Кластеризация серверов и High Availability: как обеспечить 99.99% аптайма
52 минуты в год. Именно столько простоя допускает уровень 99.99% — то, что принято считать "нормальным" для серьёзной инфраструктуры. Звучит немного? До первого инцидента в пятницу вечером, когда упал платёжный шлюз и служба поддержки уже принимает звонки от агрессивных клиентов.
Но прежде чем говорить о том, как эти минуты не тратить, нужно разобраться с терминологией — потому что "кластер" и "HA-кластер" в большинстве разговоров используются как синонимы, хотя это принципиально два отличных понятия.
Кластер vs HA: в чём разница и почему это важно
Классический кластер — это горизонтальное масштабирование. Вы добавляете узлы, чтобы обслуживать больше запросов: тысячи пользователей, параллельные вычисления, распределённые базы данных. Главная цель — производительность.
HA-кластер (отказоустойчивый кластер) решает другую задачу. Его цель — не "выдержать нагрузку", а "не упасть". Репликация состояния, автоматический failover, мониторинг живости узлов — всё это про то, чтобы при отказе одного сервера система продолжала работать без вмешательства человека.
Часто эти подходы комбинируют: балансировка нагрузки через HAProxy или DNS round-robin распределяет трафик по нескольким активным узлам, а под капотом работает HA-механизм, который следит за тем, чтобы ни один узел не выпал незаметно. Такая конфигурация даёт прирост производительности на 200–300% под пиковой нагрузкой — с сохранением гарантий доступности.
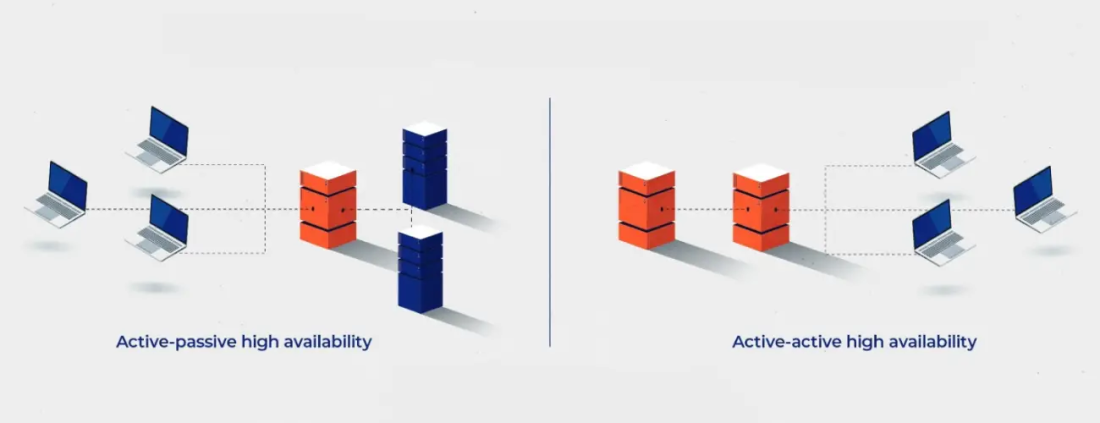
Архитектура: active-passive и active-active
Два фундаментальных подхода к построению ha cluster, и у каждого своя цена и своя логика. Выбор между ними — не технический вопрос, а бизнесовый: что для вас дороже, простое железо или гарантированная производительность в момент пиковой нагрузки?
| Параметр | Active-Passive | Active-Active |
|---|---|---|
| Использование ресурсов | Резервный узел простаивает | Все узлы под нагрузкой |
| Сложность настройки | Ниже | Выше (нужна синхронизация состояния) |
| Время failover | 1–10 сек | Почти мгновенно (нет переключения) |
| Типичный стек | Pacemaker + Corosync | HAProxy + Keepalived, Kubernetes |
| Стоимость | Платите за железо, которое "спит" | Эффективнее по железу |
Active-passive проще в реализации и надёжнее в предсказуемости: основной узел работает, резервный — ждёт. При падении основного Pacemaker поднимает сервисы на резервном за считанные секунды. Это классика для баз данных — PostgreSQL + Patroni, MySQL + MHA.
Active-active сложнее: все узлы одновременно принимают трафик, и вам нужно решить вопрос конфликтов записи, если речь о БД. Зато при отказе одного узла остальные просто берут его долю нагрузки — никакого "тёплого старта".
Три компонента, без которых HA не работает
Heartbeat — это пульс кластера. Узлы постоянно обмениваются сигналами: "я живой, я живой, я живой". Если сигнал пропадает дольше заданного таймаута — запускается процедура failover. В Corosync этот механизм реализован через кольцевой протокол Totem, который умеет переживать потерю одного из каналов связи.
Shared storage — общее хранилище данных, к которому получают доступ все узлы кластера. Ceph даёт вам распределённое блочное хранилище с репликацией на уровне объектов, GlusterFS — проще в развёртывании и хорошо работает для файловых хранилищ. Без этого компонента active-passive кластер либо бесполезен, либо превращается в дорогую игрушку.
