому сравнивать эти значения между дисками разных моделей не всегда корректно.
Worst Value — наихудшее значение, которое когда-либо достигал этот атрибут за время работы диска. Если Current Value равен Worst Value, это может означать, что параметр достиг критического уровня.
Threshold — пороговое значение, установленное производителем. Когда Current Value опускается ниже Threshold, диск считается неисправным с точки зрения SMART.
Raw Value — исходное, ненормализованное значение атрибута. Часто именно эти данные наиболее информативны для диагностики. Например, Raw Value для атрибута температуры покажет актуальную температуру в градусах Цельсия.
Критически важные атрибуты
показатели smart серверные диски включают несколько ключевых параметров, которые требуют постоянного внимания независимо от типа и производителя накопителя.
Reallocated Sectors Count (05) отслеживает количество секторов, которые диск пометил как ненадежные и заменил резервными. Любое ненулевое значение Raw Value — повод для беспокойства. Рост этого параметра указывает на прогрессирующую деградацию поверхности диска.
Spin-Up Time (03) измеряет время, необходимое для раскрутки шпинделя до рабочих оборотов. Увеличение этого времени может указывать на проблемы с двигателем или подшипниками. Для SSD этот атрибут не актуален.
Start/Stop Count (04) подсчитывает количество циклов запуска и остановки диска. Высокие значения могут указывать на частые включения/выключения, что не всегда хорошо для механических дисков.
Read Error Rate (01) отражает частоту ошибок чтения. Интерпретация этого атрибута сильно зависит от производителя — некоторые используют его для подсчета исправленных ошибок, другие — только неисправимых.
Seek Error Rate (07) показывает частоту ошибок позиционирования головок чтения/записи. Рост этого параметра может указывать на механические проблемы в системе позиционирования.
Power-On Hours (09) подсчитывает общее время работы диска. Это не прямой индикатор надежности, но полезная информация для оценки возраста накопителя и планирования замены.
Power Cycle Count (12) отслеживает количество циклов включения питания. Частые включения/выключения могут сократить срок службы диска.

Специфика мониторинга различных типов дисков
HDD и SSD имеют кардинально разную архитектуру, что отражается и на специфике их SMART атрибутов.
Особенности жестких дисков
Механические диски подвержены износу движущихся частей, что создает уникальные паттерны деградации.
Temperature (194) критически важен для HDD. Перегрев ускоряет деградацию магнитных свойств поверхности и может привести к деформации компонентов. Нормальная рабочая температура для большинства серверных дисков — 35-45°C. Превышение 50°C требует внимания к системе охлаждения.
Spin Retry Count (10) показывает количество попыток раскрутки шпинделя после неудачных стартов. Ненулевые значения могут указывать на проблемы с двигателем или блоком питания.
Calibration Retry Count (11) отслеживает неудачные попытки калибровки системы позиционирования головок. Рост этого параметра часто предшествует серьезным проблемам с позиционированием.
Head Flying Hours (240) подсчитывает время полета головок над поверхностью диска. Этот атрибут специфичен для некоторых производителей и помогает оценить износ головок чтения/записи.
Специфика SSD накопителей
Твердотельные накопители имеют свои уникальные механизмы деградации, связанные с особенностями флеш-памяти.
Wear Leveling Count отслеживает равномерность износа ячеек памяти. SSD контроллеры стараются распределить операции записи по всему объему накопителя, но со временем некоторые области могут изнашиваться быстрее других.
Program/Erase Cycle Count показывает количество циклов стирания/записи блоков памяти. У каждого типа флеш-памяти есть ограничение на количество циклов, после которого ячейки становятся ненадежными.
Available Reserved Space указывает остаток резервных блоков, которые SSD использует для замены изношенных ячеек. Когда этот ресурс исчерпывается, накопитель может перейти в режим только для чтения.
Media Wearout Indicator показывает общий уровень износа флеш-памяти. Значения близкие к нулю указывают на приближение конца жизни SSD.
Host Writes и NAND Writes отслеживают количество данных, записанных хостом и фактически записанных в флеш-память. Разница между этими значениями показывает эффективность алгоритмов сжатия и дедупликации.
Инструменты для анализа SMART данных
Эффективный мониторинг SMART требует правильных инструментов и понимания их возможностей.
Командная строка: smartctl
Утилита smartctl из пакета smartmontools — основной инструмент для работы с SMART данными в Linux. Команда smartctl -a /dev/sda выводит полную информацию о диске, включая все доступные атрибуты.
Параметр -H выполняет быструю проверку общего состояния диска. Результат "PASSED" означает, что критические атрибуты находятся в допустимых пределах, "FAILED" указывает на превышение пороговых значений.
