Клиент-серверное взаимодействие
- Что это и как работает
- Преимущества архитектуры
- Минусы архитектуры
- Что тестировать
- Зачем нужен клиент
- Зачем нужен сервер
- Зачем нужна база
- Взаимодействие клиента и сервера
- Сеть с выделенным сервером
- Как работает веб: клиент-серверная модель
- Модель клиент-сервер
- Базовая конфигурация веб-приложения
- Как масштабировать простое веб-приложение
- Типы клиент-серверной архитектуры
- 1-Tier (однозвенная)
- 2-Tier (двухзвенная)
- 3-Tier (трёхзвенная)
- N-Tier (многозвенная)
- Практические применения
Клиент-серверная архитектура — основа почти любого сетевого приложения. Браузер, мобильный клиент, IoT-датчик — все они шлют запросы серверу и получают ответы. Схема простая, но нюансов хватает: протоколы, балансировка, отказоустойчивость, безопасность. Разберём, как это устроено и где грабли.
Что это и как работает
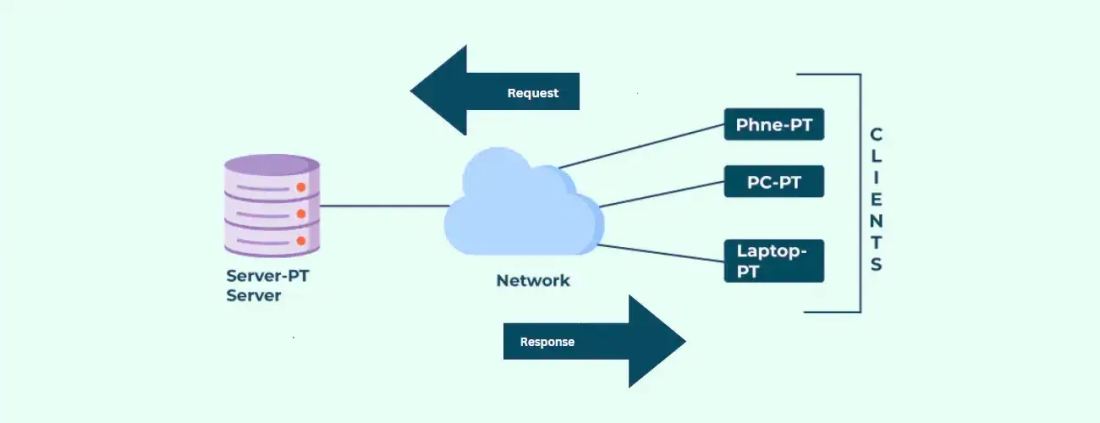
Клиент отправляет запрос — сервер возвращает ответ. Всё взаимодействие сводится к этому циклу. Общение идёт по определённому протоколу: HTTP/HTTPS для веба, gRPC для микросервисов, MQTT для IoT-устройств — зависит от задачи.
Клиент и сервер не обязательно живут на разных машинах. Разработчик запускает и фронтенд, и бэкенд на одном ноутбуке — это тоже клиент-серверное взаимодействие. А в продакшене между ними может быть океан, CDN и пара балансировщиков.
Типичный пример: вы вбиваете URL в браузере — он формирует HTTP-запрос, сервер отдаёт HTML-документ, браузер его рендерит. Но та же схема работает в почтовых клиентах, мессенджерах, стриминговых сервисах и любом SaaS-приложении.
Преимущества архитектуры
Главный плюс — разделение ответственности. Клиент занимается отрисовкой интерфейса, сервер тянет тяжёлую логику, хранение и вычисления. Каждая сторона делает то, что умеет лучше.
Что это даёт на практике:
- Централизация. Данные и бизнес-логика в одном месте — проще обновлять, бэкапить и защищать.
- Кроссплатформенность. Клиентом может быть браузер, мобильное приложение, терминал — серверу без разницы, кто шлёт запрос, если протокол соблюдён.
- Удалённый доступ. Пользователь работает из любой точки, где есть сеть. Для распределённых команд это базовое требование.
- Управление нагрузкой. Серверную часть можно масштабировать отдельно от клиентской — добавить реплики, настроить кэш, подключить балансировщик.