Fencing (STONITH) — самый недооценённый компонент, который спасает от split-brain. Представьте: два узла потеряли связь друг с другом, но оба считают себя основными. Оба начинают писать в shared storage. Данные повреждены. STONITH (Shoot The Other Node In The Head) решает это радикально — изолирует "сомневающийся" узел через IPMI, iDRAC или аппаратный PDU, физически отключая его от питания или сети. Жёстко, но работает.
99.99% аптайм: что за этим стоит в цифрах
Красивый SLA в договоре — это одно. Реальное понимание метрик — другое. Когда продажники обещают клиенту "99.99% аптайма", редко кто в комнате понимает, что конкретно это означает для инфраструктуры и что случится, если эту цифру не выдержать. Вот что нужно контролировать и почему:
MTBF (Mean Time Between Failures) — среднее время между отказами. Чем выше, тем лучше. Для enterprise-оборудования производители заявляют MTBF в 100 000+ часов, но реальная эксплуатация — другая история, особенно если речь о дисках под интенсивной нагрузкой.
MTTR (Mean Time To Recovery) — среднее время восстановления. Вот тут HA-кластер и показывает себя: Pacemaker в правильно настроенной конфигурации укладывается в MTTR менее 10 секунд. Для сравнения — ручное восстановление даже опытным администратором редко занимает меньше 15–30 минут.
RTO и RPO — метрики для бизнеса, которые нужно обсуждать до настройки кластера, а не после первого инцидента. RTO (Recovery Time Objective) — сколько времени допустимо не работать. RPO (Recovery Point Objective) — сколько данных допустимо потерять. Для 99.99% RTO должен быть меньше минуты, RPO — в идеале нулевым (синхронная репликация) или близким к нулю. Синхронная репликация дороже асинхронной: она добавляет задержку к каждой записи, ожидая подтверждения от реплики, зато при failover потеря данных — ноль.
| Параметр | Цель для 99.99% | Инструмент |
|---|---|---|
| MTTR | < 10 секунд | Pacemaker |
| RTO | < 1 минуты | HAProxy |
| Минимум узлов | 3 (кворум) | Corosync |
| Простой в год | ≤ 52 минут | — |
| Простой в месяц | ≤ 4.38 минут | — |
Про кворум отдельно: почему минимум три узла? Два узла создают неразрешимую ситуацию при split-brain — каждый считает себя правым. Три узла дают возможность принять решение большинством голосов: 2 против 1, и кластер продолжает работу. Это же объясняет, почему etcd в Kubernetes и ZooKeeper в Kafka требуют нечётного числа узлов.
Практика: инструменты и мониторинг
На Linux основой большинства production HA-конфигураций остаётся связка Corosync + Pacemaker. Corosync обеспечивает групповую коммуникацию и кворум, Pacemaker управляет ресурсами кластера — знает, какие сервисы должны работать, где и в каком порядке запускаться при failover.
Для Proxmox VE HA встроен из коробки: GUI позволяет назначить виртуальные машины как HA-ресурсы, задать приоритеты и политики failover. Под капотом — тот же Corosync, но без необходимости ковыряться в конфигах вручную. Для небольших команд это существенная экономия времени при первоначальной настройке. Если платформа виртуализации ещё не выбрана, перед настройкой HA стоит изучить полный разбор популярных гипервизоров.
Балансировка нагрузки через HAProxy или Nginx добавляется поверх HA-кластера для распределения входящего трафика. HAProxy работает на L4/L7, умеет health checks и автоматически исключает упавший бэкенд из ротации быстрее, чем пользователь замечает ошибку. Keepalived добавляет к этому виртуальный IP — при отказе основного балансировщика VIP мигрирует на резервный узел за доли секунды. Связка HAProxy + Keepalived — де-факто стандарт для высоконагруженных сервисов без бюджета на enterprise load balancer.
Мониторинг такой конфигурации требует нескольких уровней:
- Zabbix или Prometheus — для метрик узлов: CPU, RAM, дисковая латентность, сетевые интерфейсы. В Zabbix есть готовые шаблоны для мониторинга Corosync и Pacemaker через агент; Prometheus с node_exporter закрывает базовые метрики, а с kube-state-metrics — состояние Kubernetes-кластера.
- Alertmanager — для эскалации алертов с учётом времени суток и ответственных. Без нормальной маршрутизации алертов HA-инфраструктура превращается в генератор тревожных SMS, которые все научились игнорировать.
- Специфичные метрики кластера — статус кворума, состояние ресурсов Pacemaker (crm_mon -1), задержка репликации в shared storage. Для Ceph ключевые метрики — ceph health, OSD latency и pool utilization; при деградации кластера до статуса WARN у вас есть время отреагировать до того, как он уйдёт в CRITICAL.
Предиктивный анализ через ELK Stack позволяет коррелировать события: если диск начинает давать ошибки SMART за неделю до отказа, а одновременно растёт латентность Ceph — это повод для превентивного обслуживания, а не для ночного аварийного восстановления. Kibana с правильно настроенными дашбордами покажет паттерн раньше, чем он станет инцидентом.