Ключ -t short запускает короткий самотест, который обычно занимает несколько минут. Расширенный тест (-t long) может длиться несколько часов, но обеспечивает более тщательную проверку всех компонентов диска.
Команда smartctl -l error /dev/sda показывает журнал ошибок, который может содержать ценную информацию о характере проблем. Регулярные ошибки чтения определенных секторов или систематические проблемы с позиционированием головок могут указывать на развивающиеся дефекты.
Автоматизация и мониторинг
Демон smartd обеспечивает непрерывный мониторинг SMART атрибутов и может автоматически отправлять уведомления при обнаружении проблем. Конфигурационный файл /etc/smartd.conf позволяет настроить различные правила для разных типов дисков.
Директива DEVICESCAN автоматически обнаруживает все диски в системе и применяет базовые правила мониторинга. Для более точной настройки можно указать конкретные устройства и параметры отслеживания.
Опция -m настраивает email-уведомления при обнаружении проблем. Можно настроить различные уровни оповещений: от информационных сообщений до критических алертов.
Параметр -s настраивает автоматическое выполнение самотестов по расписанию. Например, -s (S/../.././02|L/../../6/03) запустит короткий тест каждый день в 2:00 и длинный тест каждую субботу в 3:00.
Интерпретация трендов и аномалий
Однократное чтение SMART атрибутов дает ограниченную информацию. Истинная ценность мониторинга раскрывается при анализе изменений параметров во времени.
Анализ трендов
Постепенное увеличение количества переназначенных секторов — тревожный сигнал, даже если текущие значения еще не критичны. Здоровый диск может годами работать с нулевыми значениями этого атрибута, а любой рост указывает на развивающиеся проблемы.
Медленное увеличение времени поиска или уменьшение скорости передачи данных может указывать на постепенную деградацию механических компонентов HDD. Эти изменения могут быть незаметны в повседневной работе, но четко видны при долгосрочном мониторинге.
Температурные флуктуации также заслуживают внимания. Постепенный рост рабочей температуры при неизменной нагрузке может указывать на проблемы с подшипниками, засорение системы охлаждения или деградацию термоинтерфейса.
Корреляционный анализ
Различные SMART атрибуты часто взаимосвязаны, и анализ этих связей может дать дополнительную информацию о состоянии диска.
Одновременный рост количества ошибок чтения и переназначенных секторов обычно указывает на проблемы с магнитной поверхностью диска. Увеличение времени поиска в сочетании с ростом ошибок позиционирования может сигнализировать о проблемах с системой позиционирования головок.
Для SSD важно отслеживать соотношение между количеством данных, записанных хостом, и фактическими записями в флеш-память. Растущее расхождение может указывать на проблемы с алгоритмами wear leveling или деградацию контроллера.
Система раннего предупреждения
Эффективный SMART мониторинг — это не просто сбор данных, а создание системы раннего предупреждения, которая позволяет принимать упреждающие меры.
Настройка пороговых значений
Стандартные пороги, установленные производителями, часто слишком консервативны для проактивного мониторинга. К моменту их срабатывания диск может быть уже на грани отказа.
Для критически важных систем стоит установить более жесткие пороги. Например, уведомление о появлении первых переназначенных секторов позволит запланировать замену диска заранее, не дожидаясь критических значений.
Пороги должны учитывать специфику рабочей нагрузки. Диски в системах с интенсивной записью могут показывать более высокий износ, что нормально для данного применения.
Интеграция с системами мониторинга
Современные системы мониторинга инфраструктуры должны включать SMART данные как неотъемлемую часть общей картины состояния серверов.
Prometheus может собирать SMART метрики через специальные exporters и интегрировать их с другими системными показателями. Grafana позволяет создавать комплексные дашборды, где SMART данные отображаются в контексте общей производительности системы.
Системы логирования могут агрегировать SMART события с другими системными сообщениями, обеспечивая централизованный анализ инцидентов. Корреляция SMART аномалий с проблемами производительности помогает быстрее выявлять связь между состоянием дисков и поведением системы.
Планирование замены и профилактики
SMART мониторинг должен быть частью общей стратегии управления жизненным циклом оборудования.
Предиктивная замена
Вместо ожидания отказа диска стоит планировать замену на основе SMART трендов. Диск с растущим количеством переназначенных секторов лучше заменить планово в удобное время, чем дожидаться экстренной ситуации.
Для критически важных систем можно использовать модель "двух страйков" — первый тревожный сигнал инициирует усиленный мониторинг, второй — плановую замену.
Ведение базы данных SMART параметров для всех дисков в инфраструктуре позволяет выявлять паттерны отказов и оптимизировать процедуры замены. Некоторые модели дисков могут иметь характерные "слабые места", знание которых помогает в планировании обслуживания.