- Единые политики безопасности. TLS, аутентификация, авторизация, аудит — всё настраивается централизованно.
Минусы архитектуры
Если сервер лёг — лежат все клиенты. Это главная боль: единая точка отказа (single point of failure). Решается резервированием и кластеризацией, но это усложняет инфраструктуру и бюджет.
Другие слабые места:
- Зависимость от сети. Нет соединения — нет сервиса. Offline-first подход частично спасает, но подходит не всем приложениям.
- Стоимость масштабирования. Добавить мощности серверу (вертикально) или серверов (горизонтально) — это деньги, время и инженерные часы.
- Сетевые задержки. При высоком RPS (requests per second) узким местом становится сеть, а не процессор. Latency растёт, пользователи страдают.
- Поверхность атаки. Сервер доступен из сети — значит, доступен и для атакующих. DDoS, SQL-инъекции, брутфорс — стандартный набор угроз.
- Совместимость версий. API меняется, клиенты обновляются не одновременно. Версионирование API — отдельная головная боль.
Что тестировать
Тестирование клиент-серверного взаимодействия — это не просто «открыл страницу, работает, ок». Есть четыре направления, которые нужно закрыть:
Функциональность. Клиент подключается, отправляет запросы, получает корректные ответы. Проверяем все эндпоинты, граничные значения, обработку ошибок (4xx, 5xx).
Нагрузка и стресс. Сервер должен держать расчётный RPS и не падать при пиковых всплесках. Инструменты — k6, Locust, Apache JMeter. Тестируем при штатной нагрузке и при кратном превышении.
Сетевые условия. Высокий latency, потеря пакетов, узкий канал — эмулируем через tc (traffic control) в Linux или через специализированные прокси. Приложение не должно зависать или терять данные.
Безопасность. Пентест: проверка аутентификации, авторизации, защиты от инъекций, корректности TLS-конфигурации. OWASP Top 10 — минимальный чеклист.
Зачем нужен клиент
Клиент — это прослойка между пользователем и сервером. Он берёт на себя отрисовку интерфейса, обработку действий (клики, ввод, жесты) и формирование запросов к серверу. Пользователь нажимает кнопку «Отправить» — клиент упаковывает данные в HTTP-запрос и отправляет на бэкенд.
Толстый клиент (desktop-приложение, мобильное приложение) берёт на себя часть логики и может работать офлайн. Тонкий клиент (браузер) зависит от сервера почти полностью. Выбор между ними — компромисс между автономностью и простотой поддержки.
Зачем нужен сервер
Сервер — это рабочая лошадка архитектуры. Он хранит данные, выполняет бизнес-логику, обрабатывает запросы и отдаёт ответы. Физически — одна или несколько машин в стойке, виртуальные машины под управлением гипервизора, bare-metal в ЦОД. Вычисления, которые невозможны или нецелесообразны на стороне клиента (работа с большими массивами данных, ML-инференс, транзакционная логика), ложатся на серверную часть.
Пример: веб-сервер принимает HTTP-запрос, обращается к базе данных, формирует ответ и отправляет его клиенту. Под капотом может быть Nginx как reverse proxy, application server на Go или Python, PostgreSQL как хранилище. Подобрать подходящее железо под конкретную задачу — от одного 1U-сервера до многоузлового кластера — поможет каталог серверов.
Зачем нужна база
База данных — это persistent-слой. Без неё сервер забудет всё после перезагрузки. БД хранит пользователей, транзакции, контент, логи — всё, что должно пережить рестарт процесса.
Помимо хранения, СУБД обеспечивает:
- Целостность данных — через транзакции (ACID), constraint'ы и foreign key.
- Конкурентный доступ — тысячи клиентов читают и пишут одновременно, а база разруливает блокировки и изоляцию.
- Производительность запросов — индексы, партиционирование, materialized views.
- Безопасность — гранулярные права доступа, шифрование at rest и in transit.
Выбор СУБД зависит от задачи: PostgreSQL для сложных реляционных данных, Redis для кэша и сессий, MongoDB для документо-ориентированного хранения, ClickHouse для аналитики.