Автоматизация развёртывания через Ansible снижает риск человеческой ошибки при настройке новых узлов и гарантирует идентичность конфигурации во всём кластере. Drift конфигурации — одна из частых причин "странного поведения" кластера через год после запуска. Playbook на добавление нового узла в Corosync-кластер занимает 200 строк YAML, но выполняется воспроизводимо каждый раз — в отличие от ручной настройки по инструкции, которую последний раз обновляли полтора года назад.
Энергоэффективность в плотных HA-кластерах — отдельная тема. При плотности 20–30 кВт на стойку воздушное охлаждение перестаёт справляться без значительных затрат на инфраструктуру серверного помещения. Liquid cooling — либо rear-door heat exchangers, либо direct liquid cooling — позволяет держать такую плотность без перегрева и без перерасхода на кондиционирование. Для Tier III и Tier IV дата-центров это уже не экзотика, а стандарт.
TCO и аргументы для руководства
HA-кластер стоит денег — дополнительное железо, лицензии (если Red Hat HA Add-On), время на настройку. Но посчитайте иначе.
Час простоя интернет-магазина с оборотом 5 млн рублей в день — это примерно 210 000 рублей прямых потерь. Плюс репутационный ущерб, штрафы по SLA с партнёрами, стоимость работы команды на восстановление. Если HA-кластер предотвращает два таких инцидента в год, он окупается даже при стоимости внедрения в несколько миллионов рублей.
Исследования Gartner и IDC стабильно показывают: компании, внедрившие HA-инфраструктуру, снижают совокупные потери от простоев на 30–50% в первые два года эксплуатации. Это не магия — это просто математика MTTR.
Отдельный аргумент для финансового директора — страховая логика. HA-кластер работает как страховка: вы платите регулярный "взнос" в виде стоимости резервных узлов, чтобы не платить разово и непредсказуемо при каждом серьёзном сбое. Разница в том, что эта страховка ещё и улучшает производительность в штатном режиме.
При выборе между vendor-решениями:
- Red Hat Enterprise Linux HA Add-On — зрелая экосистема, официальная поддержка, хорошо интегрируется с RHEL-стеком. Стоимость лицензии окупается, если у вас критичные рабочие нагрузки и нужен контракт поддержки с SLA от вендора.
- VMware vSphere HA — для тех, кто уже на VMware; vMotion добавляет живую миграцию VM без прерывания, DRS балансирует нагрузку автоматически. Дорого, но хорошо интегрировано.
- Proxmox VE HA — открытый стек, без лицензионных выплат, достаточен для большинства on-premise сценариев. Community edition не означает "нет поддержки" — Proxmox предлагает коммерческую подписку с SLA, если нужно.
Следующий уровень: Kubernetes и geo-replication
Контейнерные рабочие нагрузки меняют правила игры. Kubernetes с правильно настроенными Deployment и PodDisruptionBudget даёт HA для приложений без отдельного уровня кластеризации серверов — планировщик сам перераспределяет поды при отказе узла. PodDisruptionBudget гарантирует, что при rolling update или дренировании узла одновременно не упадут все реплики: если у вас три пода и minAvailable=2, обновление пойдёт по одному поду за раз. Но это не отменяет необходимость HA для самого control plane Kubernetes: три мастер-узла, etcd с репликацией (etcd крайне чувствителен к дисковой латентности — ставьте его на NVMe), внешний балансировщик для kube-apiserver.
Geo-replication выводит отказоустойчивость на уровень катастрофоустойчивости (DRP). Синхронная репликация между дата-центрами в пределах одного города (задержка < 5 мс) даёт RPO близкий к нулю. Асинхронная между регионами — компромисс между RPO и стоимостью канала: задержка 50–100 мс означает, что при мгновенной катастрофе вы потеряете несколько секунд данных, но сервис поднимется в резервной локации по заранее отработанному плану.
Безопасность в HA-кластерах часто оказывается afterthought — и зря. Трафик между узлами кластера нужно шифровать (TLS для Corosync, mTLS в Kubernetes через cert-manager или Istio), heartbeat-сеть изолировать в отдельный VLAN, а доступ к IPMI/iDRAC закрывать от production-сети — всё это базовые требования при подготовке серверной инфраструктуры к ИБ-аудиту. Если атакующий получает доступ к BMC-интерфейсу — он может выключить STONITH в нужный момент и устроить split-brain намеренно. Zero-trust здесь применима не только к приложениям, но и к самой инфраструктуре управления.
Высокая доступность — это не конечное состояние, которое "настроили и забыли". Это дисциплина: регулярные тесты failover в боевой среде (да, намеренные), chaos engineering по методологии Netflix, обновление узлов по rolling-стратегии без окна обслуживания. Кластер, который не тестировали в условиях реального сбоя, — это дорогое оборудование с иллюзией надёжности. Первый раз, когда failover отрабатывает по-настоящему, не должен быть сюрпризом.