Взаимодействие клиента и сервера
Цикл запрос-ответ выглядит так:
- Клиент формирует запрос (GET, POST, PUT, DELETE — если говорим про REST) и отправляет его на сервер.
- Сервер парсит запрос, валидирует параметры, проверяет авторизацию.
- Если нужны данные — идёт обращение к БД или кэшу.
- Сервер собирает ответ (JSON, HTML, бинарные данные) и отправляет клиенту с соответствующим HTTP-статусом.
- Клиент получает ответ, обрабатывает его и обновляет интерфейс.
Помимо классического request-response, существуют асинхронные паттерны: WebSocket для двусторонней связи в реальном времени, Server-Sent Events для потоковых обновлений, gRPC streaming для межсервисной коммуникации.
Сеть с выделенным сервером
Выделенный (dedicated) сервер — это физическая машина, целиком отданная под задачу клиента. Никаких «шумных соседей», как в shared-хостинге или мультитенантных виртуалках.
Зачем это нужно:
- Предсказуемая производительность. Все ресурсы — CPU, RAM, диск, сетевой канал — принадлежат вашему приложению. Никто не отъест IOPS в соседней VM.
- Гибкость конфигурации. Полный root-доступ, выбор ОС, кастомные сетевые настройки, возможность поставить хоть FreeBSD, хоть собственное ядро Linux.
- Безопасность. Физическая изоляция = меньше векторов атак через гипервизор. Для проектов с жёсткими требованиями к compliance (PCI DSS, 152-ФЗ) — часто единственный вариант, при этом само размещение оборудования должно соответствовать требованиям к серверным помещениям.
- Масштабирование. Несколько dedicated-серверов легко объединяются в кластер. Kubernetes, Docker Swarm, Nomad — на выбор.
Для высоконагруженных проектов (e-commerce с пиковыми распродажами, игровые серверы, платформы видеостриминга) выделенный сервер — базовый строительный блок инфраструктуры.

Как работает веб: клиент-серверная модель
Веб-приложение — частный случай клиент-серверной архитектуры. Браузер выступает клиентом, а за кулисами работает стек из веб-сервера, application server и базы данных.
Цикл взаимодействия:
- Пользователь вводит URL — браузер резолвит домен через DNS и устанавливает TCP/TLS-соединение.
- Браузер отправляет HTTP-запрос (GET /page HTTP/2, заголовки, cookies).
- Веб-сервер (Nginx, Caddy) принимает запрос и проксирует его на application server.
- Application server обрабатывает логику, обращается к БД/кэшу, формирует ответ.
- Ответ (HTML + заголовки + статус-код) уходит обратно браузеру.
- Браузер парсит HTML, подгружает CSS, JS, картинки (часть из CDN), рендерит страницу.
- JS-код на клиенте может инициировать дополнительные AJAX/fetch-запросы без перезагрузки страницы — это основа SPA (Single Page Application).
Модель клиент-сервер
Любое устройство с сетевым стеком может быть клиентом: ПК, смартфон, умный холодильник, промышленный контроллер. Клиент формирует запрос, отправляет его серверу и обрабатывает ответ. Серверная часть развёрнута на серверном оборудовании — от одного стоечного сервера до распределённого кластера в нескольких дата-центрах.
Базовая конфигурация веб-приложения
Минимальный набор компонентов для запуска:
- Frontend (клиент). Браузер + SPA-фреймворк (React, Vue, Svelte) или серверный рендеринг (Next.js, Nuxt). Отвечает за UI и взаимодействие с пользователем.
- Backend (сервер). Веб-сервер (Nginx, Caddy) + application server (Node.js, Go, Python/Django, Java/Spring). Обрабатывает бизнес-логику, валидацию, авторизацию.
- База данных. PostgreSQL, MySQL, MongoDB — зависит от типа данных и нагрузки.
- Сетевой слой. HTTPS (TLS 1.3), DNS, CDN для статики. Если приложение за firewall — настройка правил iptables/nftables.
- Безопасность и мониторинг. OAuth 2.0 / JWT для аутентификации, WAF для защиты, Prometheus + Grafana для метрик, ELK-стек или Loki для логов.
Как масштабировать простое веб-приложение
Масштабирование начинается не с покупки новых серверов, а с профилирования. Найдите узкое место — CPU, память, диск, сеть, медленные SQL-запросы — и только потом выбирайте стратегию.
Вертикальное масштабирование (scale up). Добавить RAM, заменить CPU, поставить NVMe вместо SATA SSD. Просто, но имеет потолок — в один сервер бесконечно ресурсов не запихнёшь. Чтобы вертикальное масштабирование дало максимум, важно изначально выбрать подходящий сервер для офисных задач с запасом по апгрейду.
Горизонтальное масштабирование (scale out). Запустить несколько экземпляров приложения за балансировщиком (HAProxy, Nginx, Envoy). Требует stateless-архитектуры — состояние сессий выносится в Redis или другое внешнее хранилище.
Кэширование. Redis/Memcached для горячих данных, CDN (Cloudflare, Selectel CDN, Bunny) для статики. Грамотный кэш снижает нагрузку на БД в разы.
Оптимизация базы данных. Индексы, EXPLAIN ANALYZE для запросов, read-реплики, партиционирование таблиц. Если реляционная БД не справляется — возможно, часть данных стоит вынести в специализированное хранилище.
Микросервисы. Разделить монолит на сервисы, каждый масштабируется независимо. Но сначала убедитесь, что монолит действительно упёрся в потолок — распилить приложение на куски не бесплатно с точки зрения инженерных усилий.
Автоскейлинг. В облаке (или в Kubernetes на bare-metal) — Horizontal Pod Autoscaler реагирует на метрики и добавляет/убирает инстансы. Для проектов с непредсказуемой нагрузкой — мастхэв.
Типы клиент-серверной архитектуры
Архитектуру делят по количеству логических уровней (tier). Каждый уровень — отдельная зона ответственности, часто запущенная на отдельном железе.
1-Tier (однозвенная)
Клиент и сервер в одном процессе. Классика — десктопное приложение с встроенной SQLite. Всё работает локально, нет сетевого взаимодействия. Годится для прототипов и утилит, но масштабировать нечего.
2-Tier (двухзвенная)
Клиент (толстый) общается напрямую с базой данных. Бизнес-логика размазана между клиентом и хранимыми процедурами в БД. Такой подход до сих пор встречается в корпоративных legacy-системах на Delphi или 1С. Проблема — трудно масштабировать, обновления клиента нужно раскатывать на каждую рабочую станцию.
3-Tier (трёхзвенная)
Стандарт для веб-приложений: клиент (браузер) → application server (бизнес-логика) → база данных. Каждый слой масштабируется независимо. Фронтенд общается с бэкендом через API, бэкенд — с БД. Чистое разделение ответственности.
N-Tier (многозвенная)
Расширение трёхзвенной модели: добавляются слои кэширования, message broker (Kafka, RabbitMQ), API gateway, сервисы авторизации, поисковые движки (Elasticsearch). Микросервисная архитектура — типичный пример N-tier, где каждый сервис может иметь собственную БД и коммуникацию через очереди сообщений.
Практические применения
Клиент-серверная архитектура — это не абстракция из учебника. Пара реальных сценариев:
SaaS-платформа. Пользователь работает в браузере (клиент), вся бизнес-логика и данные — на серверах провайдера. CRM, таск-трекеры, бухгалтерия — всё это клиент-сервер с тонким клиентом.
Мультиплеерный игровой сервер. Игровые клиенты отправляют действия игроков, сервер синхронизирует состояние мира и рассылает обновления. Требования к latency — жёсткие, протоколы часто UDP-based.
IoT и умный дом. Датчики и контроллеры (клиенты) передают телеметрию на сервер через MQTT или CoAP. Сервер агрегирует данные, принимает решения, отправляет команды актуаторам. Даже термостат в квартире — это клиент-серверное взаимодействие.
API-шлюз для мобильного приложения. Мобильное приложение обращается к единому API gateway, а тот маршрутизирует запросы к нужным микросервисам. Backend for Frontend (BFF) паттерн — развитие этой идеи, где для каждого типа клиента создаётся свой бэкенд-слой.







